Share a Data Warehouse
Demo Video

Data Sharing blog on AWS Blogs and associated video on AWS YouTube channel
Before You Begin
You must run the main site CloudFormation template and capture the following outputs from the Outputs tab:
- VpcId
- SecurityGroup
- RedshiftClusterSubnetGroup
- SubnetAPublic
- EC2DeveloperPassword
- EC2HostName
The main template spins up DC2 Clusters by default. The Data Sharing feature requires a cluster with an RA3 node type. Re-deploy your template and switch the node type to RA3 and spin up a second cluster manually.
As an alternative, click the button below to launch two additional clusters; a producer, and a consumer cluster. Enter the above captured outputs as inputs to this template.

After this template has run, capture the following output values from the Outputs tab in Cloud Formation:
- ProducerEndpoint
- ProducerUserName
- ProducerPassword
- ProducerPort
- ProducerDatabase
- ConsumerEndpoint
- ConsumerUserName
- ConsumerPassword
- ConsumerPort
- ConsumerDatabase
- ProducerNamespace (not available as a Cloud Formation output yet, please obtain from the Redshift Console)
- ConsumerNamespace (not available as a Cloud Formation output yet, please obtain from the Redshift Console)
Client Tool
While this restriction may change soon, as of March 2021, Redshift cross-account sharing is not generally available so there are two main items to be aware of 1\ your Redshift cluster CANNOT be publicly accessible for data sharing 2\ your SQL client must be on the same VPC, and Subnet to query the cluster. For this reason you must use either the AWS Console based Query Editor or the SQL Workbench/J on the EC2 that we provide in the Cloud Formation template that you ran for this site.
Data Ingestion
After the Cloud Formation Template has run successfully you will have two RA3 instances, one will act as the producer of data that shares data with the consumer cluster. We need to create some data on this producer that can be shared during the demo. You can and should run this before your customer-facing demo as it’s just a simple data load.
Run the following query in the Producer Cluster using either Query Editor on the AWS Console or the the SQL Workbench/J on the EC2 instance:
-- Run in Producer Cluster
-- Create databases for finance and operations examples
CREATE DATABASE finance_db;
CREATE DATABASE operations_db;
Now disconnect and re-connect to the Producer Cluster but this time connect to the finance_db database:
-- Switch finance_db database
-- Might have to logout and login
CREATE SCHEMA finance_schema;
CREATE TABLE IF NOT EXISTS finance_schema.customer (
c_custid int8 not null , c_name varchar(25) not null, c_region varchar(40) not null, Primary Key(c_custid)
) diststyle ALL sortkey(c_custid);
CREATE TABLE IF NOT EXISTS finance_schema.sales (
s_orderid int8 not null, s_custid int8 not null, s_totalprice numeric(12,2) not null, s_orderdate date not null, Primary Key(s_orderid)
) distkey(s_orderid) sortkey(s_orderdate, s_orderid);
INSERT INTO finance_schema.customer VALUES (1, 'Finance Customer 1', 'NorthEast'),(2, 'Finance Customer 2', 'SouthEast');
INSERT INTO finance_schema.sales VALUES (1, 1, 2434.33, '2020-11-21'),(2, 2, 54.90, '2020-5-5'),(3, 2, 9678.99, '2020-3-8');
Now disconnect and re-connect to the Producer Cluster but this time connect to the operations_db database:
-- Switch to operations_db on the Producer cluster
-- May have to logout and login
CREATE SCHEMA operations_schema;
CREATE TABLE IF NOT EXISTS operations_schema.customer (
c_custid int8 not null, c_name varchar(25) not null, c_region varchar(40) not null, Primary Key(c_custid)
) diststyle ALL sortkey(c_custid);
CREATE TABLE IF NOT EXISTS operations_schema.sales (
s_orderid int8 not null, s_custid int8 not null, s_totalprice numeric(12,2) not null, s_orderdate date not null, Primary Key(s_orderid)
) distkey(s_orderid) sortkey(s_orderdate, s_orderid) ;
INSERT INTO operations_schema.customer VALUES (1, 'Customer 1', 'NorthEast'), (2, 'Customer 2', 'SouthEast');
INSERT INTO operations_schema.sales VALUES (1, 1, 2434.33, '2020-11-21'), (2, 2, 54.90, '2020-5-5'), (3, 2, 9678.99, '2020-3-8');
Challenge
Red Imports LLC has been granting access to different tables in the main enterprise Data Warehouse to Marketing, Operations, and the Finance departments. Marketing only wants access to certain customers data, Operations wants access to only one set of related tables (i.e schema), and Finance wants access to all customer data. Each have different needs and Miguel needs to find a way to provide each department access without impacting the enterprise Data Warehouse performance significantly. Miguel also wants to enable each department to manage their own performance needs because they have spiky workloads at varying times of the year, quarters and months of the year. Miguel has also been informed that due to recent changes in accounting there is an effort to pass usage charges to each department. To solve this challenge, Miguel must:
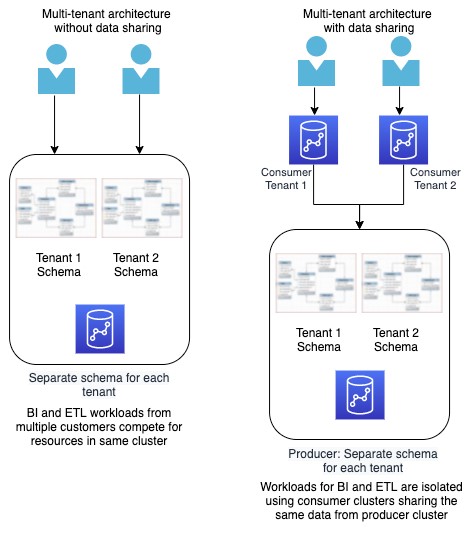
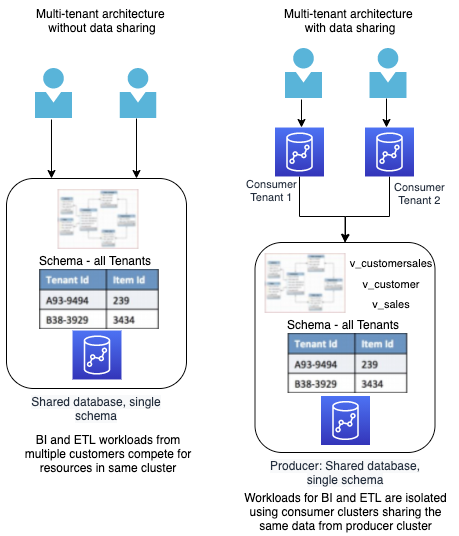
We are using only one consumer cluster for Finance, Operations, and Marketing for this demo. In this case, the clusters are in the same account and same VPC, this can be expanded into multiple VPCs and Accounts when cross-account data sharing goes GA. Here is what the architecture for this demo looks like:
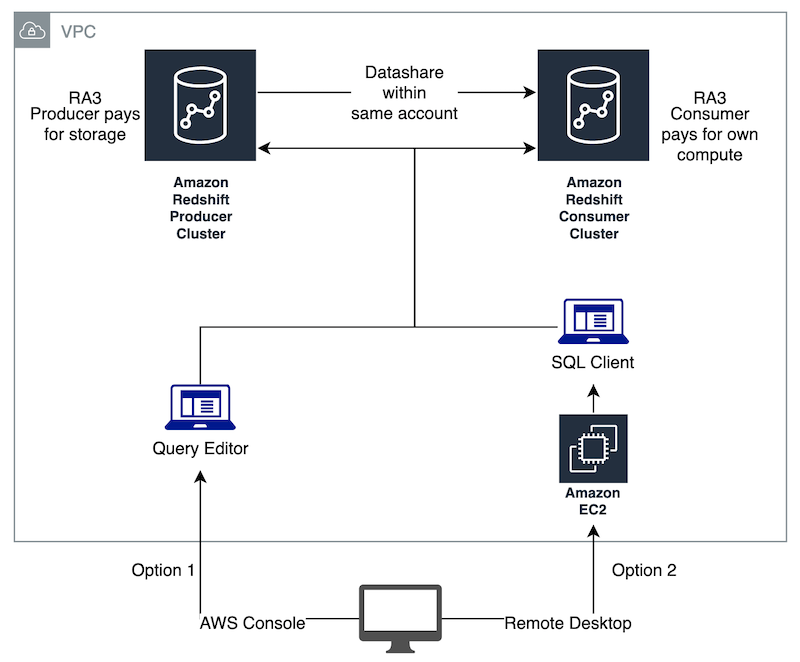
Share a database with Finance
| Say | Do | Show |
|---|---|---|
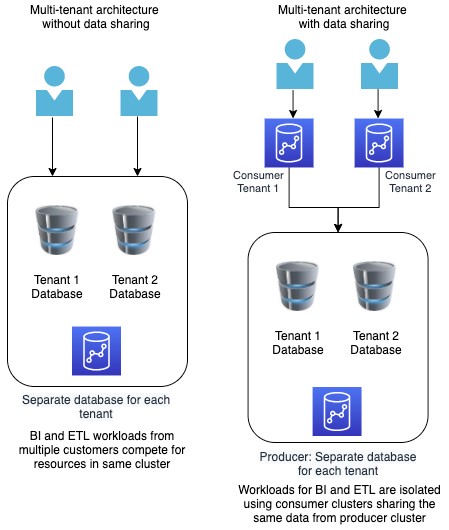
| Finance doesn’t want to be limited in their access to specific customers or accounts and need to conduct analysis on the whole data set. Miguel will utilize an architecture pattern that lets him share a whole database with them. | Show the customer the architecture diagram and explain that this architecture pattern is known as the Silo model. The name comes from a multi-tenant model where there is a database for every tenant and the whole database is shared with the appropriate tenant. In our demo, we are sharing the whole database with Finance which is the Silo model pattern. |
|
|
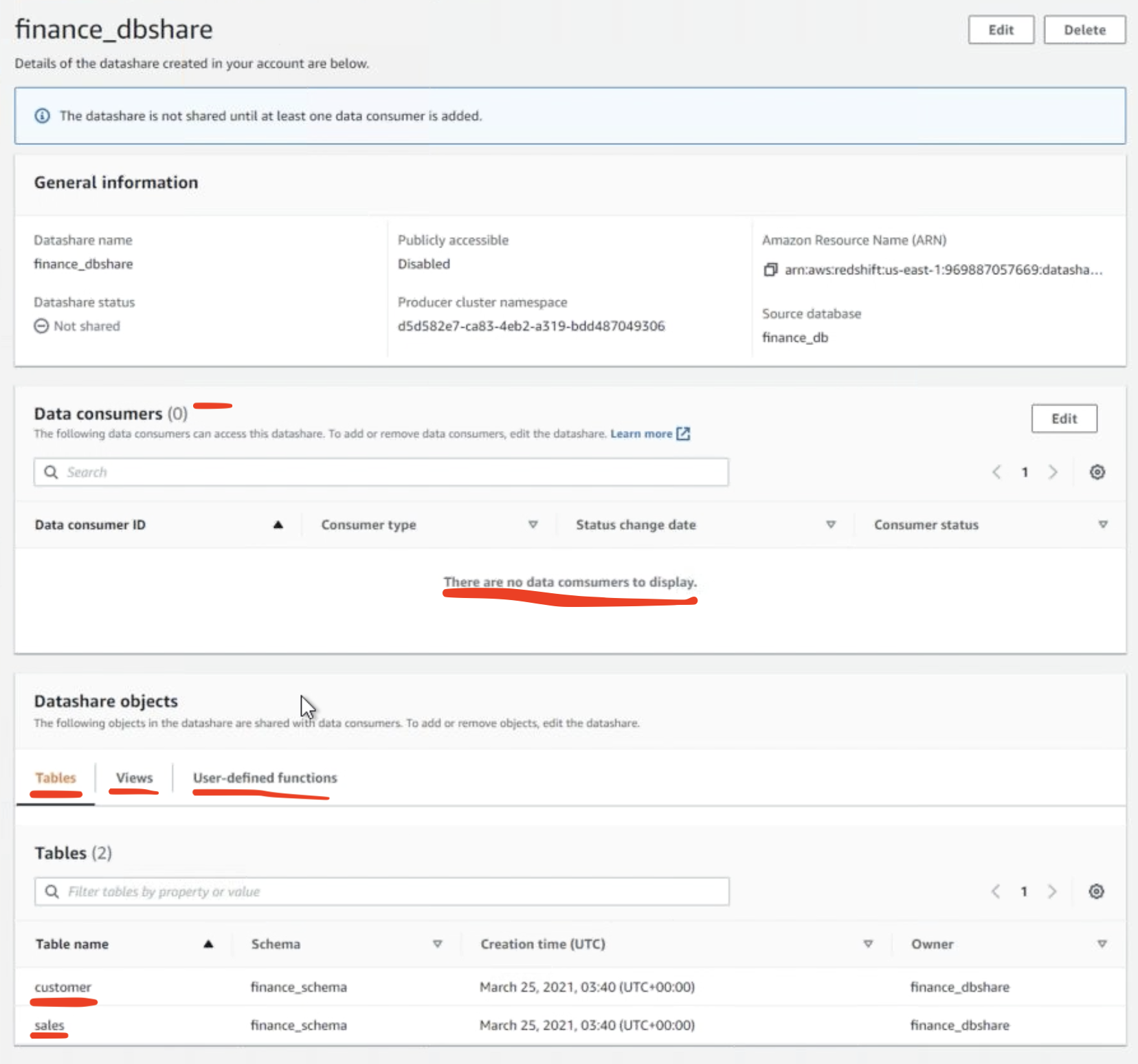
Miguel identifies the name of the database to be shared with Finance and creates a data share for them. He will need to add schemas and all the tables inside the schema to the data share so they can access all the data in the database. |
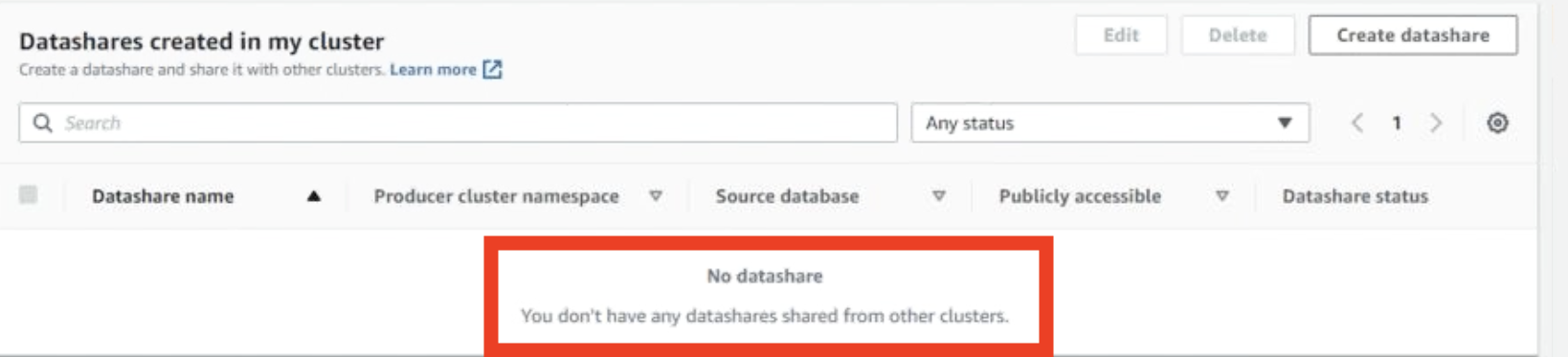
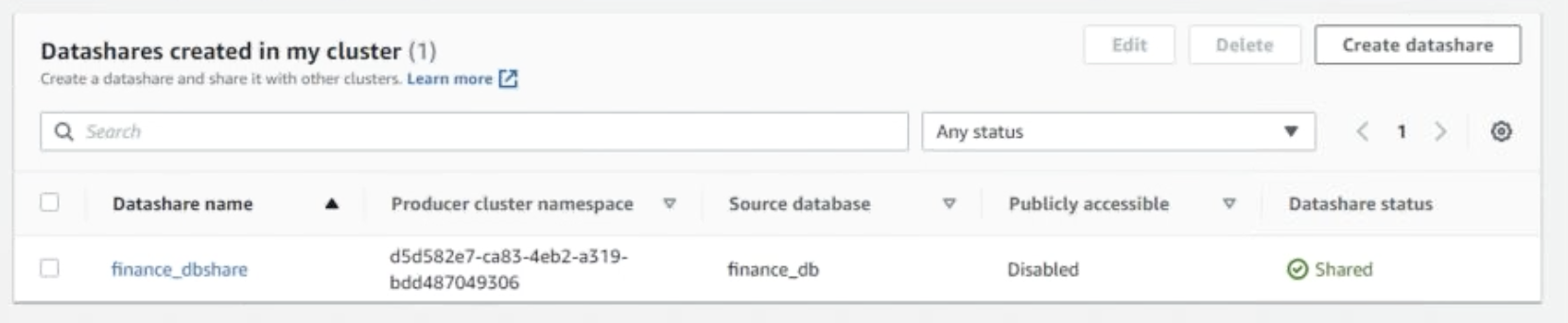
Login to the AWS Console and navigate to the producer cluster. In the Data Shares tab, there is a section named Datashares Created in my cluster, show that there is no Data Share for Finance yet.
Miguel logs into the Producer Cluster via SQL Workbench/J on the EC2 instance and executes the following SQL commands in the Refresh Click on |

|
|
Miguel now has a datashare that’s ready to be shared with finance. His counterpart in Frank from Finance has provided the namespace of the Finance Redshift cluster. Miguel will use this information to grant Frank’s Finance cluster access to this datashare. While we are using the cluster’s unique namespace here to grant access, when cross-account data sharing becomes available this step can also be accomplished by sharing using the account numbers. e.g. GRANT USAGE ON DATASHARE finance_dbshare TO ACCOUNT ‘«AWS-Account»’; |
Execute the following SQL command on the producer cluster: Navigate to the consumer cluster on AWS Console. In the |

|
|
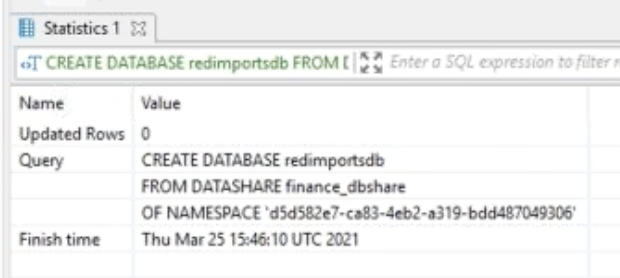
Miguel asks Frank to verify that Finance cluster is able to see the new data that has just been shared. Frank logins in to verify this but he must first create a database from the share. |
Login to the Consumer Cluster and execute the following SQL command in SQL Workbench/J:
|
|
|
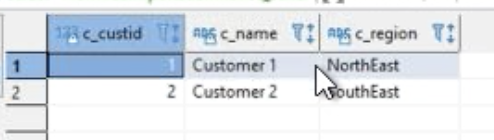
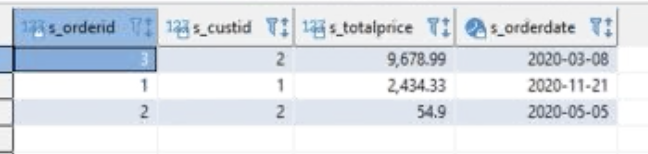
Frank now tests to make sure queries return results. |
Execute the following query and check that you see data returned from the producer cluster:
|
|
|
OPTIONAL STEP: Frank can also create an external schema pointing to the schema in the database of the producer cluster. This enables query of shared tables using a two-part notation. |
Execute the following query and check that you see data returned from the producer cluster: |
|
Share a schema with Operations
| Say | Do | Show |
|---|---|---|
| Operations only care about one schema in the enterprise Data Warehouse and don’t really need the other datasets. Miguel will utilize an architecture pattern that lets him share a whole schema with them. | Show the customer the architecture diagram and explain that this architecture pattern is known as the Bridge model. The name comes from a multi-tenant model where there is a schema for every tenant and the whole schema is shared with the appropriate tenant. In our demo, we are sharing the whole schema with Operations which is the Bridge model pattern. |
|
|
Miguel knows that the Operations department is only looking for data that is in one Schema on the enterprise Data Warehouse. Miguel has to share this data with Oksana from Operations so that her users can begin consuming the data. |
In the Using the EC2 instance you are already logged in to, execute the following query in the SQL Workbench/J producer cluster (replace the tag before execution and make sure you are running this query in the In the At any point, if you want to revoke access to use the data share, you can use the REVOKE USAGE command e.g. REVOKE USAGE ON DATASHARE operationsshare FROM NAMESPACE ‘«ConsumerNamespace»’ |
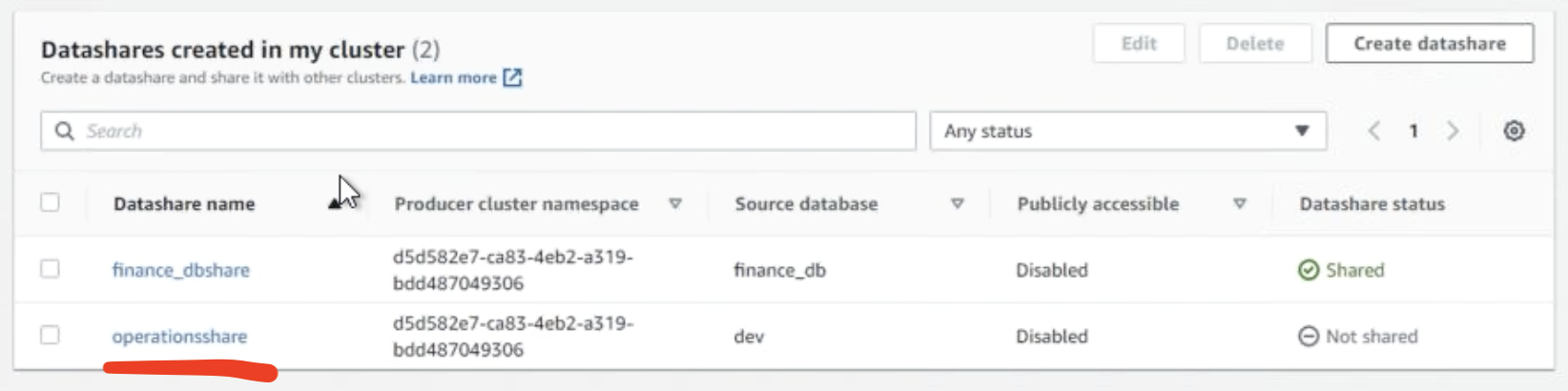
|
|
Miguel verifies that his data sharing queries ran successfully and the data share is live and ready. |
Show the customer that you can do what we did in the console in the previous sub-section for Finance can also be done using SQL statements.
Execute the following queries in the producer cluster: |

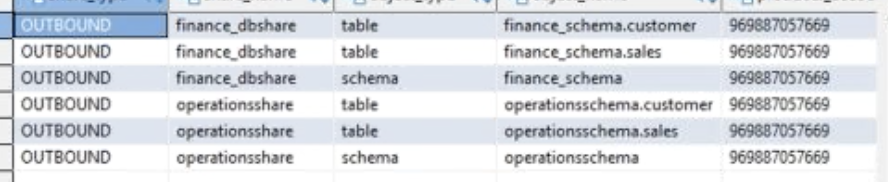

|
|
Miguel asks Oksana to verify that the Operations cluster is able to see and use the freshly shared data at the schema level. |
On the same SQL Workbench/J client, connect to the Consumer cluster and execute the following query: |


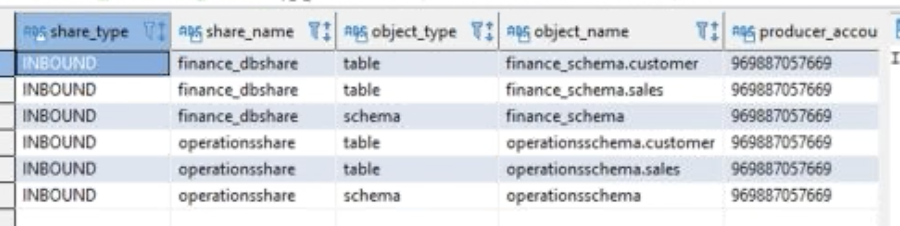
|
|
Oksana can see the data shares, now she needs to set it up so her users can execute queries against this data share just like their other tables. We will create a separate database for this step but you can just add it as a schema or external schema as well. |
Execute the following query in SQL Workbench/J:
|
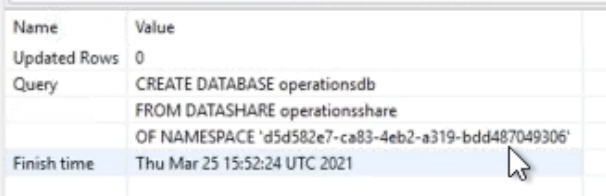
|
|
Oksana will switch over to the database she just created and test if she see data from the enterprise cluster there. |
Switch to the operations_db database in your SQL Client and execute the following query:
|
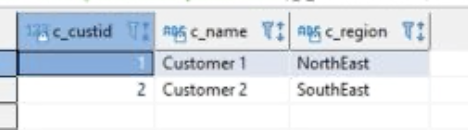
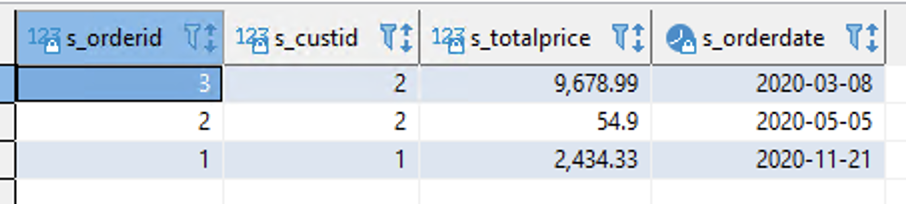
|
|
OPTIONAL: Oksana wants to provide restricted access to the specific schemas for selected users, when multiple schemas are shared from the producer cluster. This requires that she use the external schema approach. It also enables a two-part notation for her users’ SQL commands. |
Execute the following on the Consumer Cluster:
|
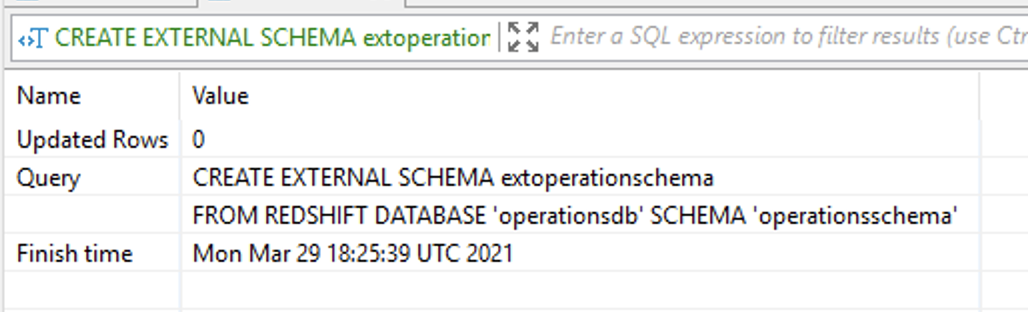
|
|
OPTIONAL Oksana executes a query to test that the external schema is fetching data from the producer cluster With the external schema setup, you can grant and revoke access to users or groups just like other Redshift schemas, databases, tables and views e.g. GRANT USAGE ON DATABASE ‘opsdb’ TO someuser; GRANT USAGE ON SCHEMA opsschema TO GROUP somegroup; |
Execute the following on the Consumer Cluster:
|
|
Share specific tables with Marketing
| Say | Do | Show |
|---|---|---|
| Marketing is looking for access to certain customer that based on some demographics and other criteria that they have determined targets the optimal group for marketing material. Miguel will utilize an architecture pattern that lets him share a set of tables with Marketing. |
Show the customer the architecture diagram and explain that this architecture pattern is known as the Pool model. The name comes from a multi-tenant model where the database is shared (pooled) between tenants and only appropriate data is shared with the appropriate tenant. In our demo, we are sharing a few tables with Marketing which is the Pool model pattern.
The Pool model utilizes Views generated by using the cluster namespace, a unique identifier for consumer clusters. This means that if a cluster identifier i.e. namespace value changes then the consumer will see no data until the View is updated to match the new namespace. |
|
|
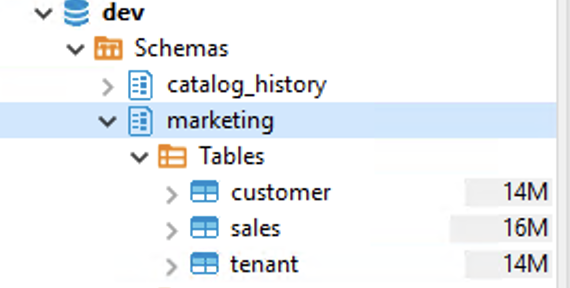
Miguel needs to build the basic data structures needed to determine which department can access what tables and data. He takes this approach to make sure he has the structures in place in case other departments want access to specific data in the future as well. We are going to create tables and add data to them but in an alternate scenario you could add columns to existing data as well. |
Using the EC2 instance you are already logged in to, execute the following query in the SQL Workbench/J producer cluster:
|
|
|
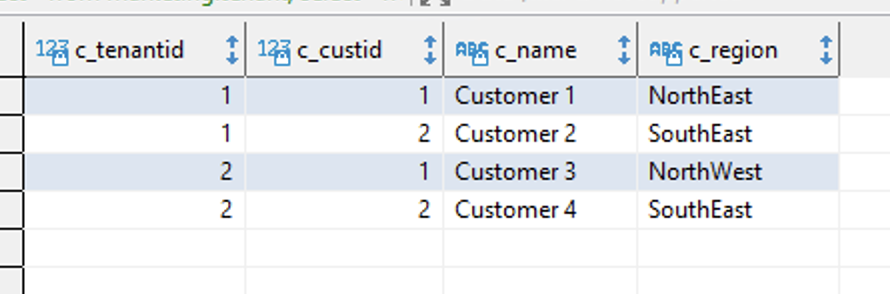
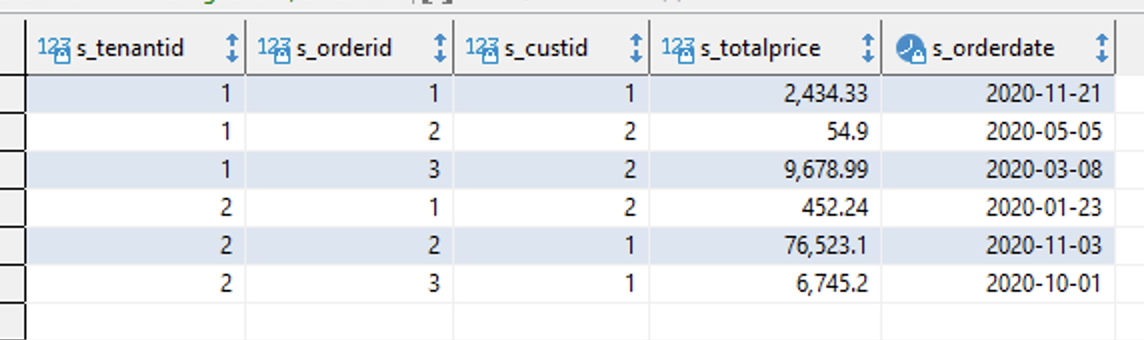
Miguel updates the new data structures with appropriate data for Marketing use. We are entering a fictitious futureTenant here so you can show the customer that Marketing only sees data ear-marked for marketing and not the other tenant’s data. |
Execute the following query in the SQL Workbench/J producer cluster: |
Point out that there are four total customers and only customer 1 and 2 are linked to Operations tenancy. 
|
|
Miguel now has to ensure that the data is restricted to specific tenants or consumers, in this case Marketing. In the pool model, no external user has direct access to underlying tables. All access is restricted using views. Miguel creates a view for each of the fact and dimension tables to include a condition to filter records from the consumer tenant’s namespace. |
Miguel creates v_customersales to combine sales fact and customer dimension tables with a restrictive filter for tenant.namespace = current_namespace. current_namespace is a built-in function of Redshift that returns the namespace of the cluster it’s executed on.
Execute these SQL Queries on the producer cluster: |
Show and explain to the customer that the producer does NOT see any data when the query for the View is executed because of the current_namespace and that there is not data associated with this tenant.
|
|
Miguel will now share these views with Masood from Marketing, who has provided the Marketing cluster namespace to Miguel. |
Execute this command on the producer cluster to create the data share, add to it and then share only the views with the consumer cluster (replace the tag before executing):
|

|
|
Miguel verifies the data sharing worked before asking Masood to check the data on the Marketing cluster. |
Execute the following queries on the producer cluster:
|



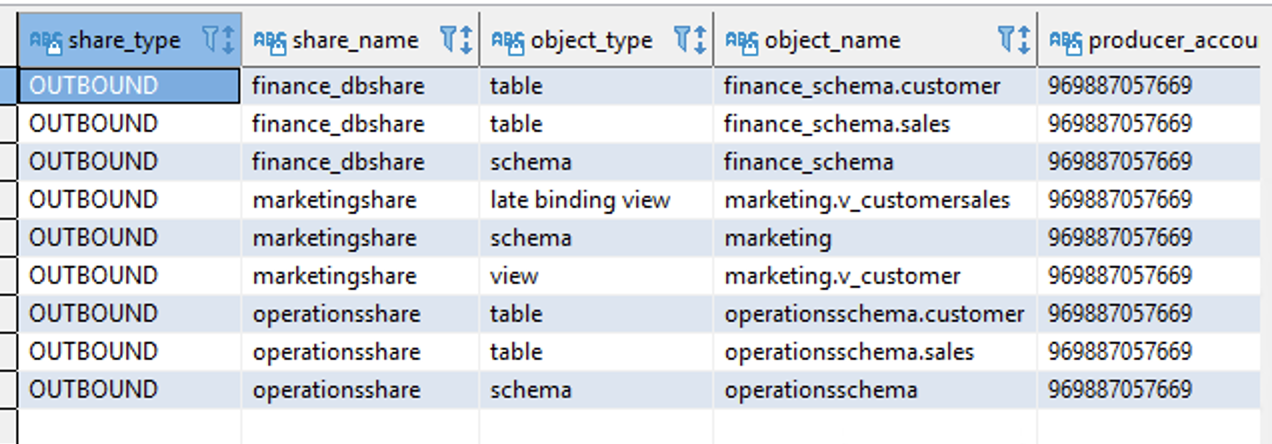

|
|
Masood checks that he can see the data share and then creates a new external schema from the data share. Masood is then able to query the views and verify that he can see the data from the producer cluster. |
Switch SQL Workbench/J over to the consumer cluster and execute the following queries on it:
Show the customer that this tenant can only see the customers that are associated with them and not the other customers. |


|
|
Masood wants to see what other data shares the cluster has access to. You can grant access to users and groups on this cluster as needed with the GRANT USAGE and REVOKE USAGE commands just like any other table independent of the Producer cluster or asking the Producer cluster admins when Marketing changes it’s access decisions. |
Execute the following query:
|

|
Before you leave
To reset the demo for your next customer meeting, execute the following SQL in the Consumer cluster:
drop schema extoperationschema;
drop schema finance_schema;
drop schema extmarketingschema;
drop database redimportsdb;
drop database operations_db;
Then execute the following SQL on the Producer cluster:
drop schema pooling;
drop schema operations_schema;
drop database redimportsdb;
REVOKE USAGE ON DATASHARE finance_dbshare FROM NAMESPACE '<<ConsumerNamespace>>';
REVOKE USAGE ON DATASHARE operationsshare FROM NAMESPACE '<<ConsumerNamespace>>';
REVOKE USAGE ON DATASHARE marketingshare FROM NAMESPACE '<<ConsumerNamespace>>';
Double-check and make sure the data shares on each cluster are gone in the AWS Console, if any left, delete them.
If you are done with your demo, please consider deleting the CFN stack. If you would like to keep it for use in the future, you may do the following to avoid having to pay for unused resources:
- Pause your Redshift Cluster
- Pause your Postgres Server
- Stop the DMS task
- Stop the EC2 instance