OLAP Constructs - ROLLUP, CUBE, and GROUPING SETS
Before you Begin
Use the following CFN template to launch the resources needed in your AWS account.

The stack will deploy Redshift serverless endpoint(workgroup-xxxxxxx) and also a provisioned cluster(consumercluster-xxxxxxxxxx). This demo works on both serverless and provisioned cluster.
Client Tool
This demo utilizes the Redshift web-based Query Editor v2. Navigate to the Query editor v2.
Below credentials should be used for both the Serverless endpoint (workgroup-xxxxxxx) as well as the provisioned cluster (consumercluster-xxxxxxxxxx).
User Name: awsuser
Password: Awsuser123
Challenge
Miguel has recently been tasked to perform multi-dimensional analysis on supplier data. He needs to write complex aggregation logic for finding totals, sub total of supplier account balances at nation level, region level and for each of the combinations.
ROLLUP, CUBE and GROUPING SETS are SQL aggregation extensions that allow her to perform multiple GROUP BY operations in the same statement. With these new SQL constructs GROUPTING SETS, ROLLUP and CUBE, he can avoid complex data processing code in the applications and also help improve your performance.
He took a sample from the result of the following query run on TPC-H dataset.
select s_suppkey supp_id, r.r_name region_nm,n.n_name nation_nm, s.s_acctbal acct_balance
from supplier s, nation n, region r
where
s.s_nationkey = n.n_nationkey
and n.n_regionkey = r.r_regionkey
Create table and load data
| Say | Do | Show |
|---|---|---|
|
Miguel needs to create the table structures that will hold the sales data. Create a supplier sample table and insert sample data. |
Create the tables as below:
| |
| Let us start by first reviewing the sample data before running the SQLs using GROUPING SETS, ROLLUP, and CUBE extensions. It has list of suppliers , region, nation and their account balances. |
|
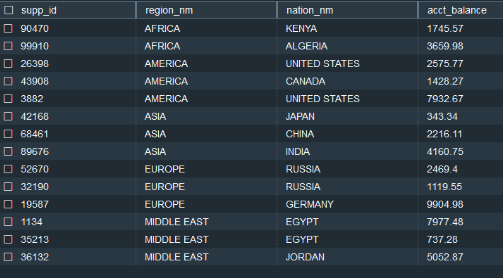
|
Analyze data
| Say | Do | Show |
|---|---|---|
|
GROUPING SETS Group data multiple different ways. GROUPING SETS can be used instead of performing multiple select queries with different GROUP BY keys and merge (i.e., Union) their results. Below query groups data by both region_nm and nation_nm.In this section, we will show how to find out
by running single SQL statement using GROUPING SETS. |
|

|
|
ROLLUP Group data by particular columns and get extra rows that represent the subtotals. ROLLUP assumes a hierarchy among the GROUP BY columns. In this section, we will show how to find out
The rows with a value for region_nm and NULL value for nation_nm represent the subtotals for the region (marked in green). The rows with NULL value for both region_nm and nation_nm has the grand total—the rolled-up account balances for all regions (marked in red). |
|
|
|
CUBE Similar to ROLLUP, CUBE will group data by particular columns and get extra rows that represent the subtotals. Also, it will generate subtotals for all combinations of grouping columns. In this section, we will show how to find out
in single SQL statement using CUBEYou can see the subtotals at region level (marked in green). These subtotal records are the same records generated by ROLLUP. Additionally, CUBE generated subtotals for each nation_nm (marked in yellow). Finally, you can also see the grand total for all three regions mentioned in the query (marked in red) |
|

|
| NULL is a valid value in a column that participates in a GROUPING SET/ROLLUP/CUBE and it is not aggregated with the NULL values added explicitly to the result set to satisfy the schema of returning tuples. Below is an example with a ROLLUP, where the NULL value of an input column and the NULL values added explicitly to the output are highlighted in green and red, respectively. |
– Create example orders table and insert sample records –View the data |
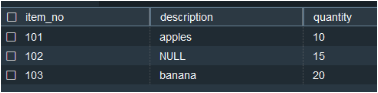
|
| Run rollup query on the data with NULLs. Observe that there are two output rows for item_no 102 . |
|

|

Before you Leave
Execute the following to clear out any changes you made during the demo to reset it.
DROP TABLE IF EXISTS supp_sample;
If you are done using your cluster, please think about deleting the CFN stack or to avoid having to pay for unused resources do these tasks:
- pause your Redshift Cluster
- stop the Oracle database
- stop the DMS task