Querying operational data within DW
Demo Video
This demo was extended thanks to welcome feedback, so video #2 covers the extended sections involving the historical data and combining it all together.

Before you Begin
Capture the following parameters from the launched CloudFormation template as you will use them in the demo.
https://console.aws.amazon.com/cloudformation/home?region=us-east-1#/stacks?filteringText=&filteringStatus=active&viewNested=true&hideStacks=false
- RedshiftClusterRoleArn
- AuroraMasterSecret
- AuroraClusterEndpoint
- GlueExternalDatabaseName
Client Tool
The screenshots for this demo will leverage the SQL Client Tool of Redshift Query Editor. Be sure to complete the SQL Client Tool setup before proceeding.
Challenge
Miguel has recently been tasked to incorporate live customer data into a BI application. This process would involve inserting new customer records from a live OLTP source and updating existing records with new information. Miguel has also been tasked to incorporate a unified view of live OLTP sales data along with latest sales data in Redshift cluster and history sales data in the S3 Data Lake. To solve this challenge Miguel will do the following:
- Setup External Schema
- Execute Federated Queries
- Execute ETL Processes
- Create a materialized view
- Register and connect to Data Lake
- Combine data from Postgres OLTP, Redshift Data Warehouse and S3 Data Lake
Setup External Schema
| Say | Do | Show |
|---|---|---|
|
Miguel needs to provide Redshift the login credentials to the RDS PostgreSQL DB. This is accomplished using a Secret stored in the AWS Secrets Manager. The AWS Secret was created when the Aurora DB was created. Let’s create an IAM policy to allow access to the secret. Replace the value for <AuroraMasterSecret> with the value previously determined. |
Create an IAM Policy called RedshiftPostgreSQLSecret-lab with the following permissions.
|
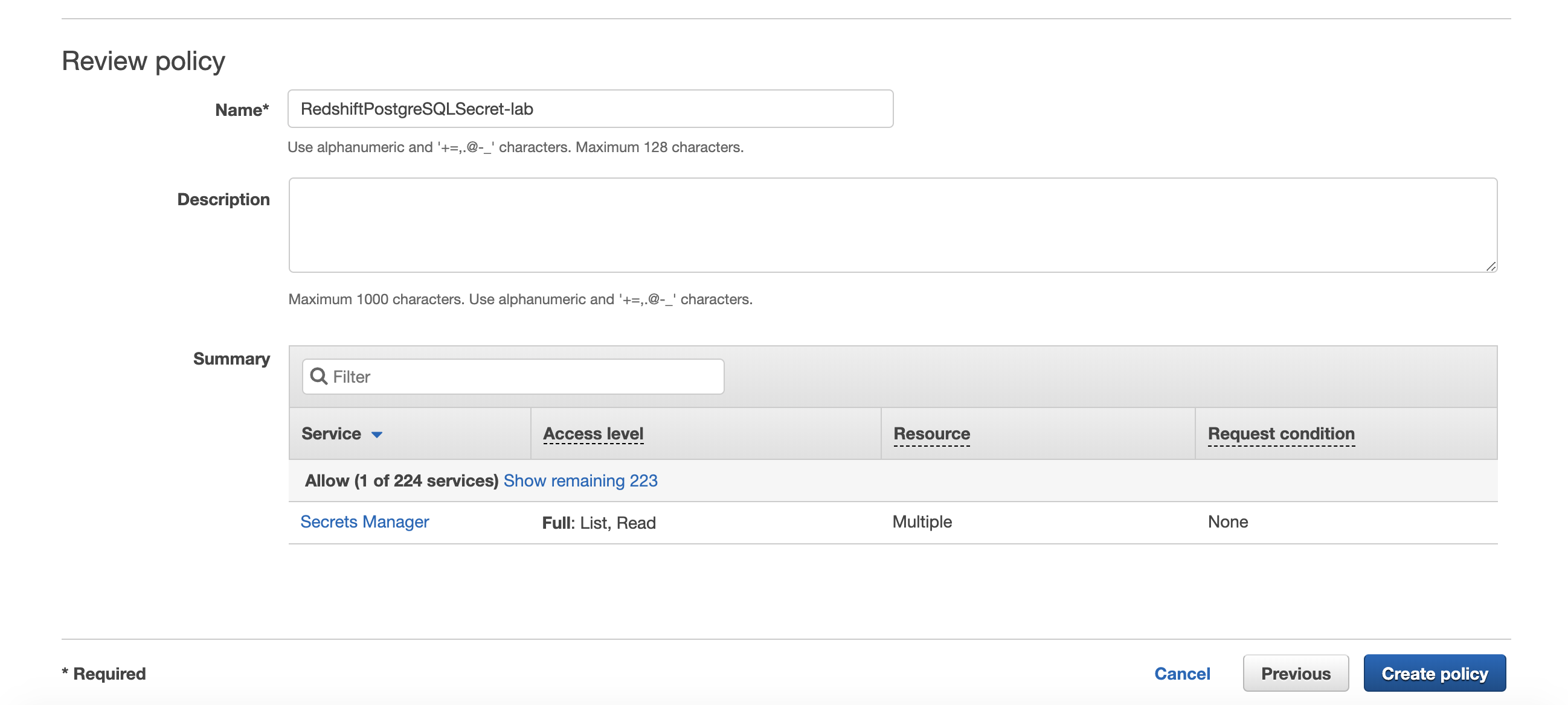
|
| Next, Miguel needs to modify the Role associated to the Redshift cluster and attach this policy to that role. | Find the <RedshiftClusterRoleArn> associated with the Redshift Cluster and attach the RedshiftPostgreSQLSecret-lab Policy created earlier. |
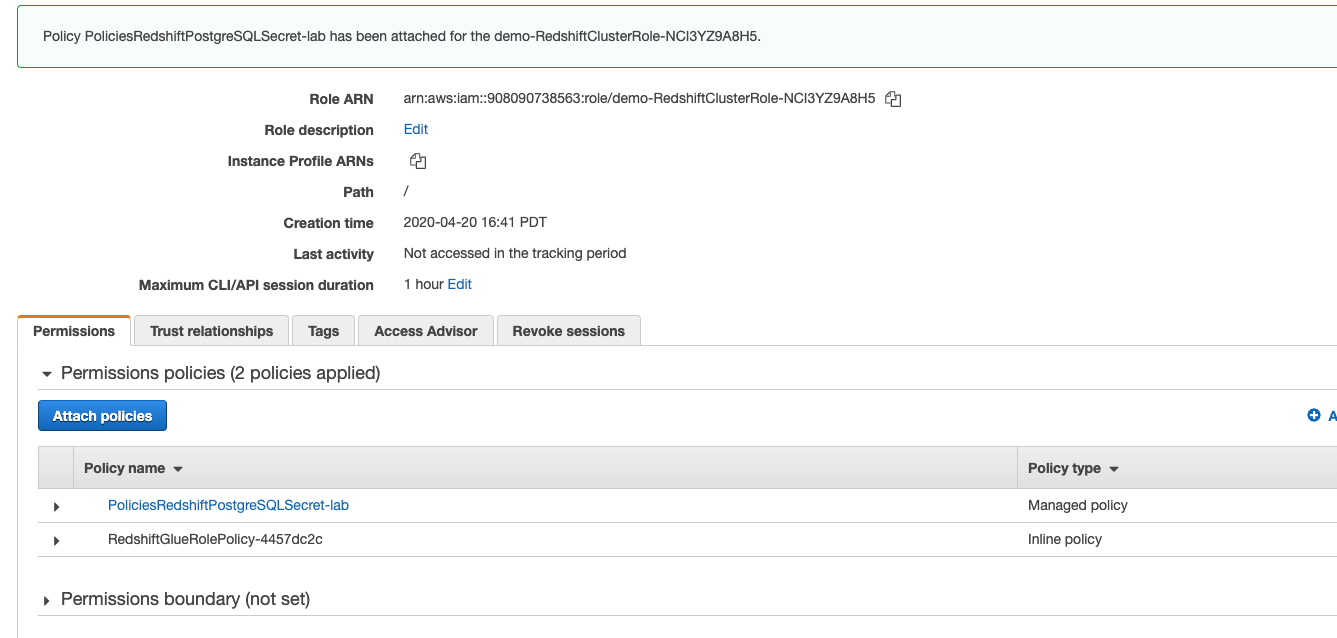
|
|
Next, Miguel needs to create an external schema in Redshift which associates Aurora database endpoint with the AWS Secret and Role which has access to get the login credentials.
Execute the following statement replacing the values for <AuroraClusterEndpoint> and <AuroraMasterSecret> with the values previously determined. Amazon Redshift now supports attaching the default IAM role. If you have enabled the default IAM role in your cluster, you can use the default IAM role as follows. Follow the blog for details. |
Log into your Redshift Cluster using the Query Editor application and execute the following statement.
|
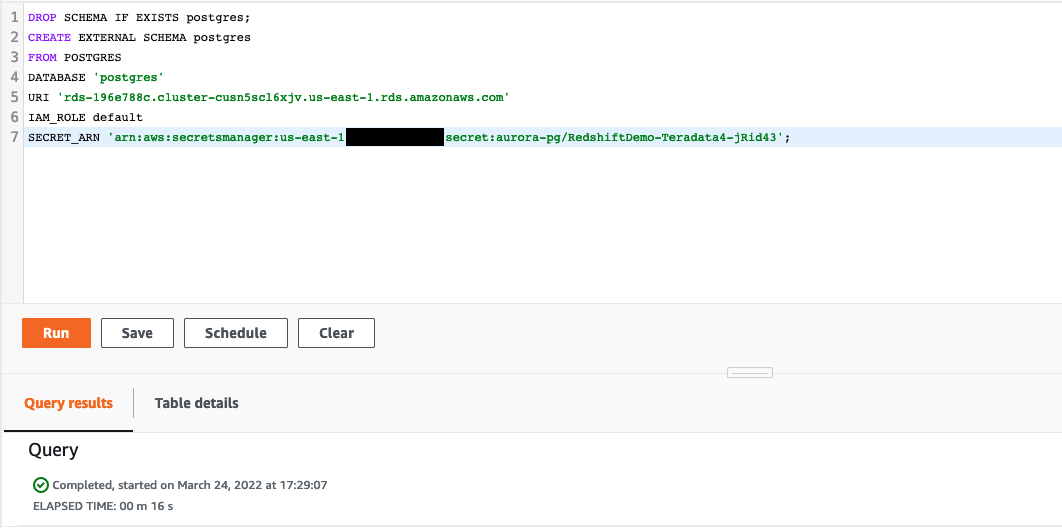
|
Execute Federated Queries
| Say | Do | Show |
|---|---|---|
| At this point Miguel has access to all the tables in the RDS DB database via the Postgres schema. Miguel wants to execute some queries on the external schema tables. |
Execute a simple select from the federated customer table.
|
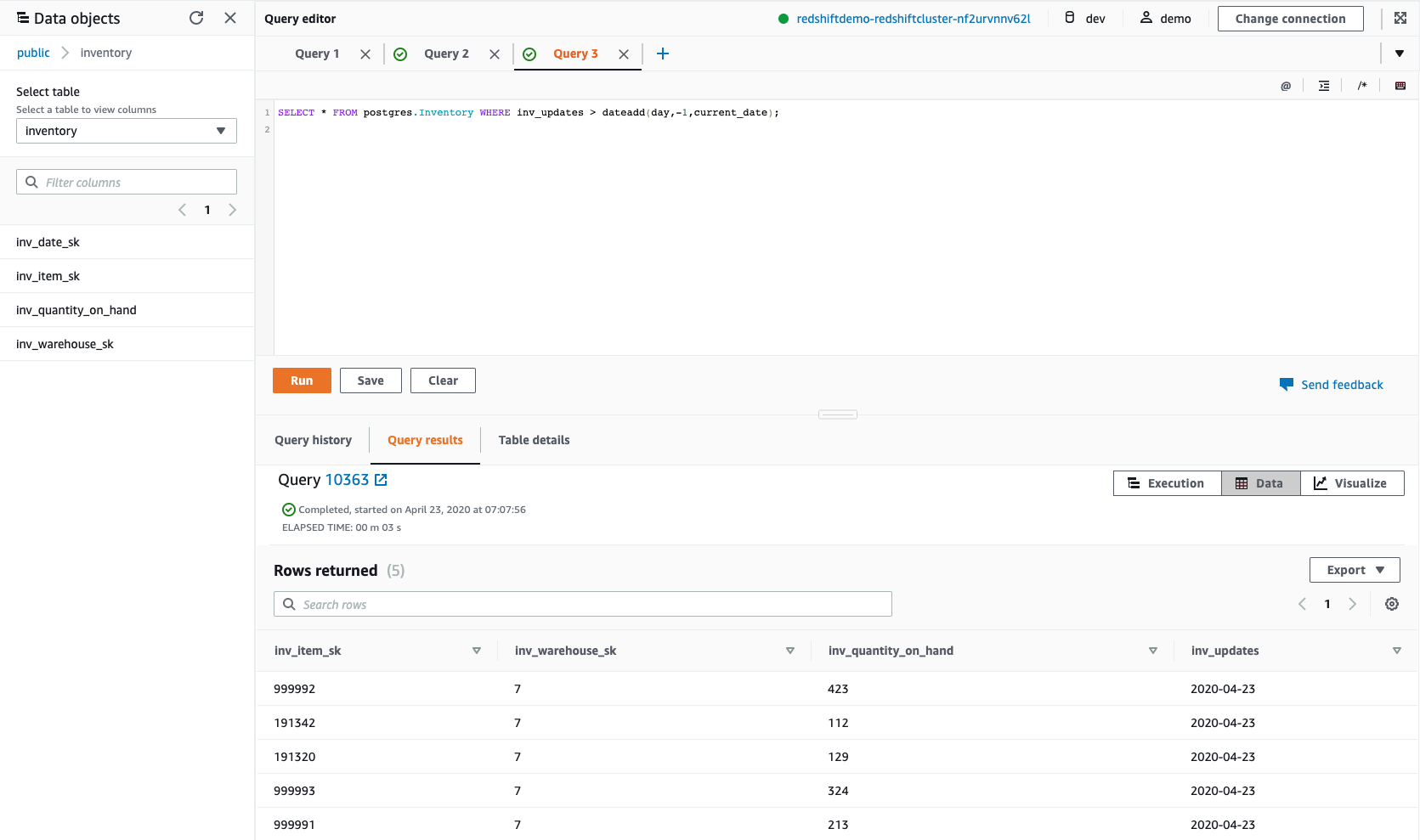
|
|
Next, Miguel wants to run some SQLs with a join between a federated table and local tables. |
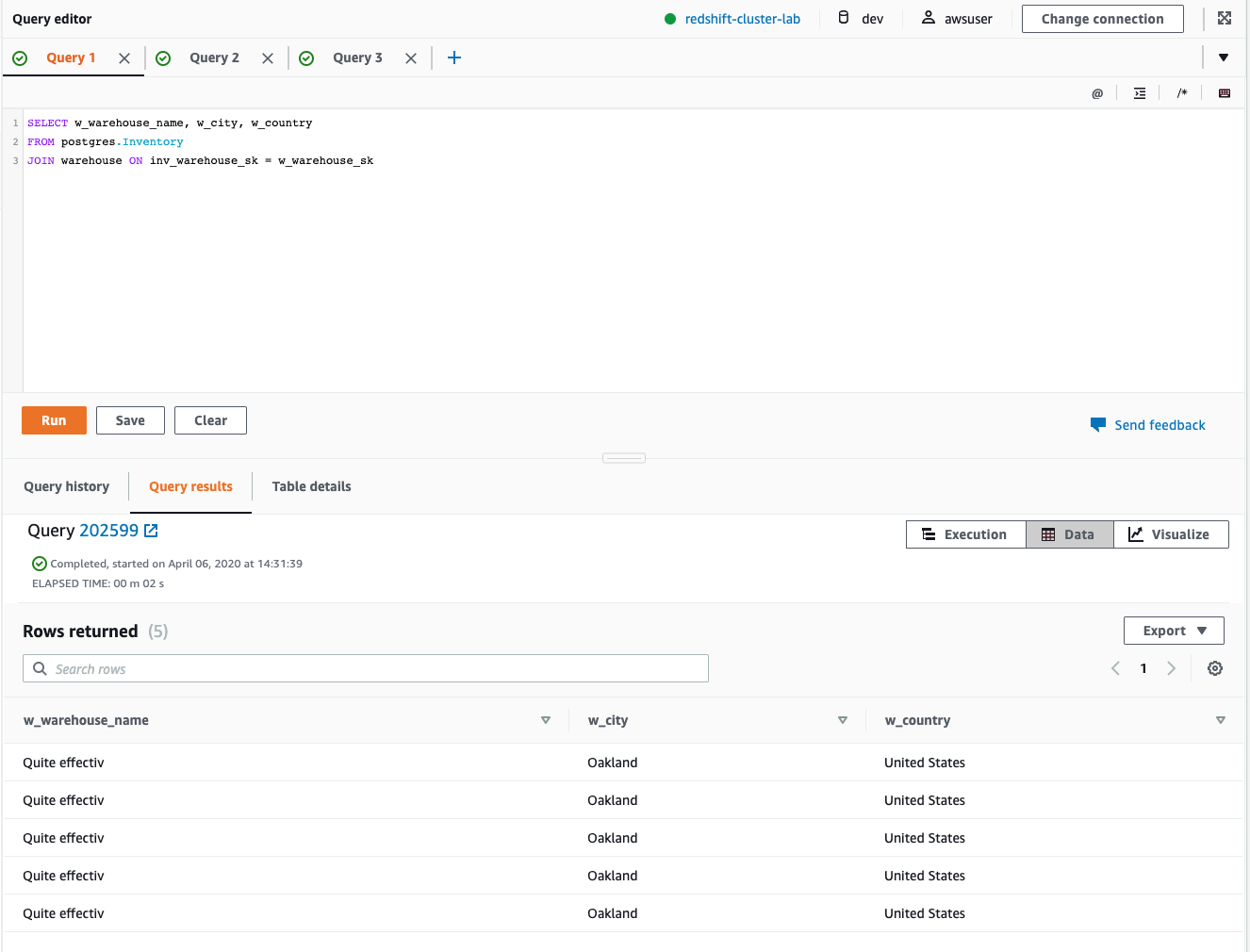
Execute a join between the federated inventory table and the local warehouse table.
|
|
Execute ETL Processes
| Say | Do | Show |
|---|---|---|
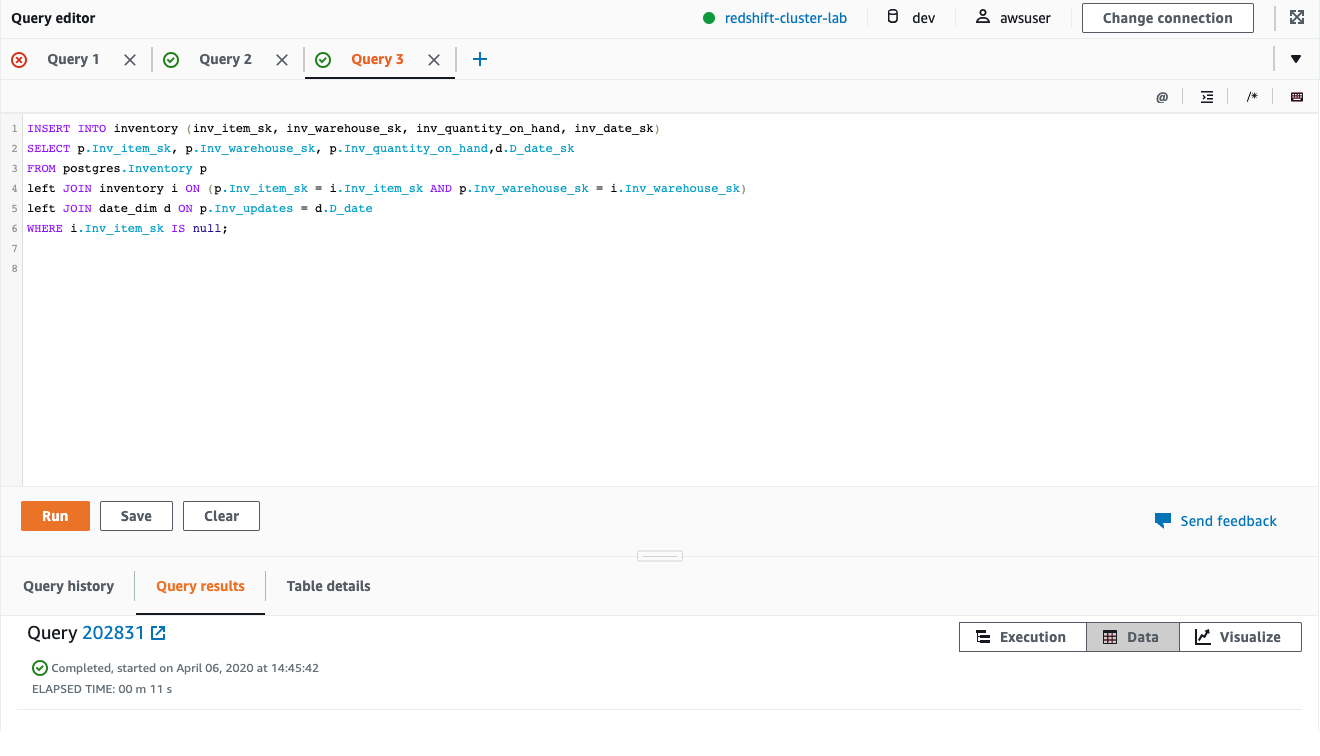
| Next Miguel wants to run queries using federated tables for use in ETL processes. Traditionally, these tables needed to be staged locally in order to perform change detection logic, however, with federation, they can be queried and joined directly. |
Execute the following ETL script.
|
|
Create a materialized view
| Say | Do | Show |
|---|---|---|
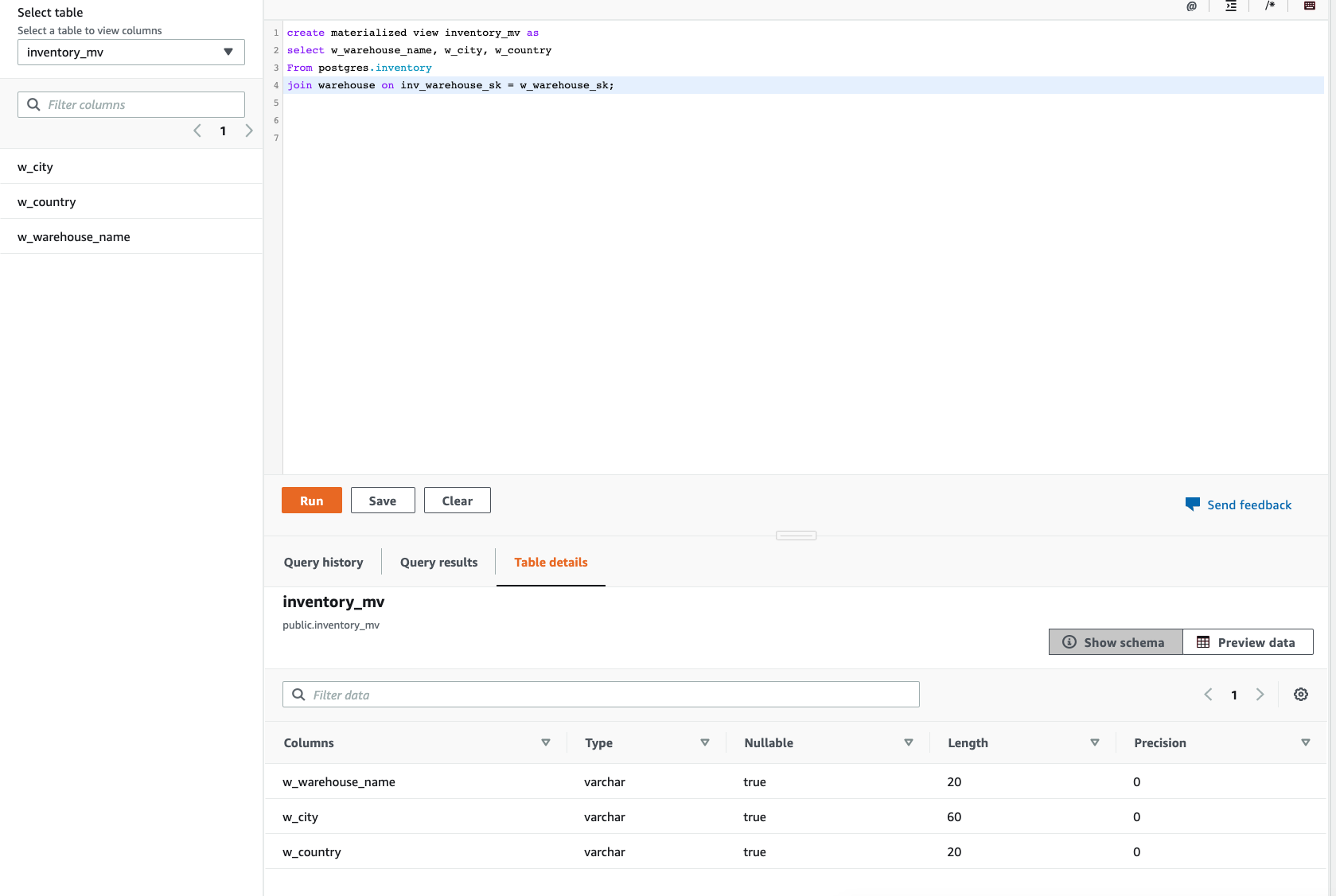
| Next Miguel wants to create a materialized view to store the precomputed results from federated query without having to access the base tables at all. |
Execute the following ETL script.
|
|
Register and connect to Data Lake
| Say | Do | Show |
|---|---|---|
|
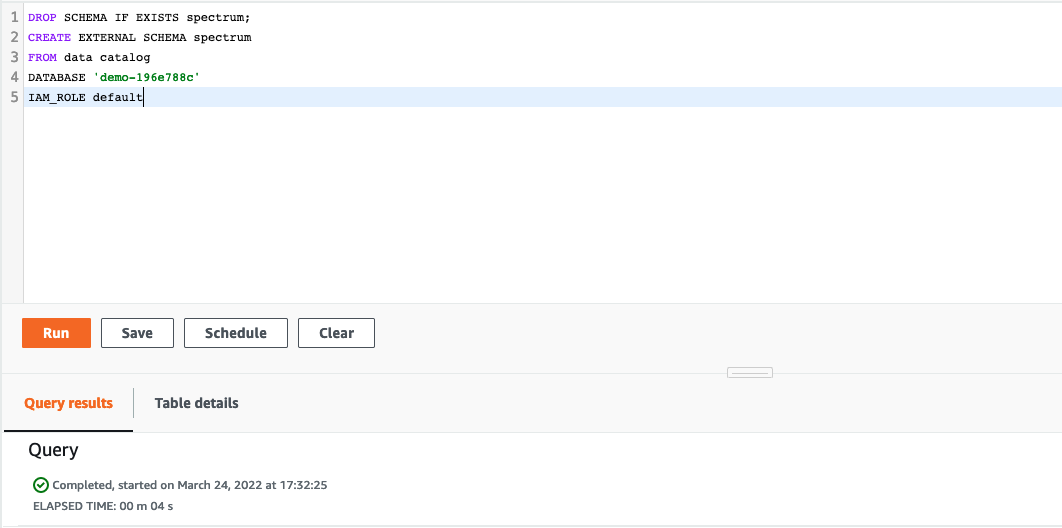
Miguel needs to create an external schema in Redshift which references a database in the external data catalog and provides the IAM role ARN that authorizes your cluster to access Amazon S3 on your behalf. |
Execute the following SQL statements.
|
|
|
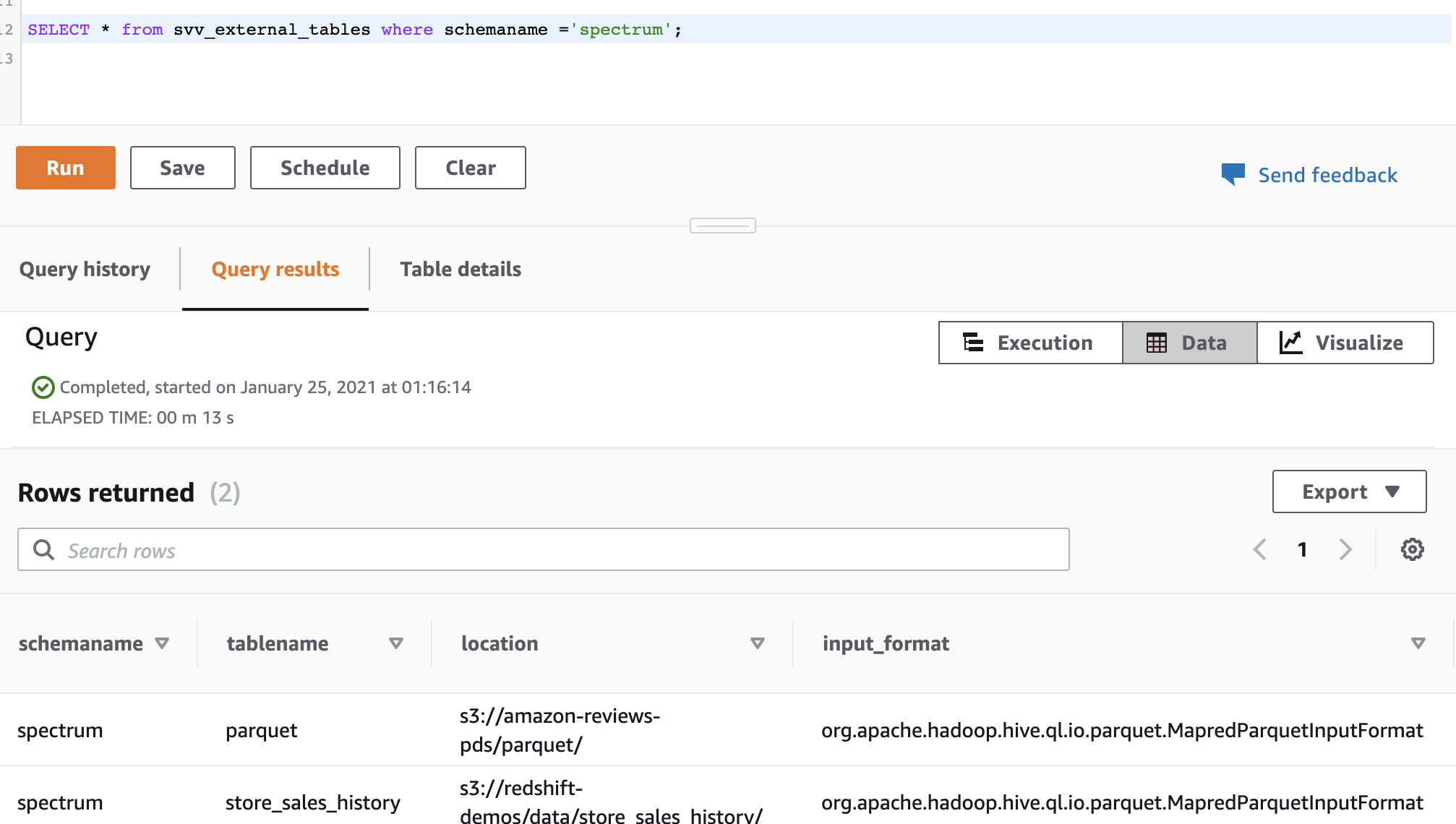
Miguel confirms the external tables has been added |
Execute the following SQL statements to query the system table to list the external tables in the external schema
|
|
Combine data from Postgres OLTP, Redshift Data Warehouse and S3 Data Lake
| Say | Do | Show |
|---|---|---|
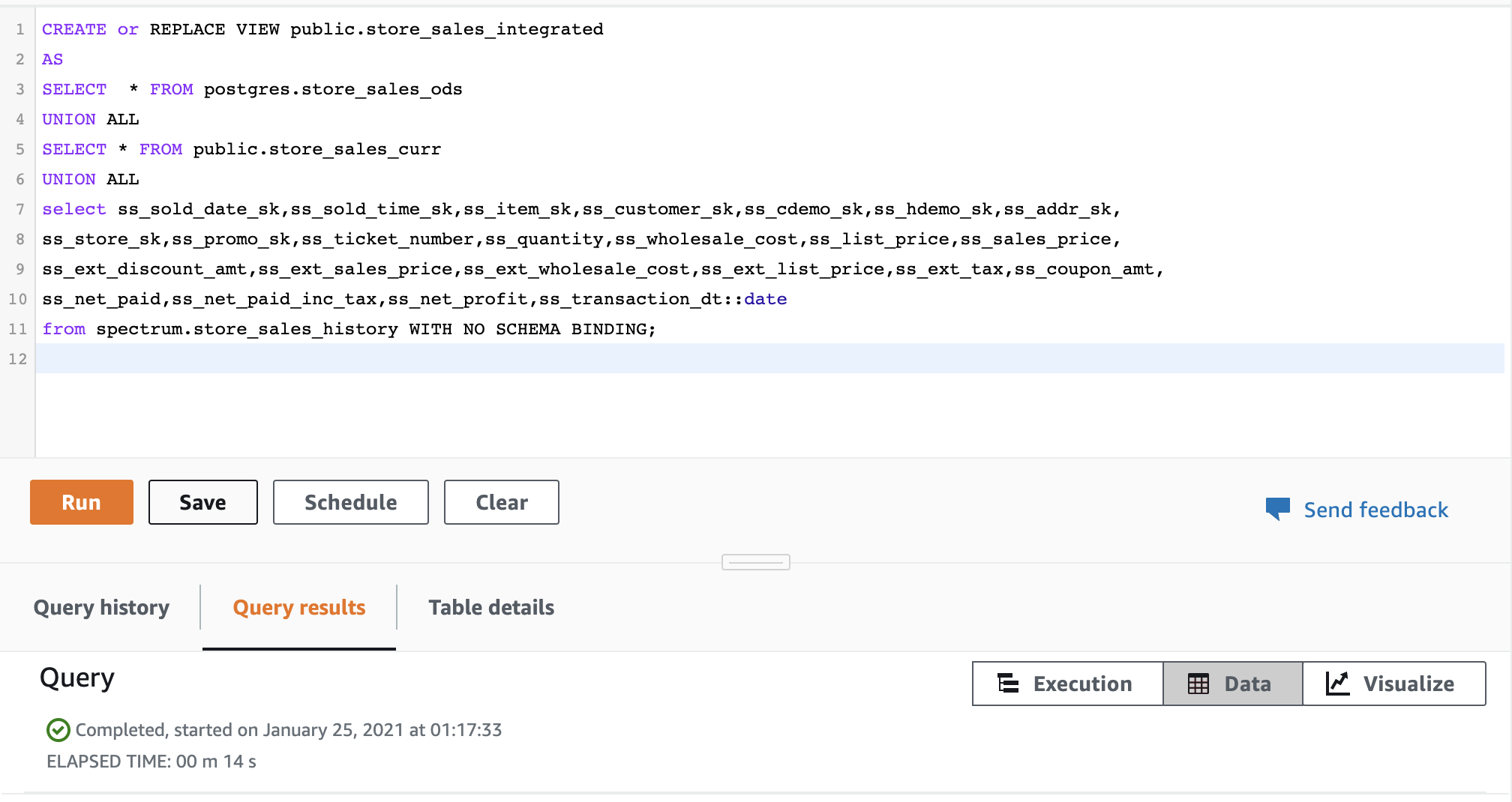
| Miguel will create a view combining the live OLTP Postgres sales data along with recent sales data already in Redshift Data Warehouse and the historical sales data in the S3 Data Lake. |
Execute the following SQL statement
|
|
|
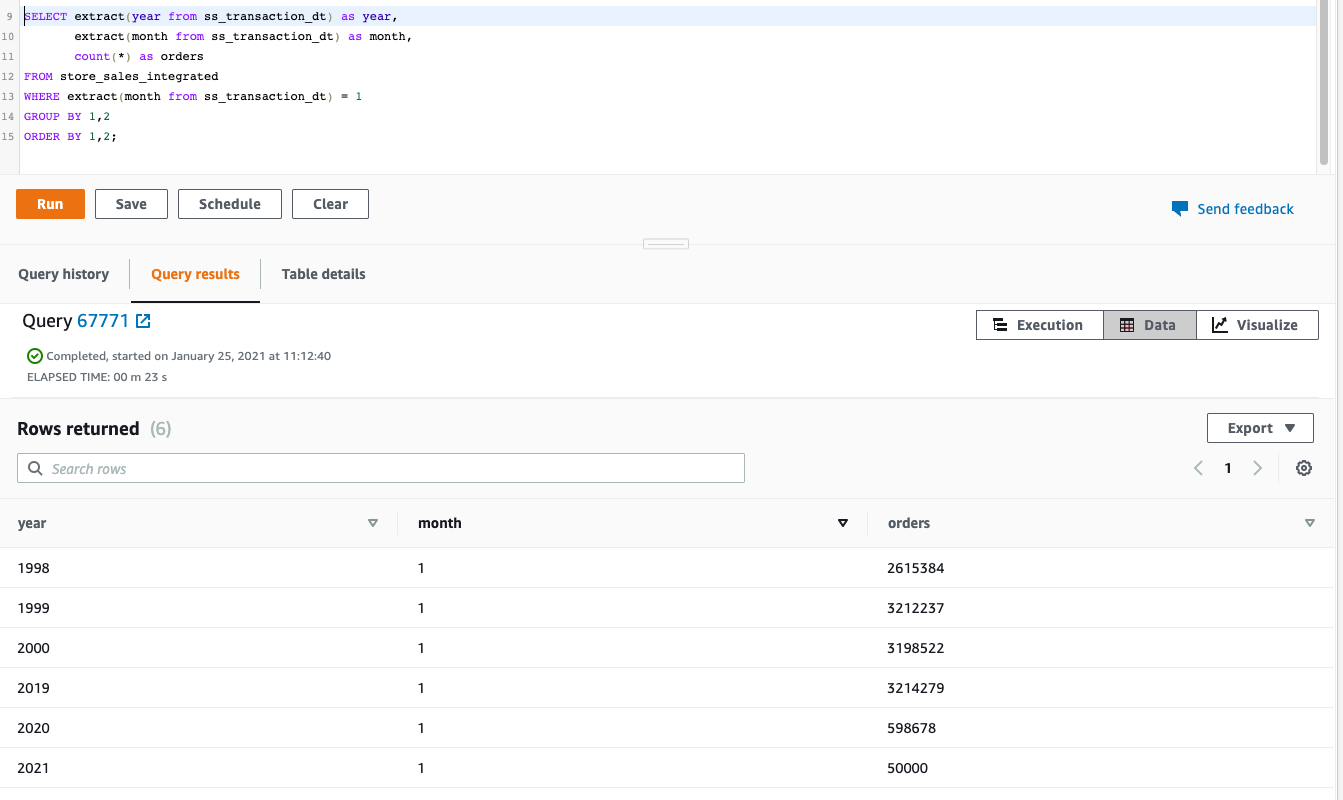
Miguel wants to find total sales of an item for a given month of each year regardless of where the data is stored. E.g. the historical sales data is stored in S3, Recent data is stored in Redshift and current month data is stored in the OLTP Postgres database.
1998 to 2000 data is coming from the S3 Data Lake. 2019 and 2020 data is coming from Redshift. While the current year data is coming from postgres ODS. |
Execute the following SQL statement
|
|
Before you Leave
Run this query in Redshift to reset your demo to the start:
DROP MATERIALIZED VIEW IF EXISTS inventory_mv;
DROP VIEW store_sales_integrated;
DROP SCHEMA spectrum;
Detach and delete the policy you created RedshiftPostgreSQLSecret-lab from the <RedshiftClusterRoleArn>.
You must detach the role or delete it in order to delete the stack from Cloud Formation otherwise it will fail
If you are done using your cluster, please think about deleting the CFN stack or to avoid having to pay for unused resources do these tasks:
- pause your Redshift Cluster
- stop the Oracle database
- stop the DMS task