Streaming Data Ingestion- Redshift Streaming Ingestion
Before you Begin
Use the following CFN template to launch the resources needed in your AWS account.

The stack will deploy Redshift serverless endpoint(workgroup-xxxxxxx) and also a provisioned cluster(consumercluster-xxxxxxxxxx). This demo works on both serverless and provisioned cluster.
Additionally run below stack for setting Kinesis data generator. Provide user id and password of your choice for data generator.
Capture the following output parameters from the above launched CloudFormation template as you will use them in the demo.
- KinesisDataGeneratorUrl
Client Tool
This demo utilizes the Redshift web-based Query Editor v2. Navigate to the Query editor v2.
Below credentials should be used for both the Serverless endpoint (workgroup-xxxxxxx) as well as the provisioned cluster (consumercluster-xxxxxxxxxx).
User Name: awsuser
Password: Awsuser123
Challenge
The data analyst Miguel needs to get realtime energy consumption and usage information from electric vehicle charging stations so he can build a dashboard showing energy consumption and number of connected users over time. He asks Marie to build an ingestion pipeline to load the latest data into the Redshift data warehouse. The architecture of the new pipeline will look like the following:
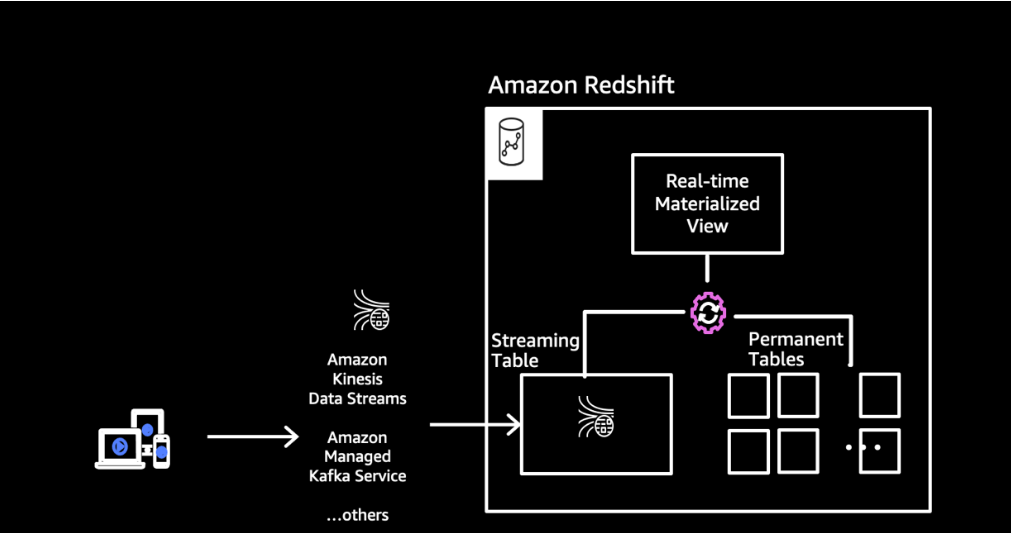
To solve this challenge Marie will do the following:
- Create a Kinesis data stream
- Generate streaming data with the Kinesis Data Generator
- Load reference data
- Create a materialized view
- Query the stream
Create Kinesis data stream
| Say | Do | Show |
|---|---|---|
|
First, Marie must create a Kinesis data stream to receive the streaming data. |
|
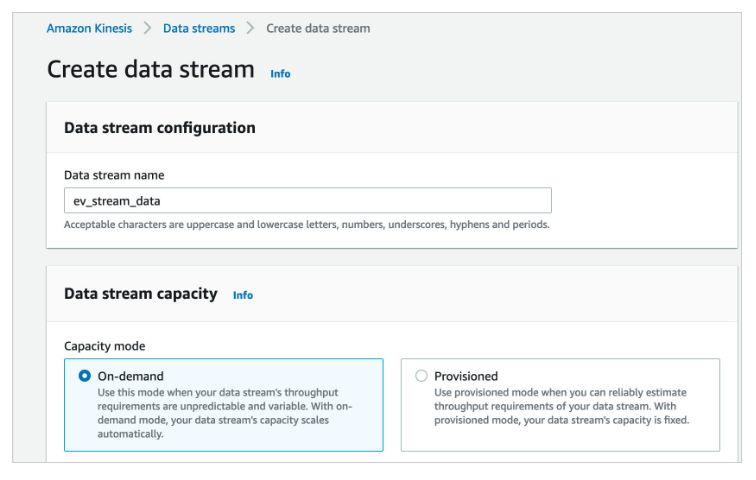
|
Load Reference Data
| Say | Do | Show |
|---|---|---|
| Marie also wants to load reference data related to electric vehicle charging stations to the Redshift cluster. |
Marie runs following create table command using Redshift query editor v2 .
|
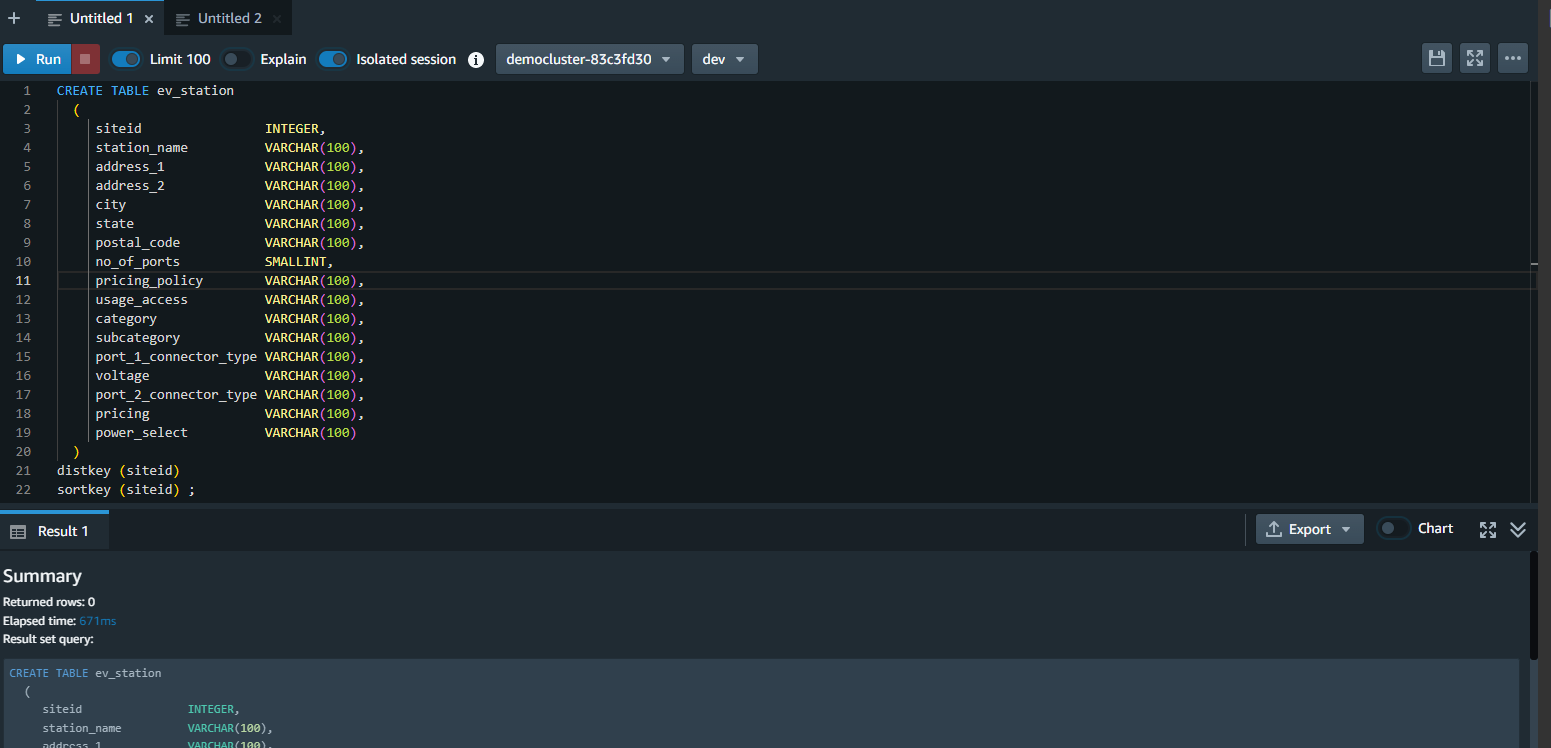
|
| Next Marie will load data from S3 bucket. |
Marie uses Redshift copy command to load data from S3 bucket
|
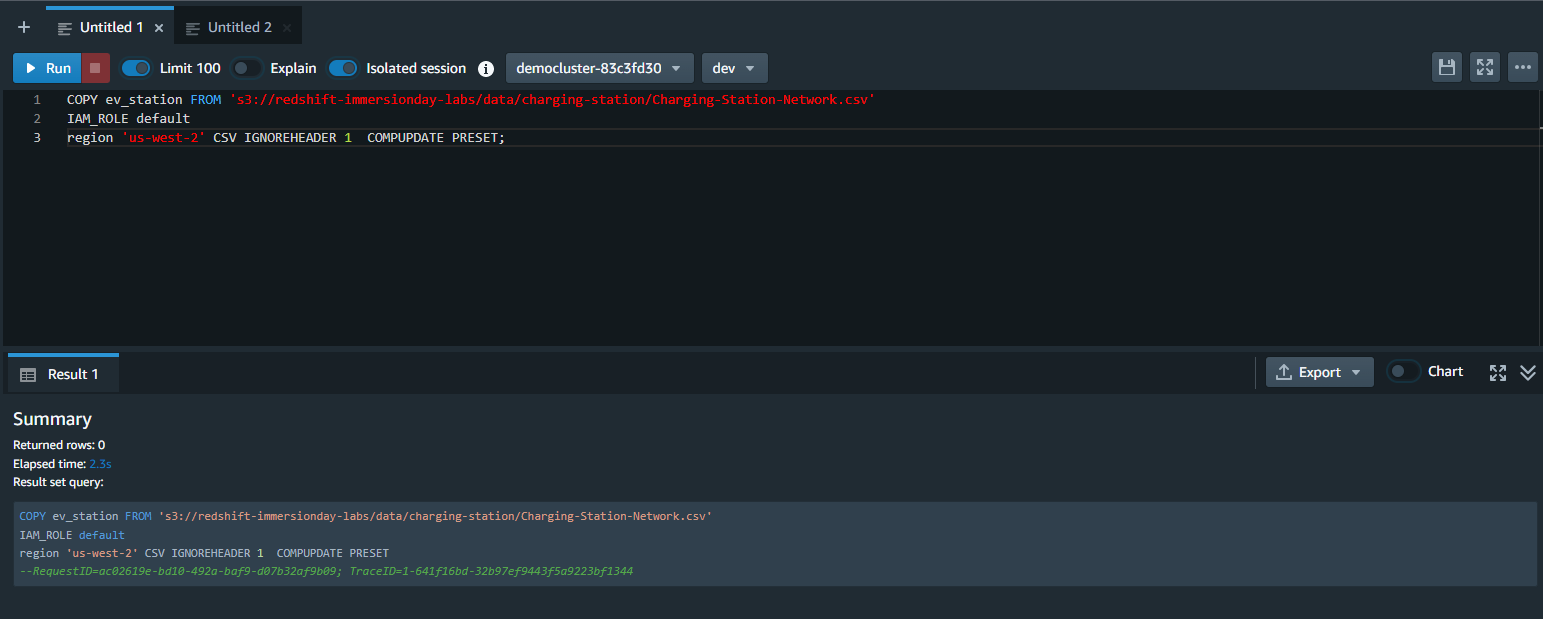
|
Amazon Kinesis Data Generator
| Say | Do | Show |
|---|---|---|
| Marie wants to create synthetic data simulating electric vehicle charging station usage and sending it into the stream using the Kinesis Data Generator. | Launch KDG Tool by clicking URL extracted from cloudformation stack ‘Kinesis-Data-Generator-Cognito-User’, provide a Username and Password for the user. |
|
| Now that Marie is able to login to KDG tool, she wants to start streaming EV data to Kinesis Data Stream ‘ev_stream_data’. |
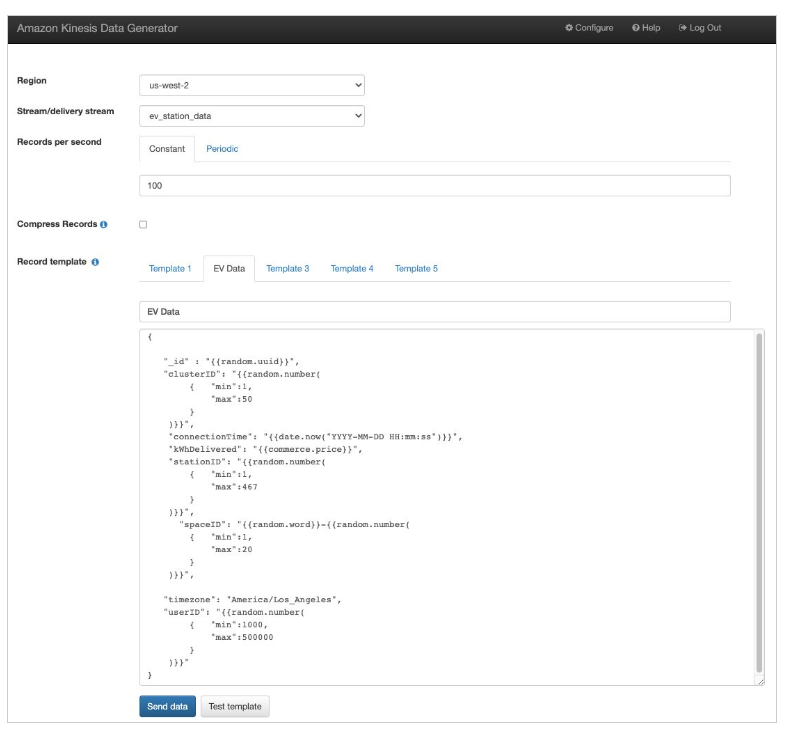
Marie selects region and delivery stream she created. She copies the EV Data template below and paste it into KDG and selects Send Data.
|
|
Create a materialized view
Amazon Redshift streaming ingestion uses a materialized view, which is updated directly from the stream when REFRESH is run. The materialized view maps to the stream data source.
| Say | Do | Show |
|---|---|---|
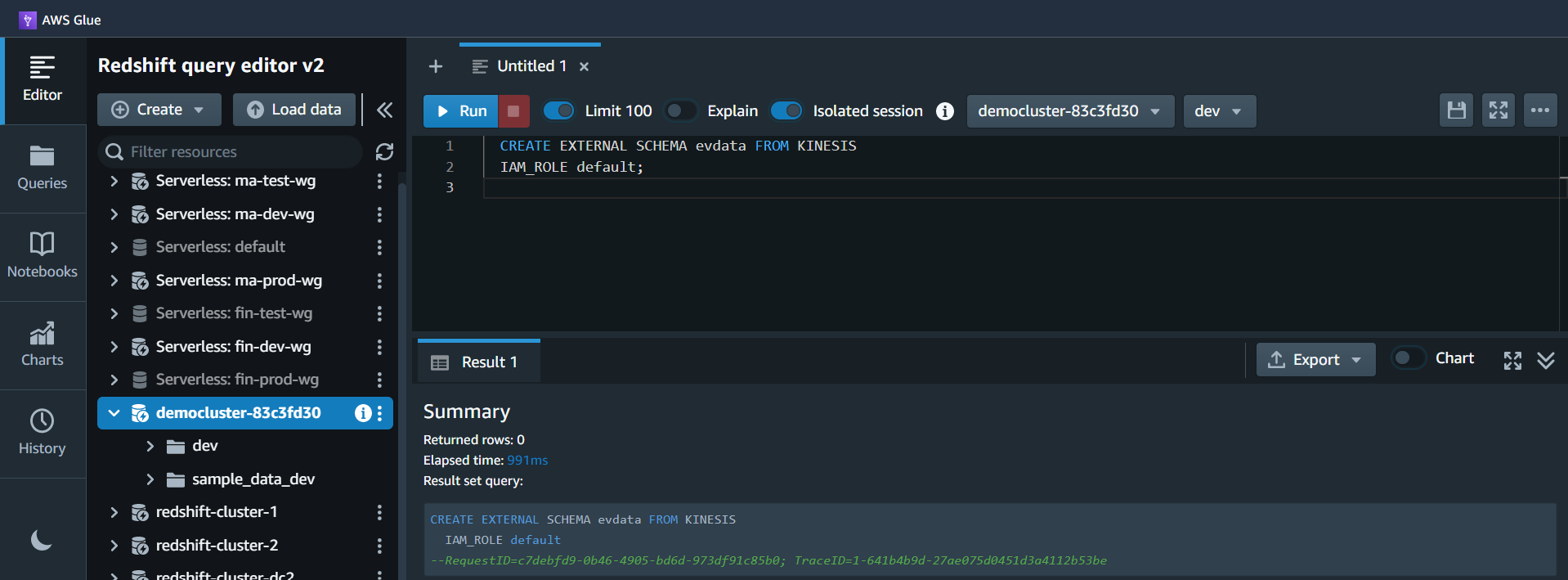
| As a next step Marie define a schema in Amazon Redshift with ‘create external schema’ to reference a Kinesis Data Streams resource |
Using your Redshift query editor v2, execute the following statement. |
|
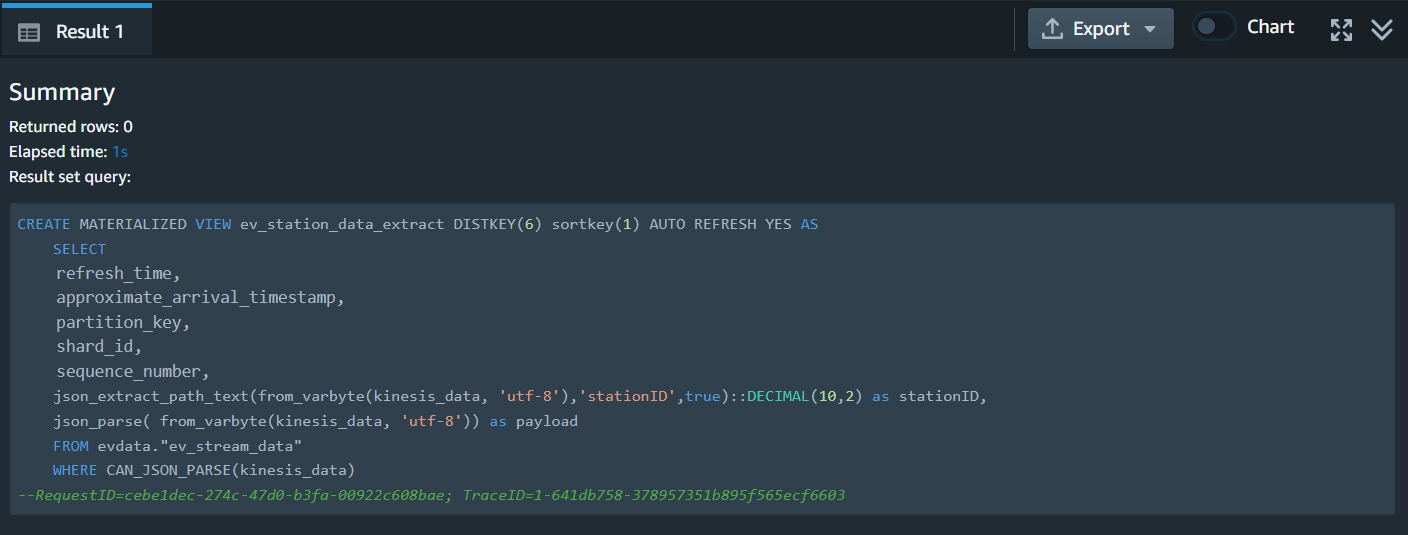
| Now Marie will create a materialized view to consume the stream data. The materialized view is auto-refreshed as long as there is new data on the KDS stream. She can also disable auto-refresh and run a manual refresh or schedule a manual refresh using the Redshift Console UI. |
Using your Query editor v2, execute the following statement. |
|
Query the stream
With SUPER data type and the PartiQL language, Amazon Redshift expands data warehouse capabilities to natively ingest, store, transform, and analyze semi-structured data. You can use PartiQL dynamic typing and lax semantics to run your queries and discover the deeply nested data you need, without the need to impose a schema before query.
| Say | Do | Show |
|---|---|---|
| Marie wants to now validate the data is loading into Redshift from “ev_stream_data” stream. First see need to enable ‘enable_case_sensitive_identifier to TRUE to handle upper case or mixed case JSON fields. |
Using your Redshift query editor v2, execute the following statement. |
|
| Next Marie runs following query to see payload data stored as SUPER Datatype in materialized view. |
Using your Redshift query editor v2, execute the following statement. |
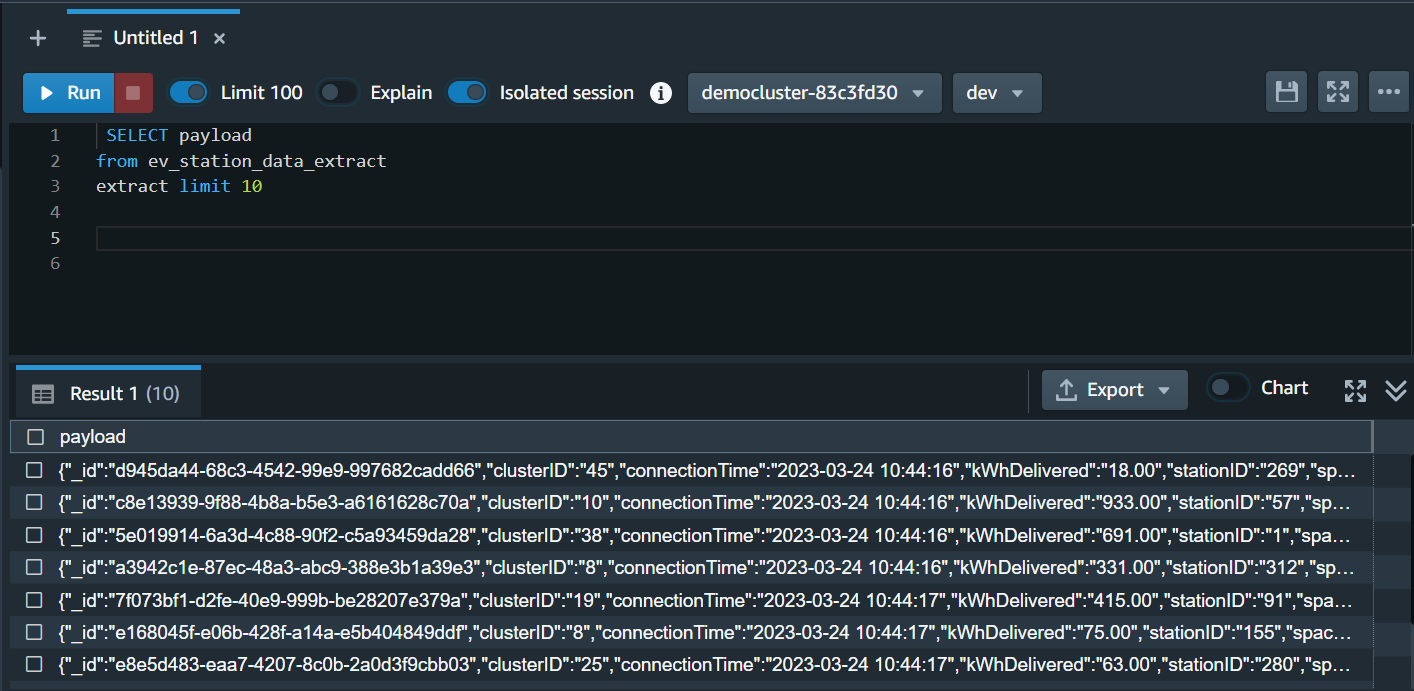
|
|
Marie can also query the refreshed materialized view to get usage statistics. She can re-run query multiple times to get new data, published by Kinesis Data Stream. |
Using your Redshift query editor v2, execute the following statement.
|
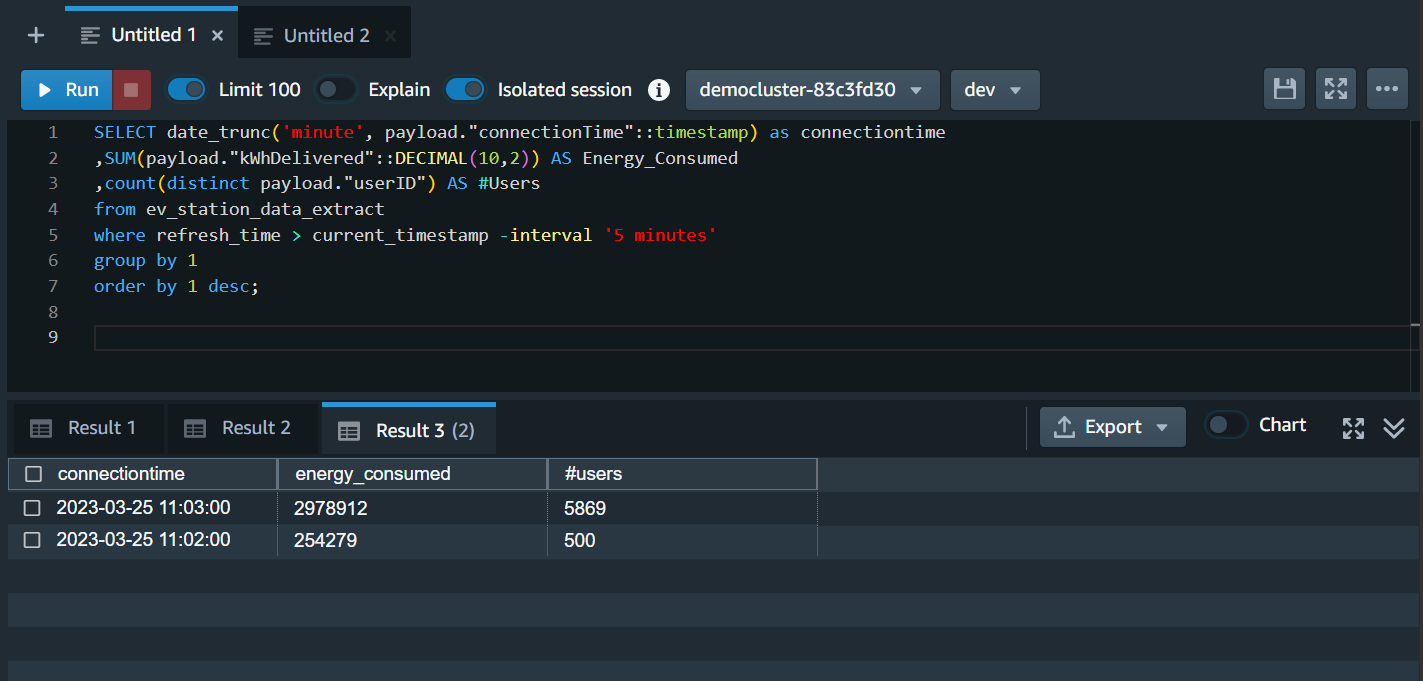
|
|
Marie also wants to add reference data for Miguel’s analysis. She can get reference data by joining materialzed view with ev_station reference table. |
Using your Redshift query editor v2, execute the following statement. This will return charging station consumption data for the last 5 minutes and break it down by station category. |
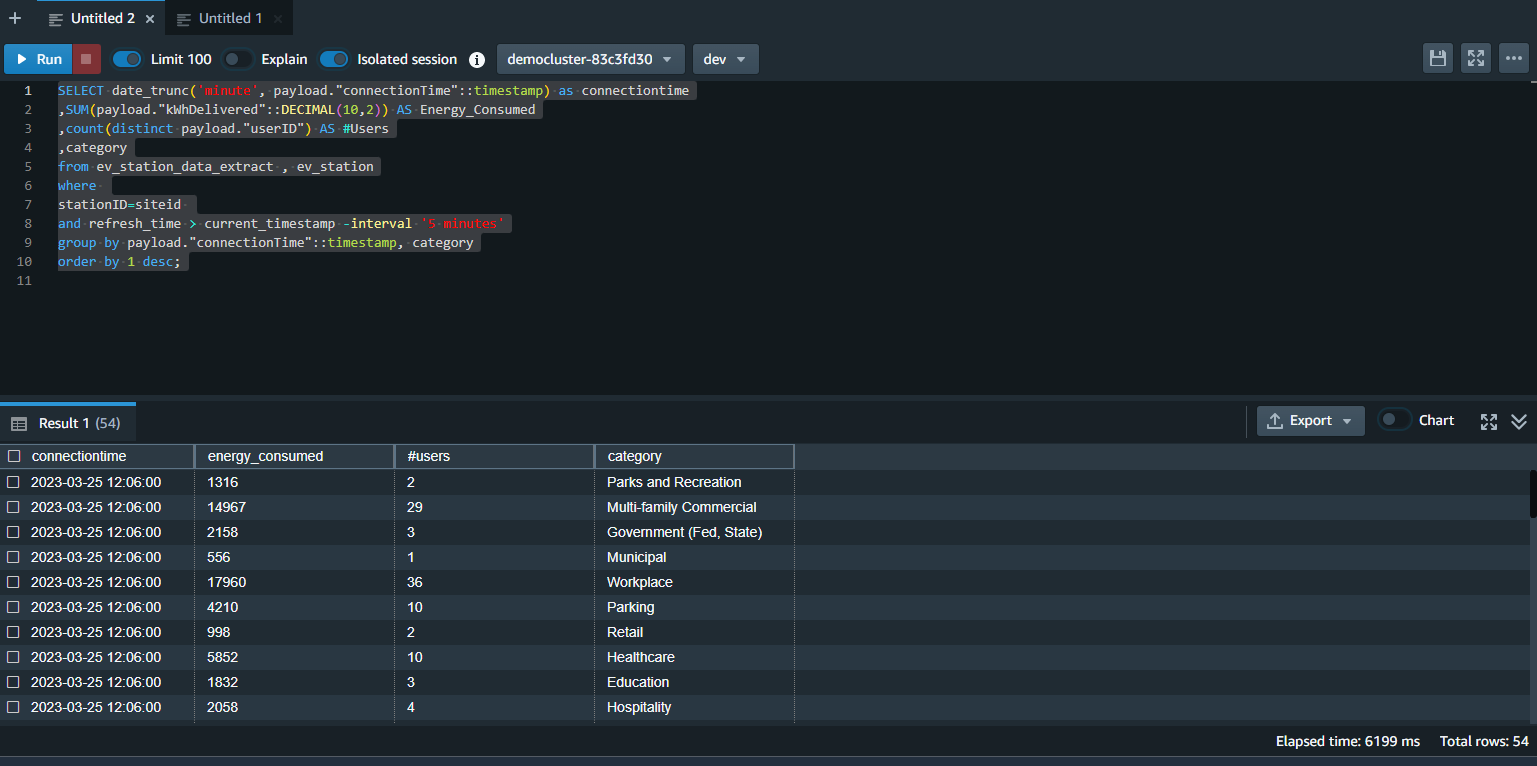
|
Before you Leave
If you are done using your cluster, please think about deleting the CFN stack or Pausing your Redshift Cluster to avoid having to pay for unused resources.