Machine Learning in Redshift SQL
Demo Video

Before you Begin
Capture the following outputs from Cloud Formation console to be used in this demo:
- TaskDataBucketName
- RedshiftClusterUser
- RedshiftClusterPassword
- RedshiftClusterIdentifier
Now we need to run some DDL and a copy command to create the test and training data tables and load them with data. Execute this command in the SQL Workbench/J or your favorite SQL client.
CREATE TABLE IF NOT EXISTS pizza_deliveries_test_set
(
delivery_date VARCHAR(60)
,cust_number INTEGER
,store_number SMALLINT
,delivery_zip CHAR(10)
,delivery_city VARCHAR(90)
,delivery_state CHAR(2)
,order_amt SMALLINT
,offer_type VARCHAR(20)
,location_type VARCHAR(11)
,order_method VARCHAR(10)
)
;
CREATE TABLE IF NOT EXISTS pizza_deliveries_training_set
(
delivery_date VARCHAR(60)
,cust_number INTEGER
,store_number SMALLINT
,delivery_zip CHAR(10)
,delivery_city VARCHAR(90)
,delivery_state CHAR(2)
,order_amt SMALLINT
,offer_type VARCHAR(20)
,location_type VARCHAR(11)
,order_method VARCHAR(10)
,reason VARCHAR(19)
,delivery_issue VARCHAR(1)
)
;
copy public.pizza_deliveries_test_set from 's3://redshift-demos/data/pizza_deliveries_testing.csv' iam_role default delimiter ',' IGNOREHEADER 1 region 'us-east-1';
copy public.pizza_deliveries_training_set from 's3://redshift-demos/data/pizza_deliveries_training.csv' iam_role default delimiter ',' IGNOREHEADER 1 region 'us-east-1';
Client Tool
The screenshots for this demo will leverage the SQL Client Tool of SQLWorkbench/J so be sure to complete the setup before proceeding. Alternatives to the SQLWorkbench/J are the Redshift Query Editor.
Challenge
Kim has recently been tasked to create a Machine Learning model which will help identify potential pizza delivery issues to improve customer satisfaction. She wants to leverage the new Redshift ML feature, so she will use this opportunity to show Miguel how he can take advantage of his SQL skills to do Machine Learning in Redshift. To solve this challenge Miguel will do the following:
Create Model
| Say | Do | Show |
|---|---|---|
|
Redshift ML makes it easy for data analysts to use simple SQL queries to specify the data you want to use as inputs to train your model and the output you want to predict. When you run your create model command, Amazon Redshift ML will securely export the data to Amazon S3, call SageMaker Autopilot to automatically prepare the data, select the appropriate pre-built algorithm and apply the algorithm for model training. Amazon Redshift ML handles all the heavy lifting and interactions between Redshift, S3 and SageMaker on your behalf while running up to 250 models to select the most appropriate model that gives the best predictions based on your data. Kim asks Miguel to initiate the model run in Redshift using SQL. |
This step can take up to one hour, so plan ahead for your demo and run ahead of time. Replace |
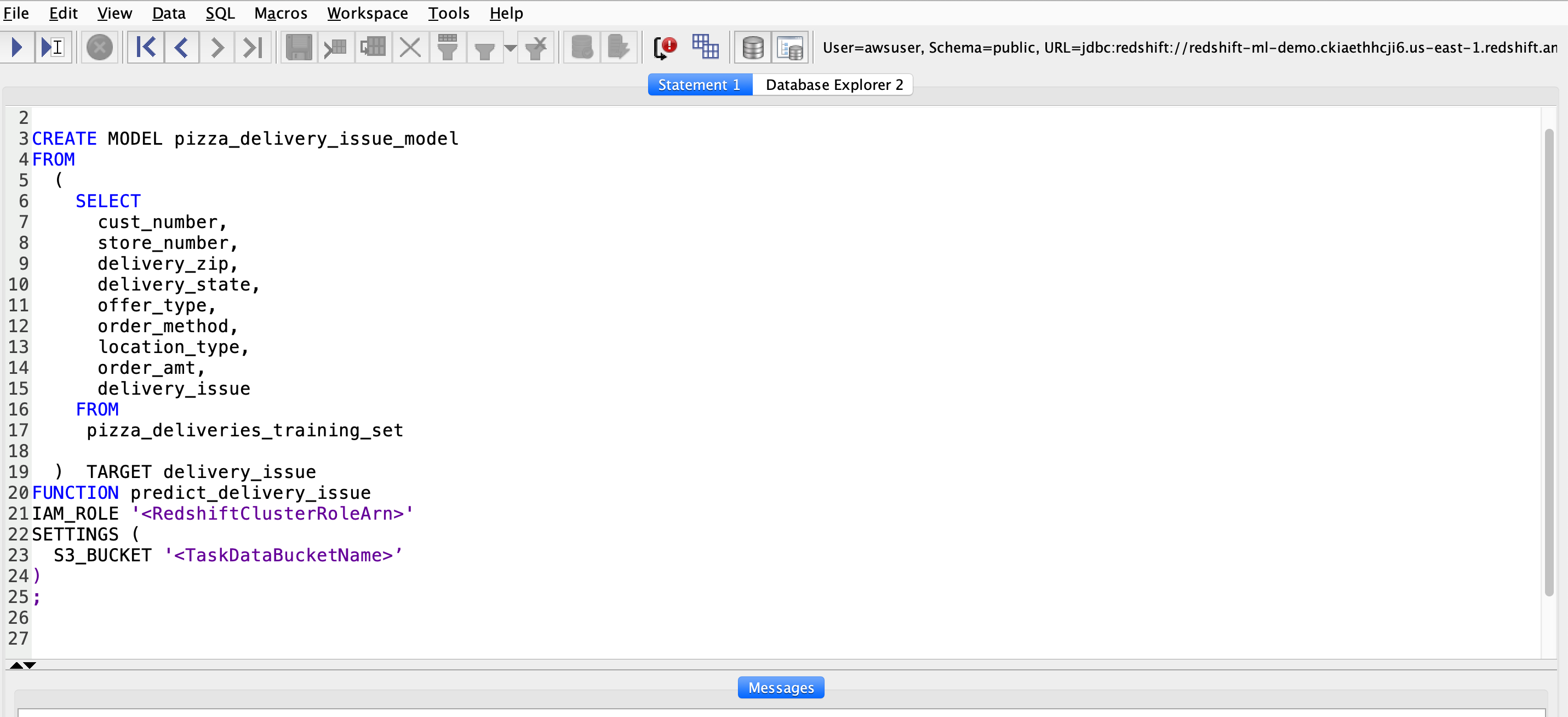
|
| Miguel will review the Create Model Statement that he previously ran. The columns in the select statement represent the inputs or features to the model. The last column is the ‘Target’ - this is what Miguel is trying to predict. He gives a Function name - this will be returned from SageMaker to Redshift to use in a SQL Statement for making predictions. Once the create model statement is submitted, Redshift takes care of exporting data to S3 and invoking SageMaker on your behalf. Miguel can check the output of the HyperParameter tuning job from SageMaker to see the best training job chosen. | Navigate to the AWS SageMaker Console and open the HyperParameter tuning jobs. Here you will find the details of the Model Run, the best model selected and time it took to run the models to select the best one. |
|

Review Model Selected
| Say | Do | Show |
|---|---|---|
|
Miguel needs to share the output of his model create run with his business users and Kim to get their feedback and input. They are interested in the the statistical accuracy of the measure of the precision and recall of all classes in the model. They are also interested in the cost of running the models, the name of the function, the time to run and other related data. |
Execute the query below in your SQL client: |
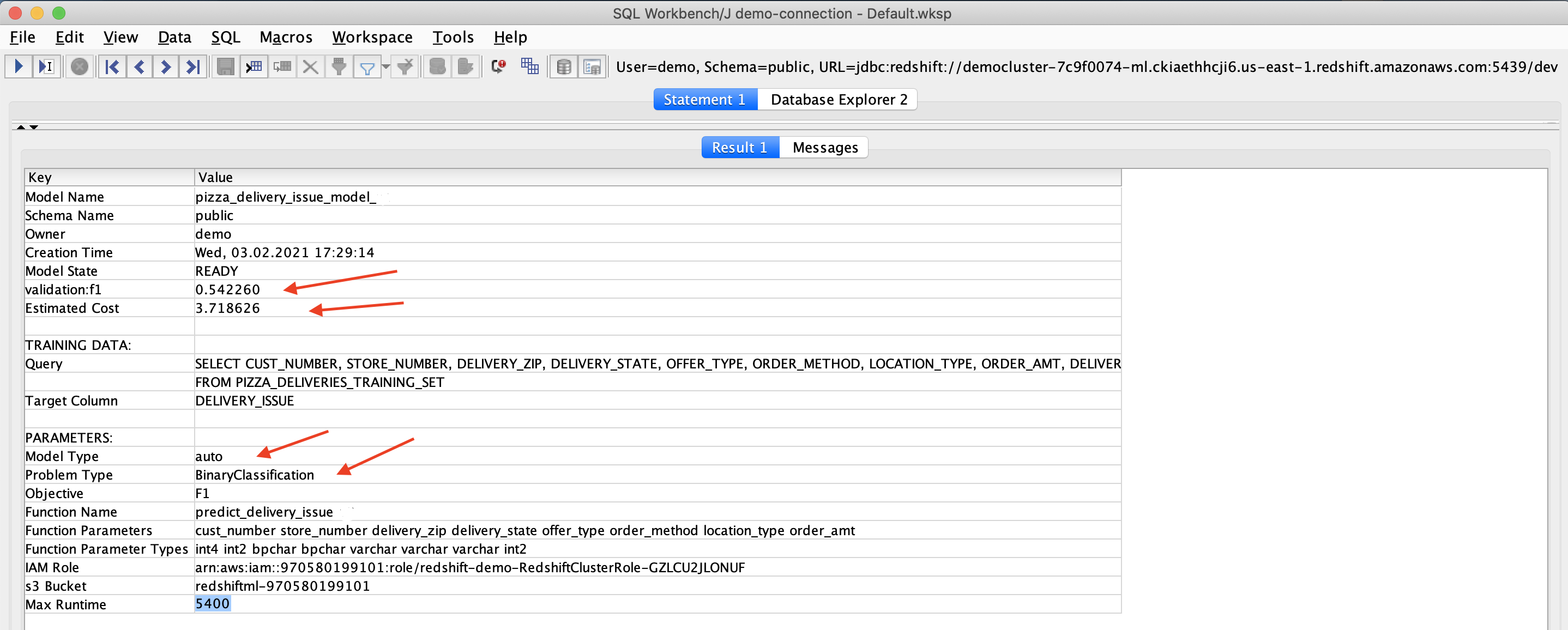
|
|
Kim wants to encourage Miguel to get more familiar with machine learning. Miguel can do this by drilling down in SageMaker, he can see the details of the best training job. He is able to see that Auto ML chose the XGBoost algorithm, that SageMaker used an M5.4XL instance and if he scrolls down further he can see all the hyperparameter values chosen.
When you use Amazon Redshift ML, the prediction functions run within your Amazon Redshift cluster and you do not incur additional expense. However, the CREATE MODEL request uses Amazon SageMaker for model training and Amazon S3 for storage and incurs additional expense. The expense is based on the number of cells in your training data, where the number of cells is the product of the number of records (in the training query or table) times the number of columns | Go to SageMaker and click on HyperParameter Tuning Jobs, then Best Training Job Summary and then click on the job name. |


|
Validate the Model
| Say | Do | Show |
|---|---|---|
| Miguel wants to see how well the model predicts the actual delivery issues in the training data set. He can also use this query later to develop checks to ensure the accuracy of the selected model to track drift. |
Execute this query in your SQL Client: |
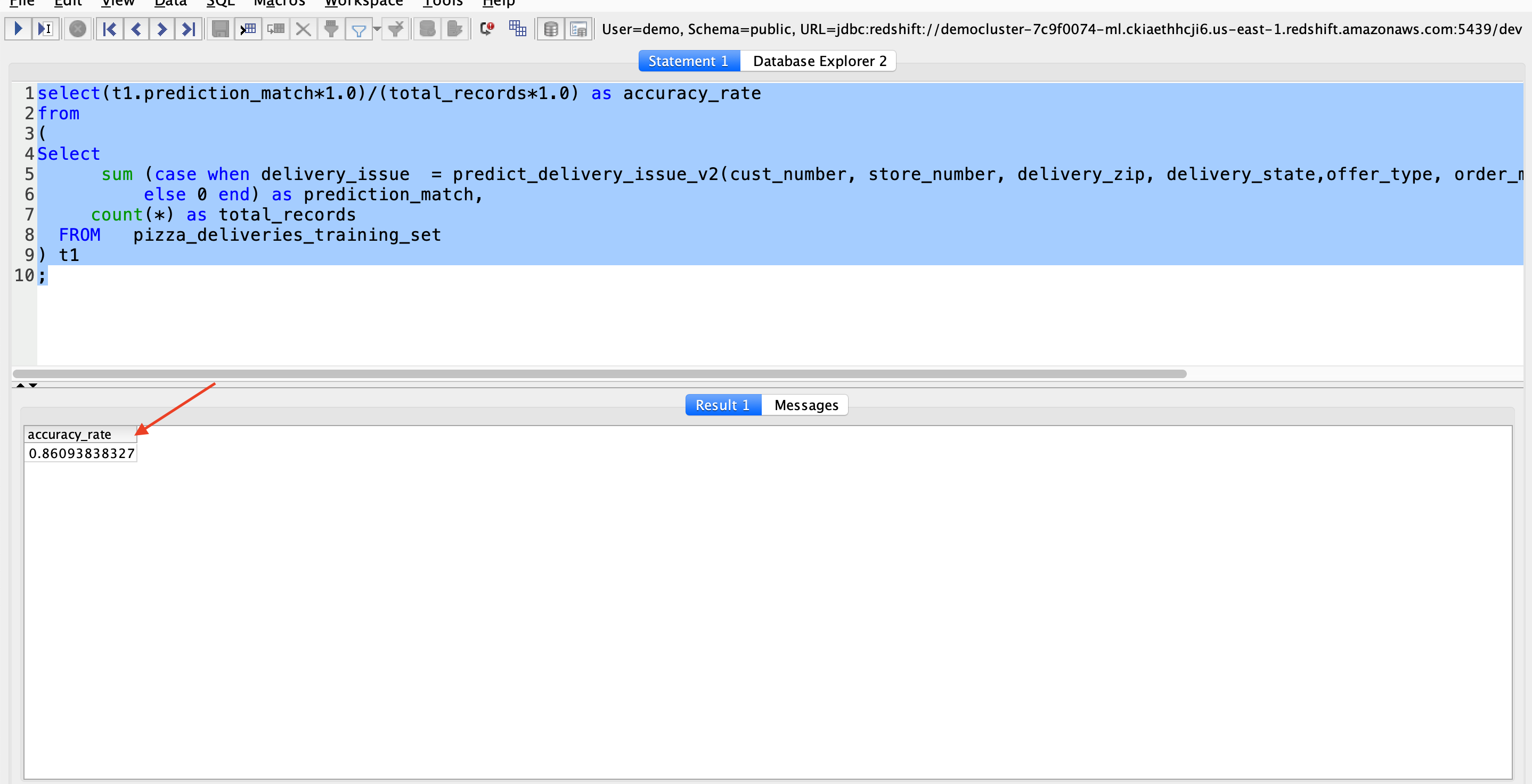
|
Run Prediction Query
| Say | Do | Show |
|---|---|---|
|
Miguel receives streaming data of pizza orders, but it can be the next day before he knows if there were any issues. He wants to run the prediction query so that the customer service team can be pro-active in reaching out to customers who may have issues. He can use new data against his selected model to do these real-time predictions. |
Execute this query in your SQL Client: |
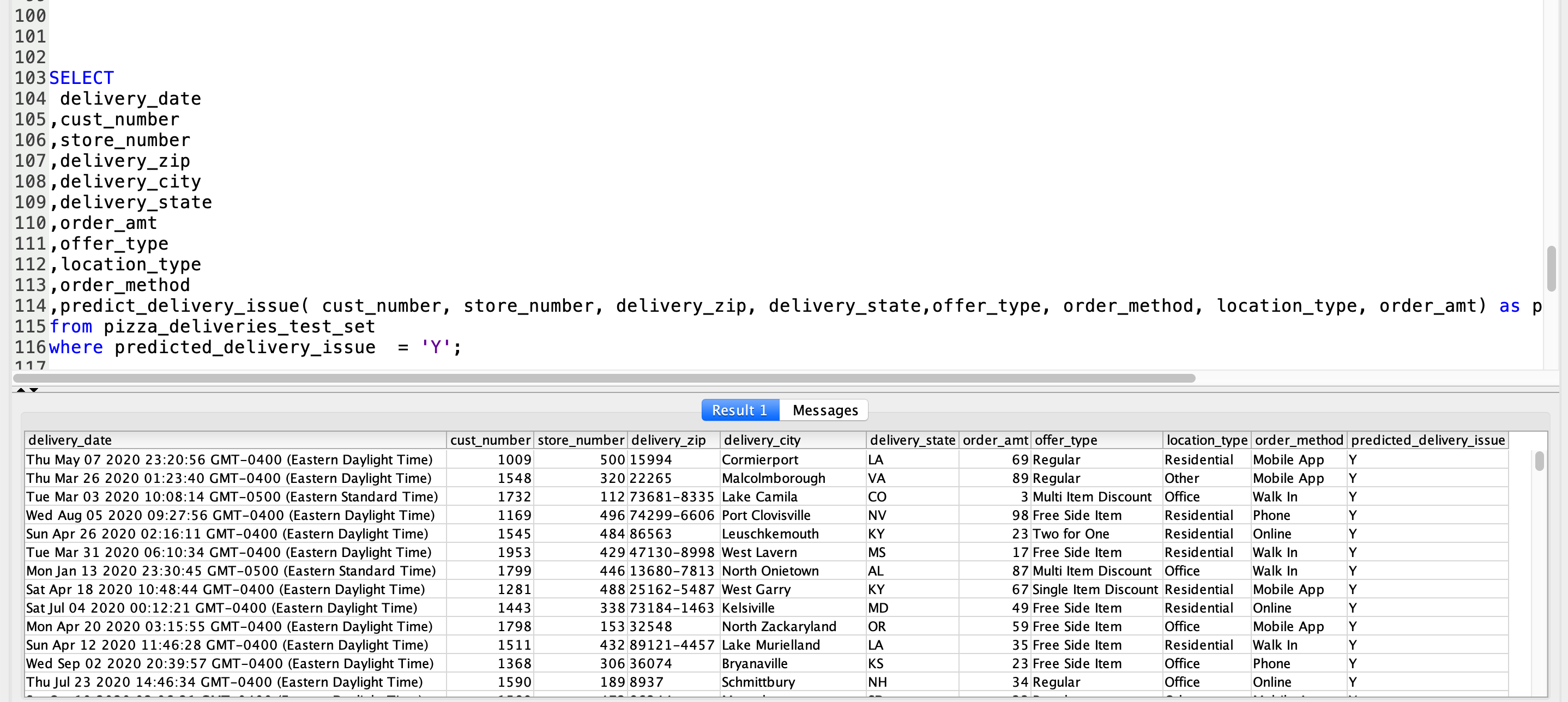
|
Analyze Results
| Say | Do | Show |
|---|---|---|
| Miguel now needs to share this real-time data with the Customer Service team in a more convenient method so they can act on the predicted delivery issue. He will create a QuickSight report to accomplish this task using his query from before. |
|
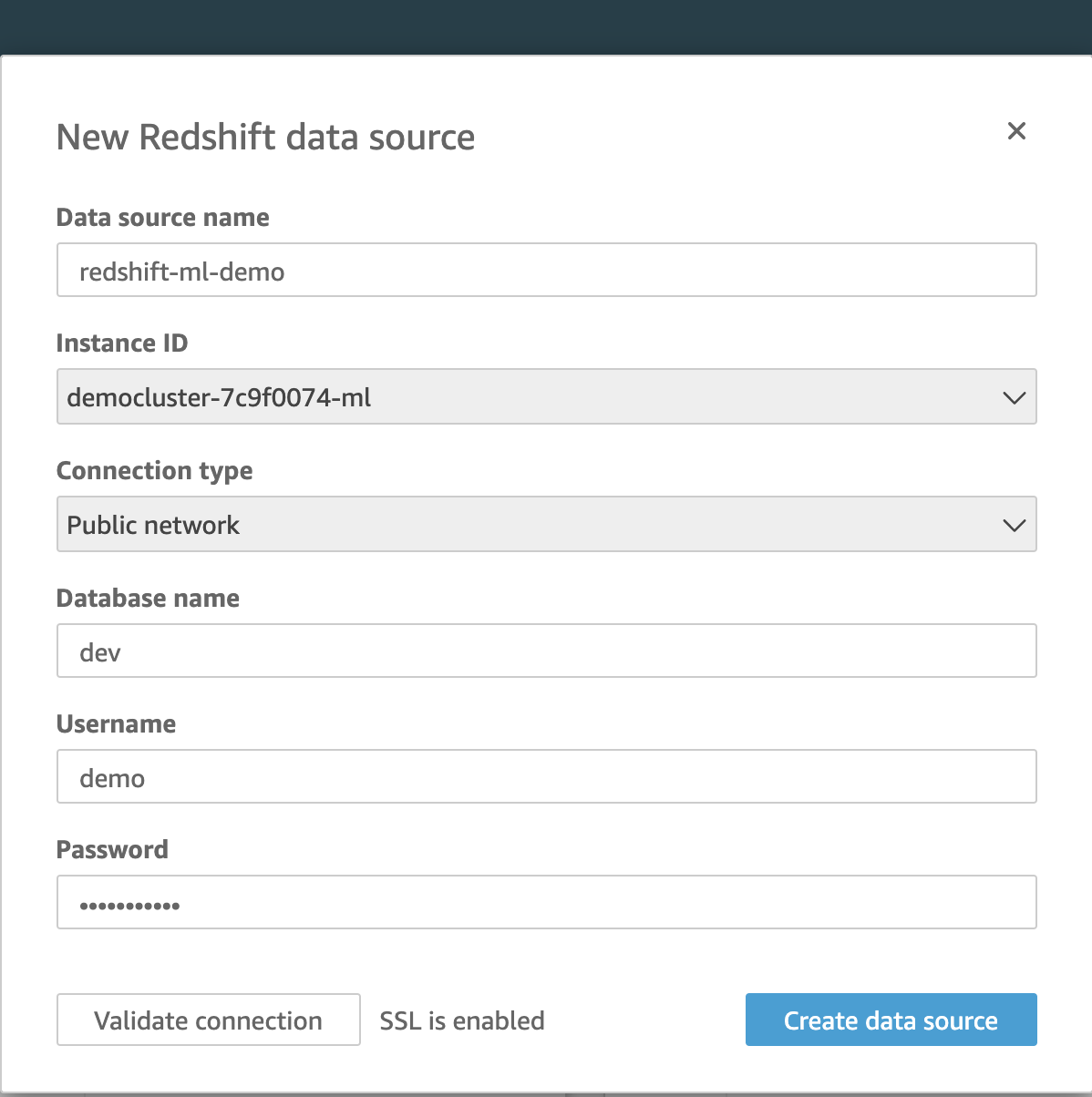
|
| Once the connection is established Quicksight will need to know which SQL to execute. |
On the next pop-up, make the following selections:
|

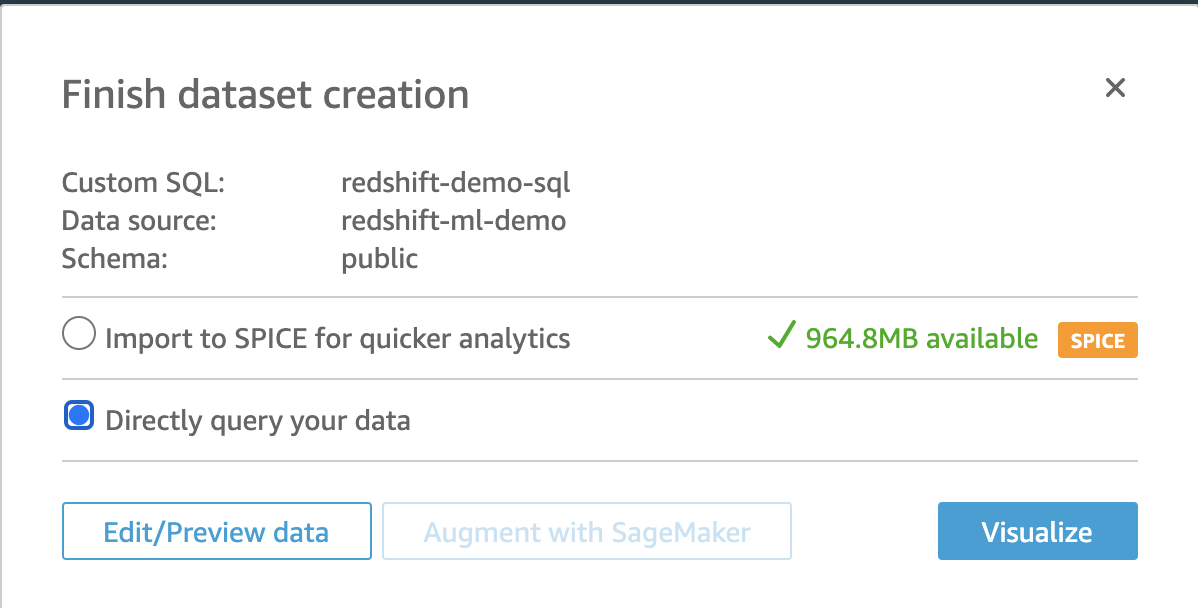
|
| Miguel will build some Visualizations. |
New window opens up to allow you to build the visual charts.
Miguel can quickly observe that the state of Maryland has more issues than other states. He can add a drill-down on zip code and add another dimension to gain further insights. |
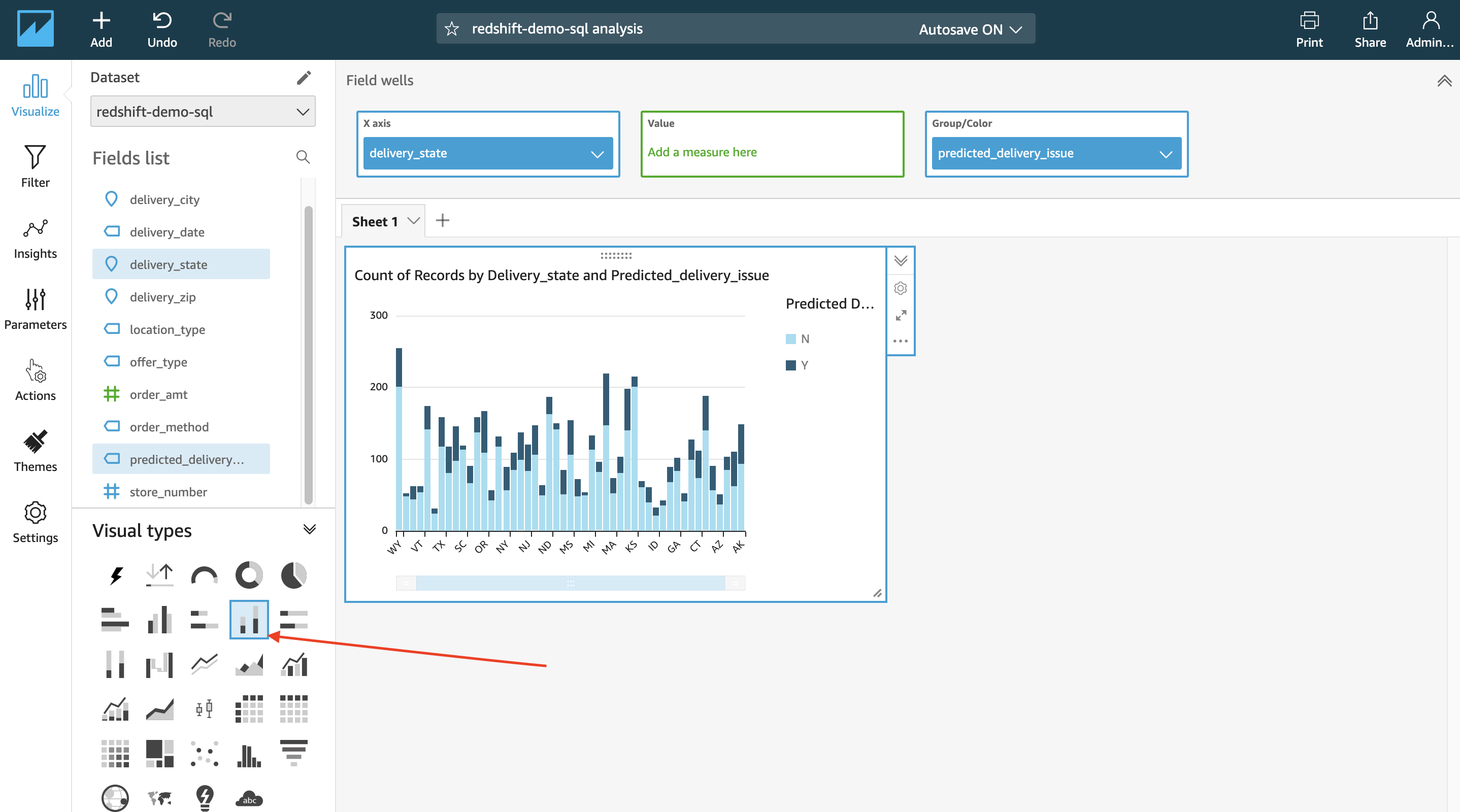

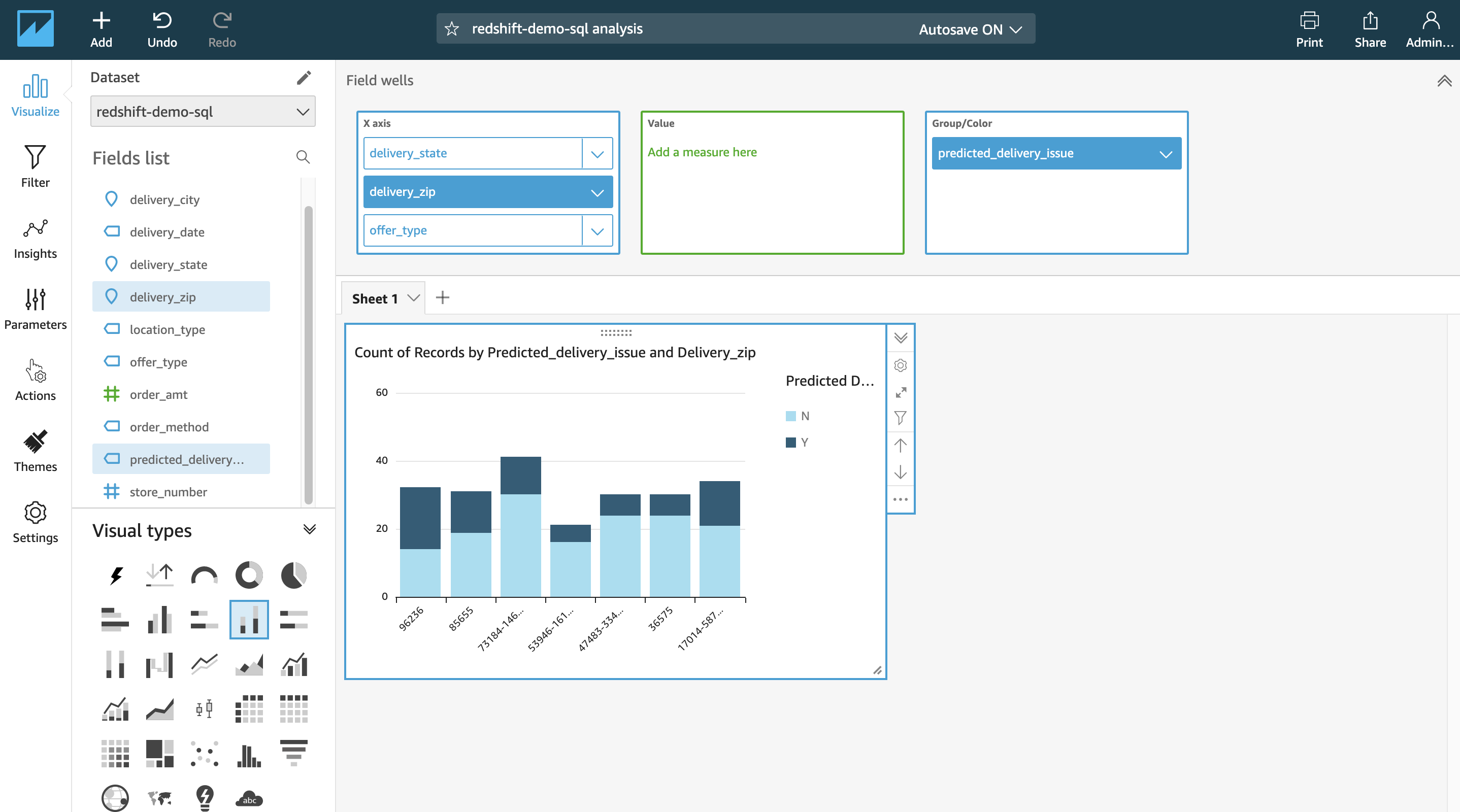
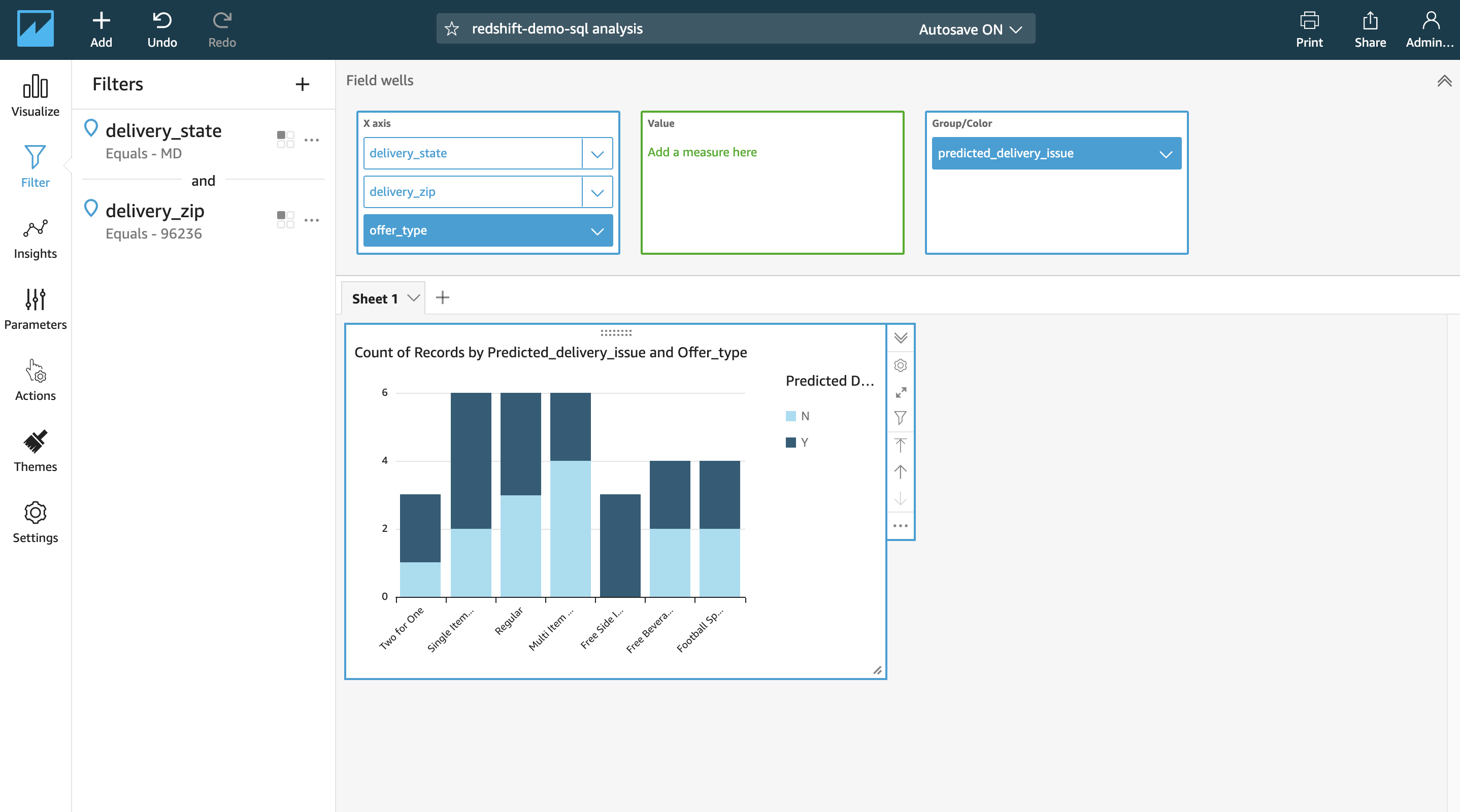
|
Before you Leave
If you are done using your cluster, please think about deleting the CFN stacks or to avoid having to pay for unused resources do these tasks:
- pause your Redshift Cluster
If you plan to repeat what you did for your customer, then leave your cluster paused and remember that you do not need to run the create model step again as it’s has already been run. If you want to reset completely, then run this query on your cluster:
drop MODEL pizza_delivery_issue_model;