Redshift Serverless TPC-DS
Before you Begin
- When performing this demo with an Isengard account, it must be one eligable for the Field Demo Program (FDP).
- Make sure you have a Key Pair created in the us-east-1 region and you have the Private Key saved on your computer.
- Next, launch the following Stack which will create a Redshift Serverless Workgroup and an EC2 instance to act as a Jumpbox.

Client Tool
For this demo, we will use the psql client that will be installed on the Jumpox. The CloudFormation template will configure the security settings for you automatically.
Challenge
Marie is Red Import’s Data Engineer. Marie would like to use the TPC-DS benchmark to validate the performance and SQL completeness of Redshift Serverless. She would like to test different scale factors as well to understand how Redshift Serverless handles different dataset sizes. Lastly, Marie would like to test the performance of having concurrent sessions executing the TPC-DS queries to understand how Redshift Serverless manages higher levels of concurrency.
Marie would like to leverage the open source project that provides the TPC-DS benchmark queries for Amazon Redshift found here.
To solve this challenge, Marie will deploy a Redshift Serverless Workgroup and EC2 instance (Jumpbox) using a CloudFormation template. Next, Marie will subscribe to an AWS Data Exchange (ADX) product listing which already has 1GB to 10TB of TPC-DS data available for free in Redshift. Marie will then leverage the Github project which contains the 99 TPC-DS queries and runner scripts that are compatible with Redshift. The scripts will output the execution times of each query, the time for all single-user queries, the total time spent on multi-user queries, and the total time spent for the test.
Subscribe
| Say | Do | Show |
|---|---|---|
| Marie first needs to subscribe to the TPC-DS product listing in the AWS Marketplace. This is a Data Exchange product listing that is free of charge and is delivered with a Redshift data share. Architecturally, this is the same as Redshift Data Sharing that you can do between your Redshift clusters and even between accounts. | Go to AWS Marketplace and search for “tpc-ds benchmark data”. |
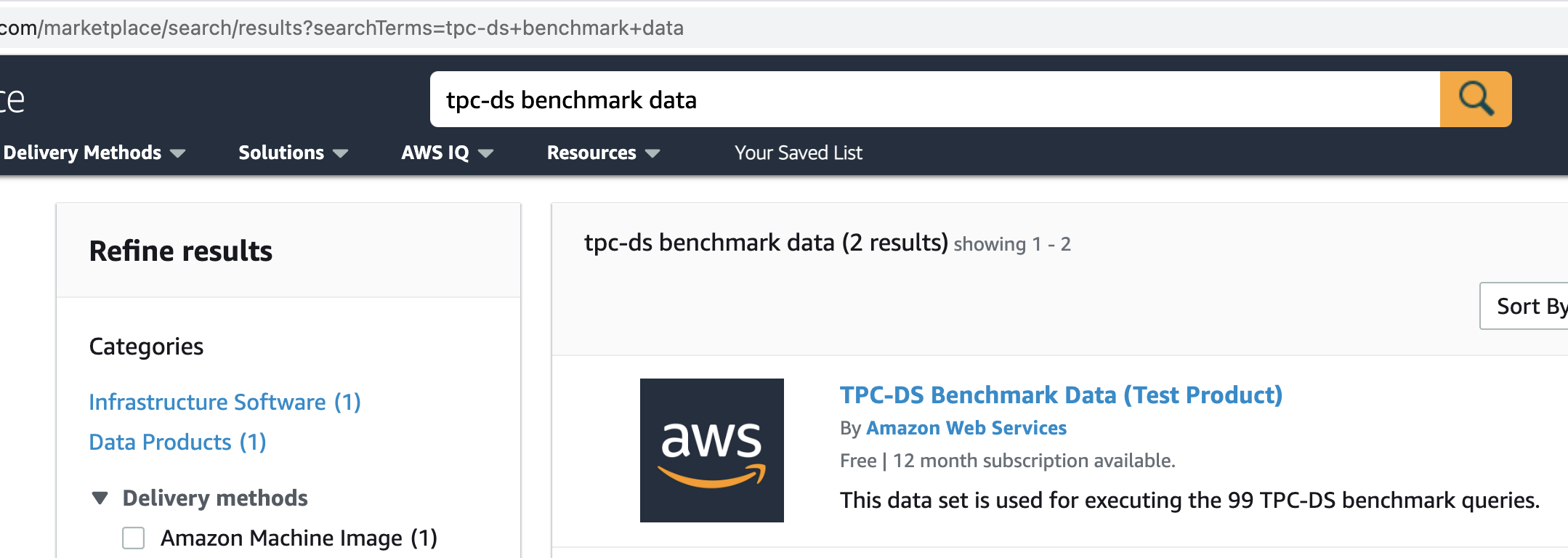
|
| Marie now needs to click “Continue to subscribe” in order to subscribe to the free product listing. | Click on the Subscribe button if not already subscribed. Be sure to use an account is allowed for the Field Demonstration Program. redshift-specialist-amer is allowed for FDP. |
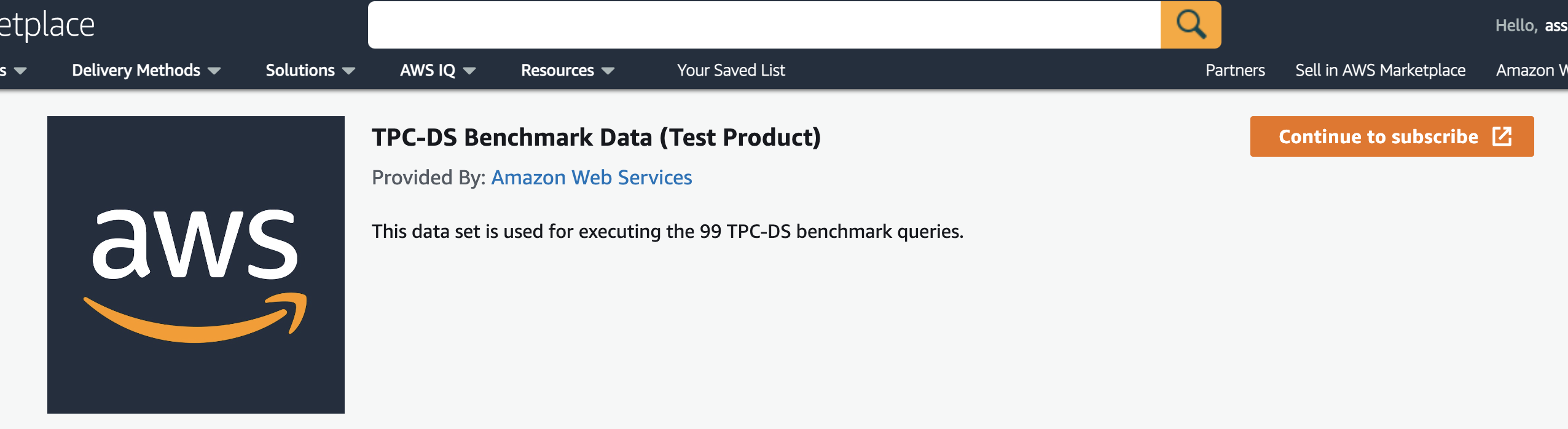
|
Jumpbox
| Say | Do | Show |
|---|---|---|
| Marie needs to connect to the Jumpbox with her private key. The Jumpbox provides a way for Marie to connect to the Redshift Serverless Workgroup without directly exposing the database to the Internet. | SSH to the Jumpbox. |
|
Marie now wants to start using the data share made available by simply subsccribing to the Amazon Data Exchange product listing. The Jumpbox is preconfigured by the CloudFormation Template, she only needs to type psql to connect to the database.
|
Start psql client. |
|
ADX Setup
| Say | Do | Show |
|---|---|---|
| Marie just needs to run a simple query to get the Share Name, Producer Account, and the Producer Namespace. These are needed for the next step. | Execute the following query with psql. |
|
| With the values retrieved from the previous step, Marie will create a database in her Redshift from the data share. The name of the data share should be “tpcds_datashare”. | Execute the following query with psql and plug the values in from the previous step. |
|
| Marie’s last step for configuration of ADX is to create the External Schemas. Each schema represents a different scale factor for TPC-DS. The smallest is 1GB and the largest is 10TB. |
Execute the following sql with psql. |
|
| Marie now needs to set the database search_path so that it uses the external schema of her choosing. |
Pick a scale factor of 1, 10, 100, 1000, 3000, or 10000. The larger the scale factor, the longer it will take to run the query. |
|
| Marie is now done using psql for configuring the TPC-DS Data Share that is made available through the AWS Data Exchange (ADX). |
Exit psql with |
|
Run Queries
| Say | Do | Show |
|---|---|---|
| Marie can now run one of the 99 TPC-DS queries from the benchmark. The queries already available on the Jumpbox so she just needs to go to the correct directory and exeucte the query. Marie notes that the first time she runs a query, it can take a little bit longer than subsequent executions as the data is “cold” and not cached yet. |
Change to directory ~/redshift-benchmarks/adx-tpc-ds/02_sql
|
|
| Marie notes that the first time she runs a query, it can take a little bit longer than subsequent executions as the data is “cold” and not cached yet. | Run the query 2 times in a row. |
|
| Marie notices the EXPLAIN variable and sees that she can gather the explain plan using this variable. | Run the following command to display the explain plan. |
|
Configure Benchmark
| Say | Do | Show |
|---|---|---|
| Marie now wants to test running all 99 queries in the benchmark as well as 5 concurrent users. She knows that TPC-DS multi-session test uses the same query templates for all 99 queries but with different filters to better simulate concurrent activity. | Go to directory ~/redshift-benchmarks/adx-tpc-ds and edit tpcds_variables.sh
|
|
| Marie has decided on using the 1TB dataset for the test and with 5 concurrent users so she edits the variables file accordingly. | Update the variables as shown. |
|
Option 1: Demo the Benchmark
| Say | Do | Show |
|---|---|---|
Marie now wants to run the entire benchmark so she runs the rollout.sh script.
|
Execute the command. |
|
| Marie monitors the progress of the script by tailing the file. | Execute the command. |
|
| Marie sees that the script has finished and observes the execution times of all 99 queries, the total time for all 99 queries, the total time for the concurrent users, and finally the total time for the entire benchmark test. | Execute the command. |
|
| Marie observes that the total time spent running the 99 queries was more than running 5 concurrent users. She realizes that this is because querying the data with one user, warmed the local cache of the data share. Subsequent queries of this data will be faster. | Analyze the results. |
|
| If time allows, Marie would like to run the entire benchmark again. When she does this, she observes even better performance and this is because the data is warm. | Analyze the results. |
|
Option 2: Solo Execution of Benchmark
| Say | Do | Show |
|---|---|---|
| Instead of demonstrating the demo to you, you can execute the demo on your own in your own AWS account. The CloudFormation Teamplte and Github repository with all of the scripts are publicly available. | Go to GitHub and show the README file directions. |
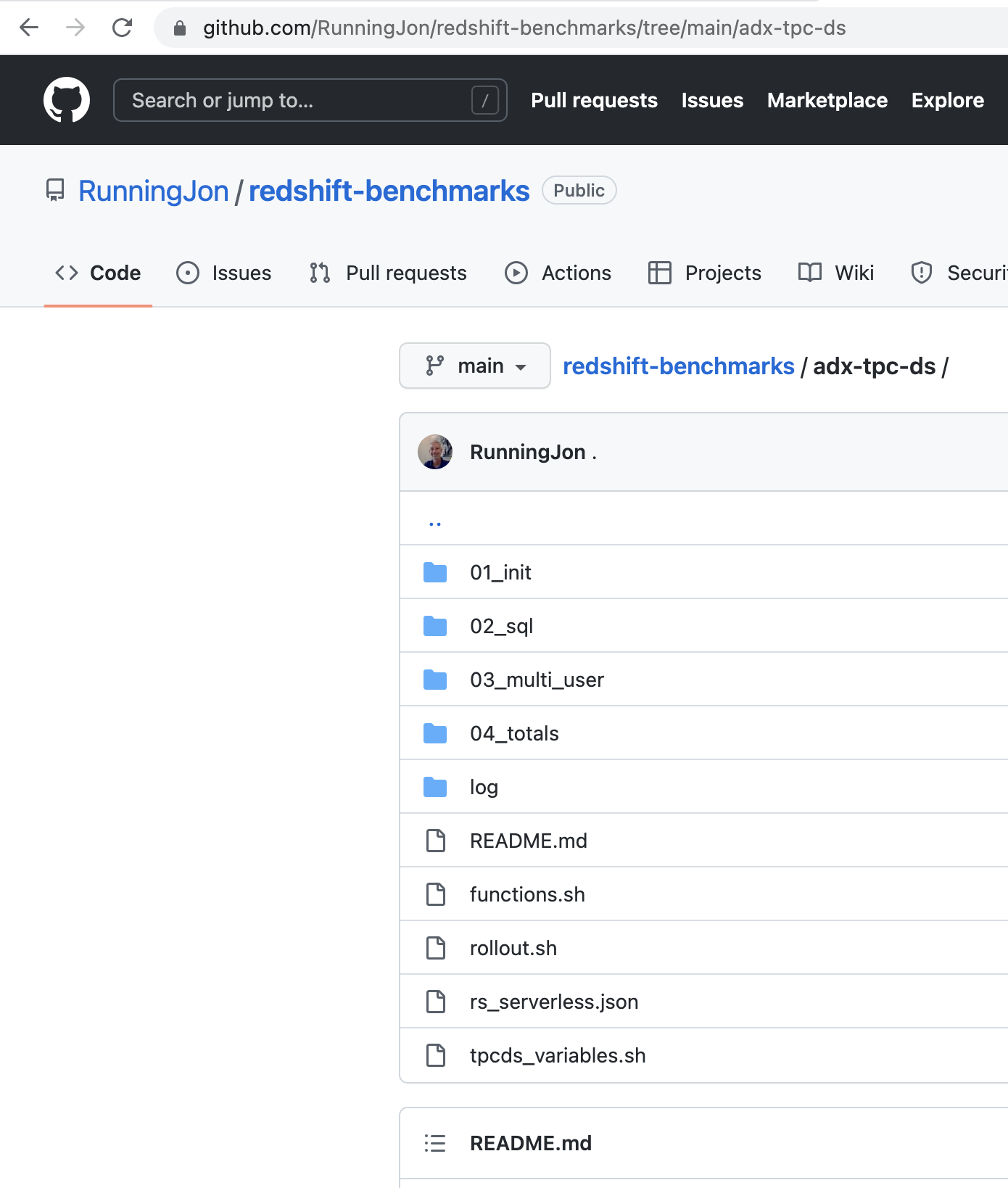
|
| Here is the CloudFormation Template that deploys the Jumpbox resource as well as the Redshift Serverless Workgroup. The CloudFormation template will install the psql client and download the GitHub repository on the Jumpbox for you just as it did in this demo. | Show rs_serverless.json. |
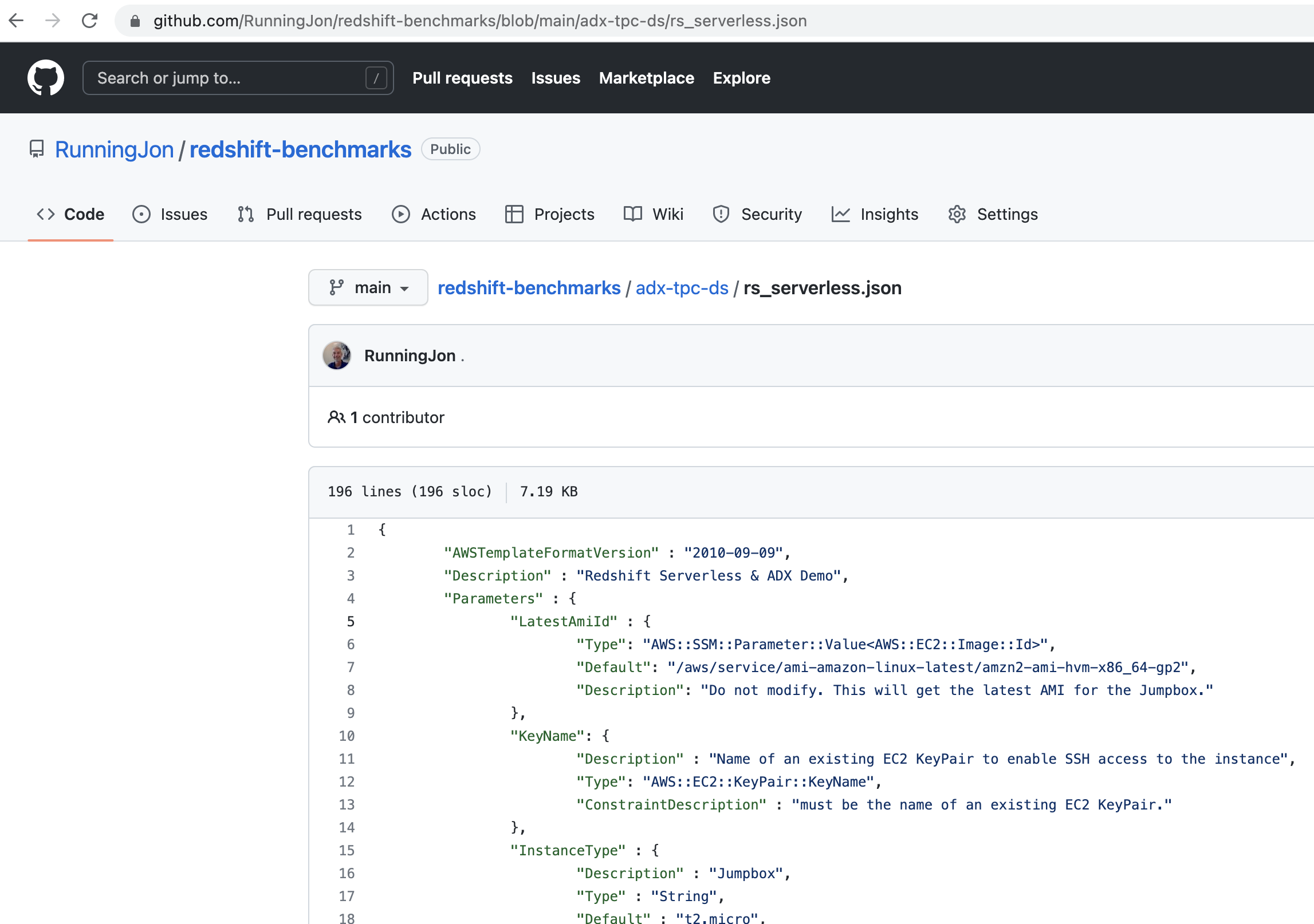
|
| The template is also available in an S3 bucket which makes it easier to use with CloudFormation. | Provide this url: https://redshift-demos.s3.amazonaws.com/rs_serverless.json |
|
Before you Leave
If you are done using your cluster, please think about deleting the CloudFormation Stack. This will remove the Redshift Workgroup and Endpoint as well as the Jumpbox resources.