Netezza Migration
Demo Video
Coming soon!
Before you Begin
Netezza is a hardware appliance offering from IBM. In this demo, we will simulate Netezza using a software emulator deployed on VMware workstation. The emulator only functions properly when run on a bare metal instance. Therefore, you must run the Cloud Formation template on a bare metal instance before proceeding on this page. Also note that bare metal instances are more expensive so there might be an increased cost associated with this demo.
Switching to a bare metal instance
Click the launch button below to run the CloudFormation template on bare metal. If you have already run the main template before landing on this page, please consider deleting it to avoid double charges and runtime networking errors.

Capture the following parameters from the previously launched CloudFormation template as you will use them in the demo.
https://console.aws.amazon.com/cloudformation/home?region=us-east-1#/stacks?filteringText=&filteringStatus=active&viewNested=true&hideStacks=false
- EC2DeveloperPassword
- EC2HostName
- EC2LoginUserName
- RedshiftClusterDatabase
- RedshiftClusterEndpoint
- RedshiftClusterPassword
- RedshiftClusterPort
- RedshiftClusterUser
- TaskDataBucketName
- VpcId
- SubnetAPublic
- SecurityGroup
Additional information to note for this demo include:
- BaremetalEC2Username:
nz - BaremetalEC2Password:
nz - RootUsername:
root - RootPassword:
netezza - NetezzaAdminUsername:
ADMIN - NetezzaAdminPassword:
password - NetezzaServerPort:
5480
Starting the emulator
- Connect to the EC2 Instance from the AWS Console or SSH connection and use the credentials above.
- At the terminal prompt type
nzstateand hit return. You should get a responseSystem is 'Online'.If the database is not online use the below troubleshooting steps:- If database state is not
Online, runnzstart(it takes 10-15 mins for db to be in online status) - Re-check to see if database is online
- If it’s still having issues, execute
nzstopfollow command prompts to completely stop appliance and start database again withnzstart
- If database state is not
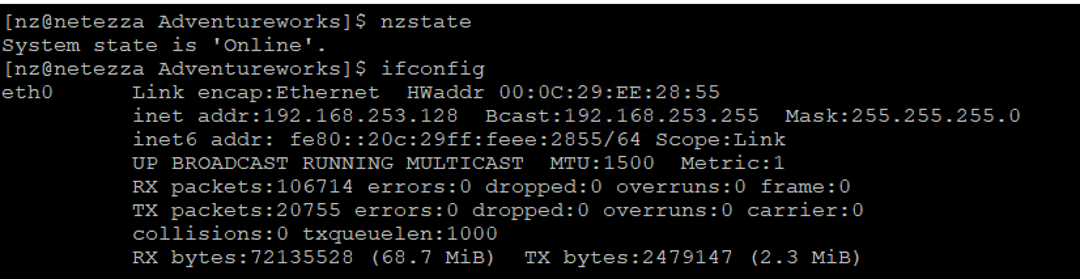
- At the terminal prompt type
ifconfigand hit return. You should see a network response like the one shown below confirming that your emulator has network access.- Note the IP address for eth0 for use in the demo
<<ipaddressNetezza>>
- Note the IP address for eth0 for use in the demo
Client Tool
If you do not have a Remote Desktop client installed, you can use the instructions at this link to do so.
Challenge
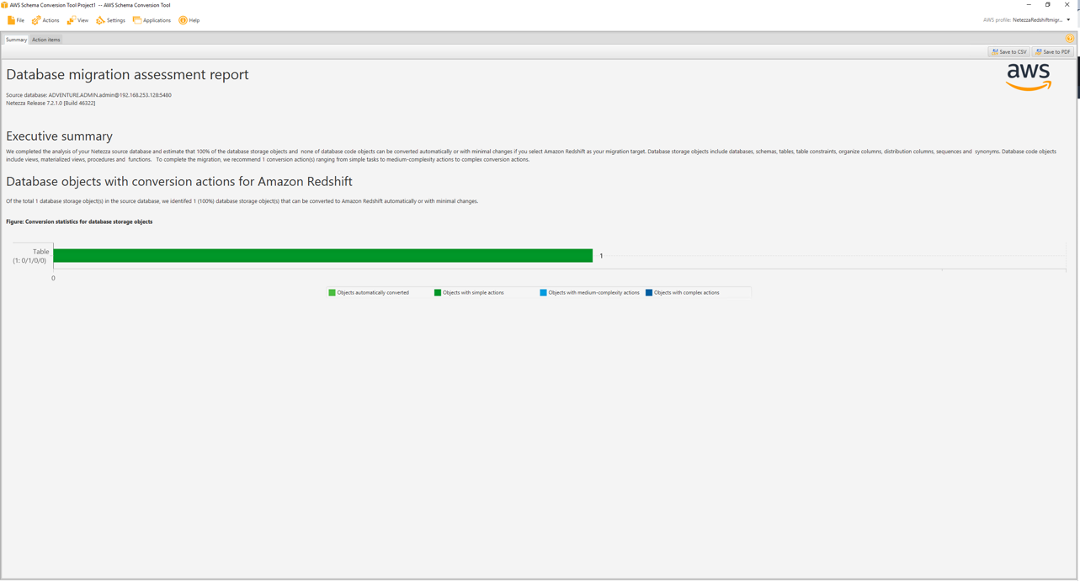
Marie has been asked to migrate Red Imports on-premises Netezza data warehouse (Adventureworksdw) to Amazon Redshift in their AWS account. The Netezza data warehouse hosts business critical applications in PL/SQL. She also needs to ensure that Redshift data warehouses are in sync until all legacy applications are migrated to Redshift. Marie will need to convert the DDL structures and PL/SQL code into Redshift and perform full load from Netezza to Redshift. Marie will also need to setup updates from Netezza to Redshift to keep the data in sync. Marie will accomplish these tasks by doing the following:
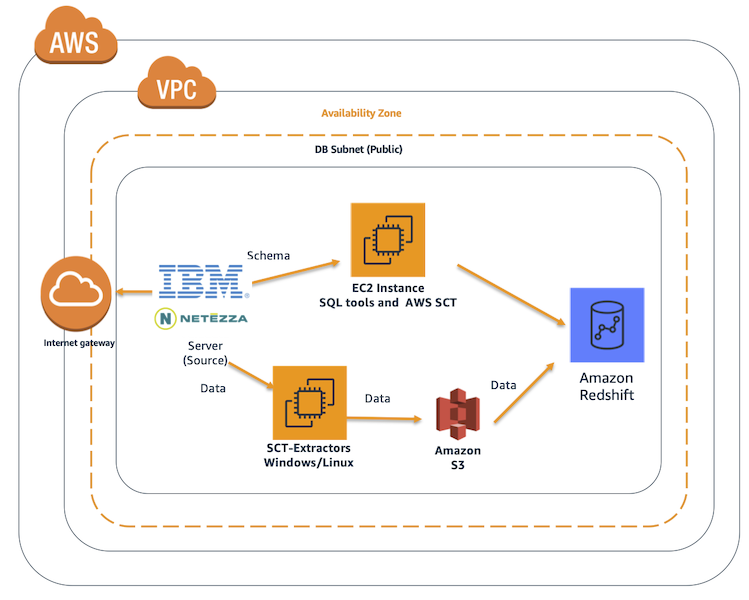
Convert the Schema
| Say | Do | Show |
|---|---|---|
|
Marie logs into her workstation, in which she has already installed the required tools like schema conversion tool for the migration, DBweaver (open source tool) to connect with Netezza and Redshift |
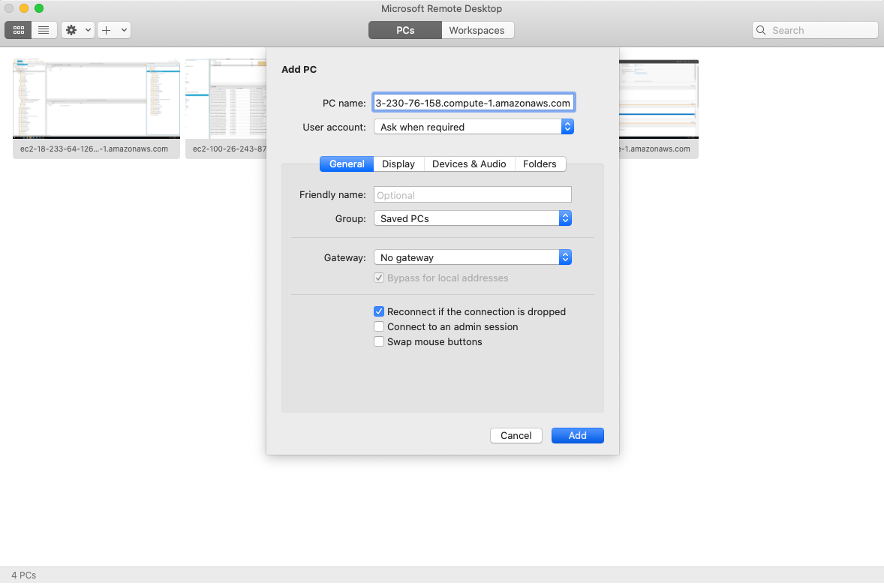
The cloud formation template deploys a Windows EC2 instance, with required drivers and softwares for AWS SCT, SQL Workbench. Before the demo, please note down all relevant parameters from the CloudFormation output that you’ll need to use in the subsequent steps. Connect to that EC2 instance using Remote Desktop client. |
|
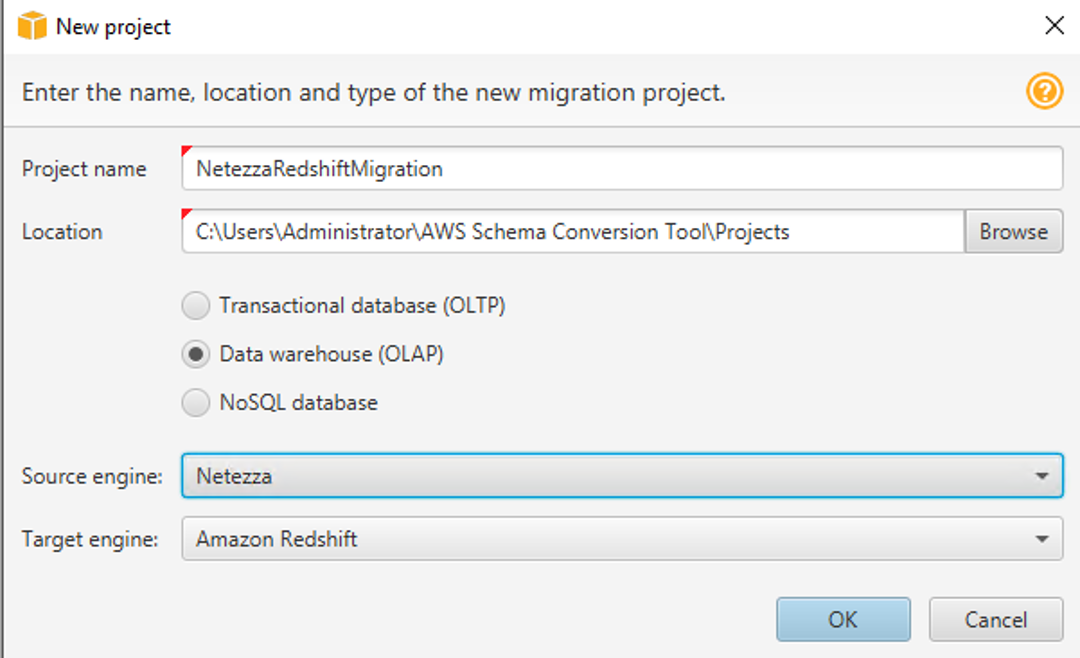
| Once logged in, she opens AWS Schema Conversion Tool and initiates a new project. She will select OLAP as it’s a data warehousing from Teradata to Redshift |
Open AWS SCT using the shortcut and click |
|
| Once logged in, she would need to update settings |
The Access key and Secret key used must have read write access to the S3 bucket you select. |
|
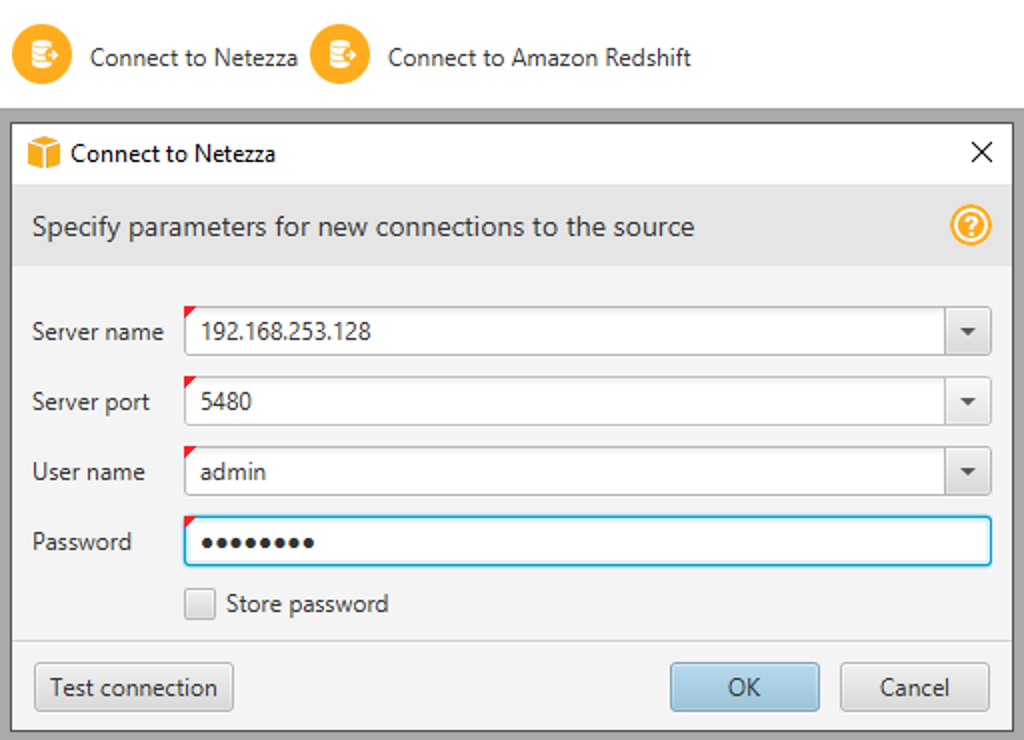
| Now she needs to configure the connectivity for Netezza OLAP database |
Click Click |
|
| By default, AWS SCT uses AWS Glue as ETL solution for the migration. Marie may not be using it for now. So, let’s disable it. |
Click |

|
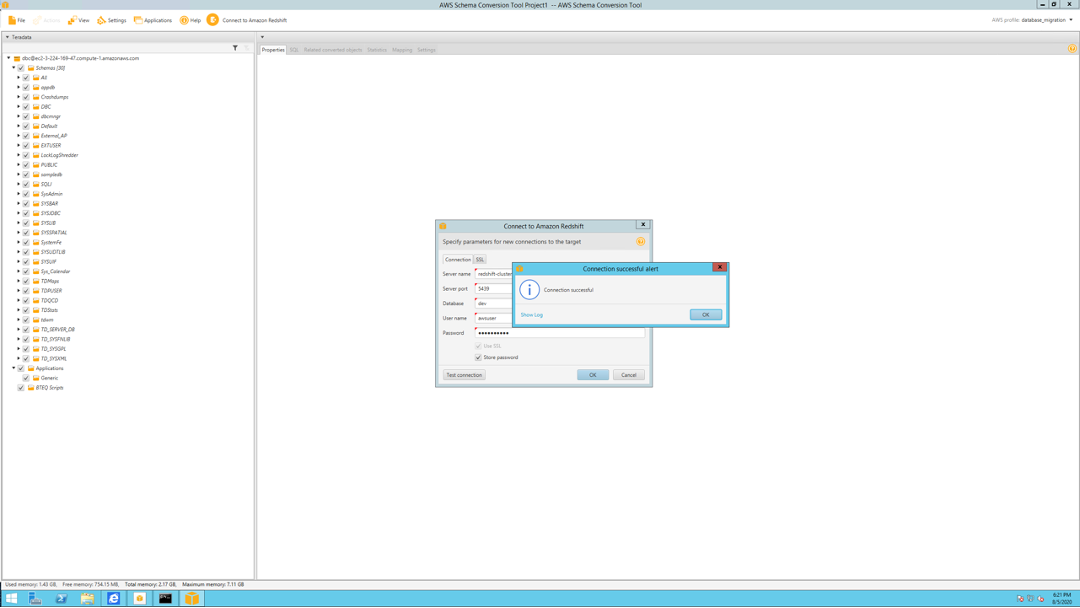
| Now, she needs to configure the connectivity for the target system, Redshift |
Input below parameters in the connection Tab: Click |
|
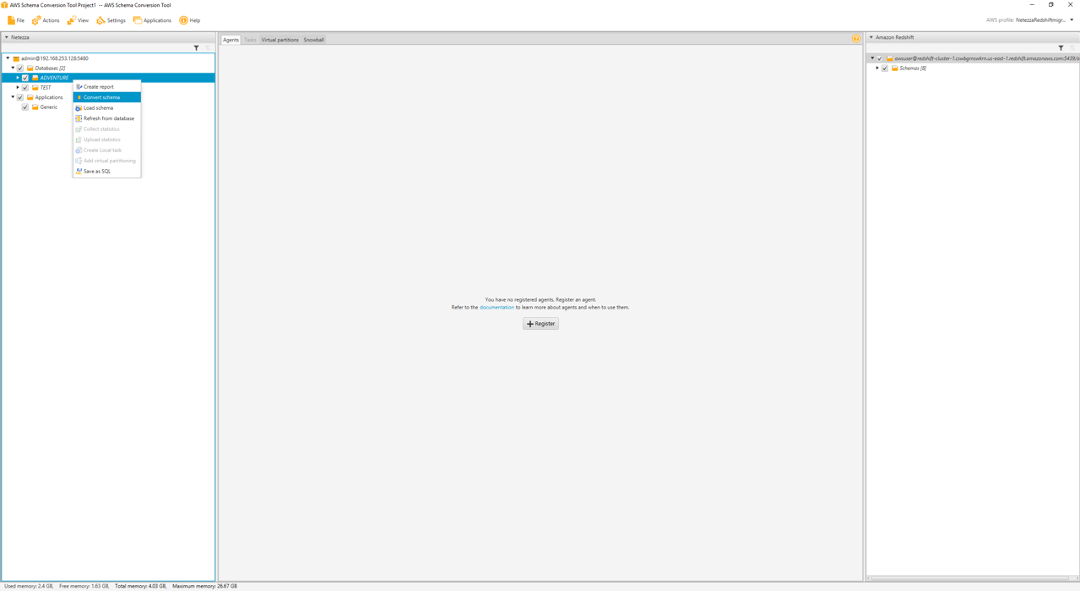
On the left hand side, she can see all the objects in Netezza and on the right hand side, all Redshift objects. She may now convert the Netezza schema adventure.
|
Right click |
|
| All Teradata objects got converted to Redshift syntax now. But there are some objects showing in Red here, which essentially means that SCT couldn’t fully migrate these objects. she can view an assessment summary for the migration |
Click |
|
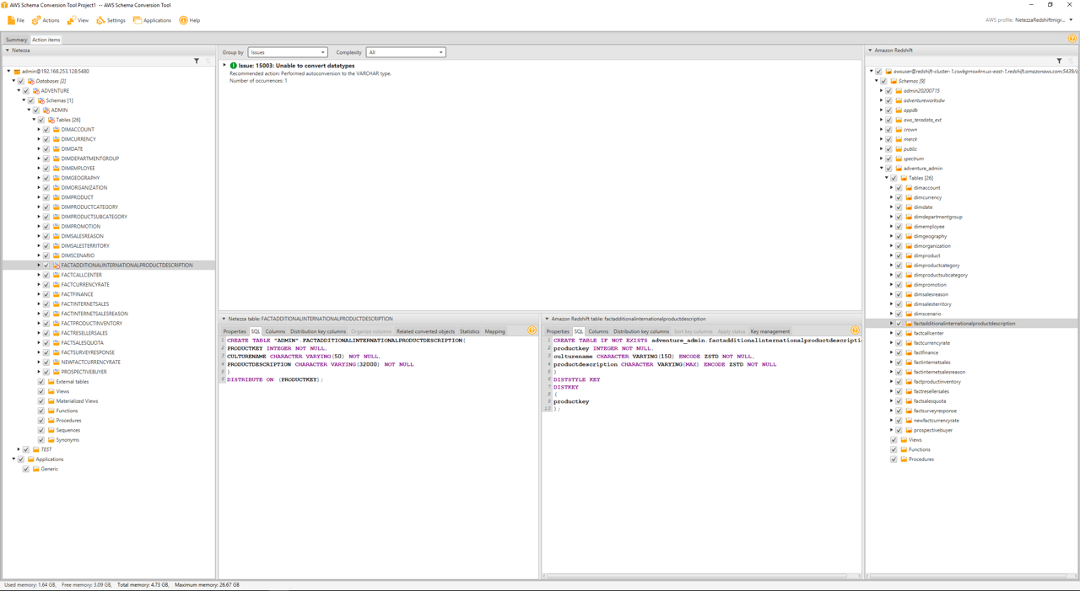
She can now look at specific actions she would need to take for the tables/constraints/views that could not be migrated to Redshift. She looks at the detail to find a mismatched data type in Factadditonalinternationalproductdescription table.
|
In the Migration assessment report click |
|
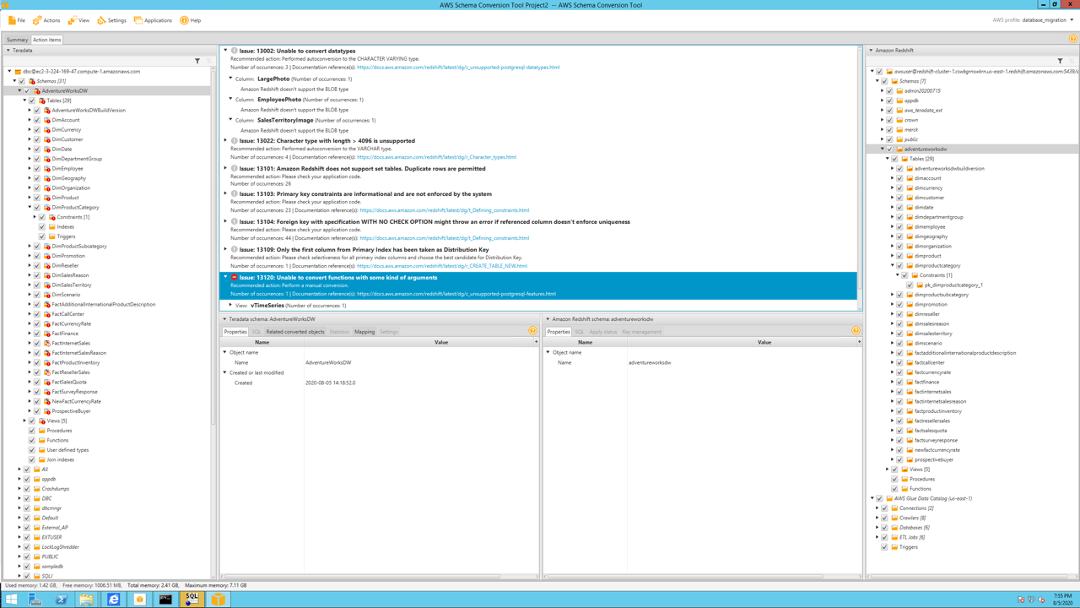
Marie goes through the issues and identifies any issues that would be of concern. For example, she finds, productdescription varchar(3200) was auto converted to a varying(max) in Redshift.
| Click the issues with a red icon in front of them, showing need for manual conversion |
|
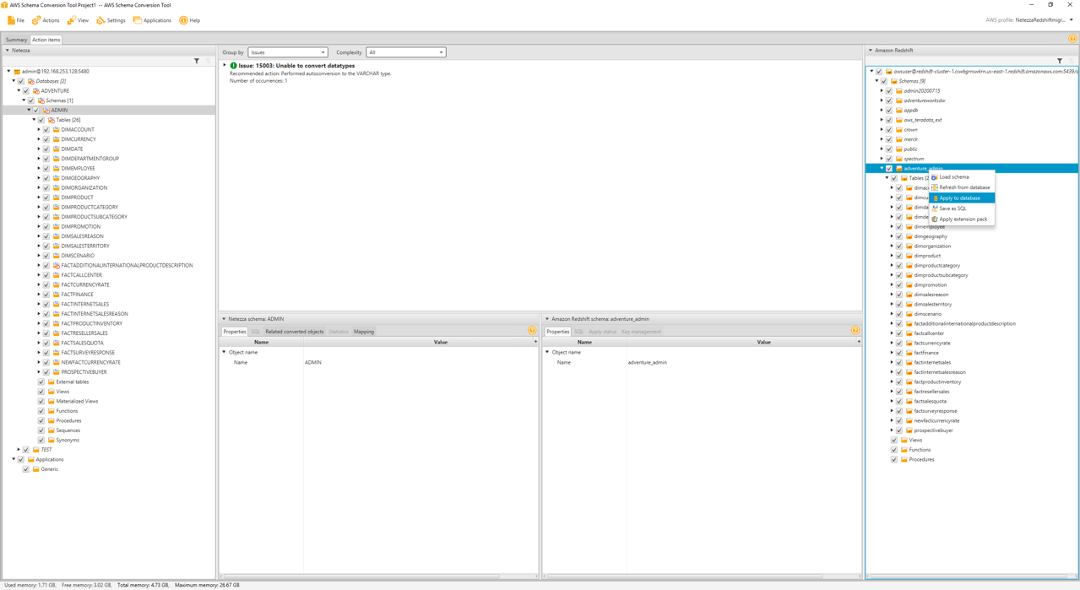
Now to successfully migrate the objects to Redshift. She would click the adventure schema on the right side and select apply to database.
|
Amazon Redshift > Select |
|
| Now, Marie will need to verify that the objects have been created in Redshift using an IDE like SQL workbench, which is an open source JDBC IDE. She will need to provide the driver path for Redshift. |
Open SQL workbench from the taskbar shortcut, which opens the new connection window. In that, click |
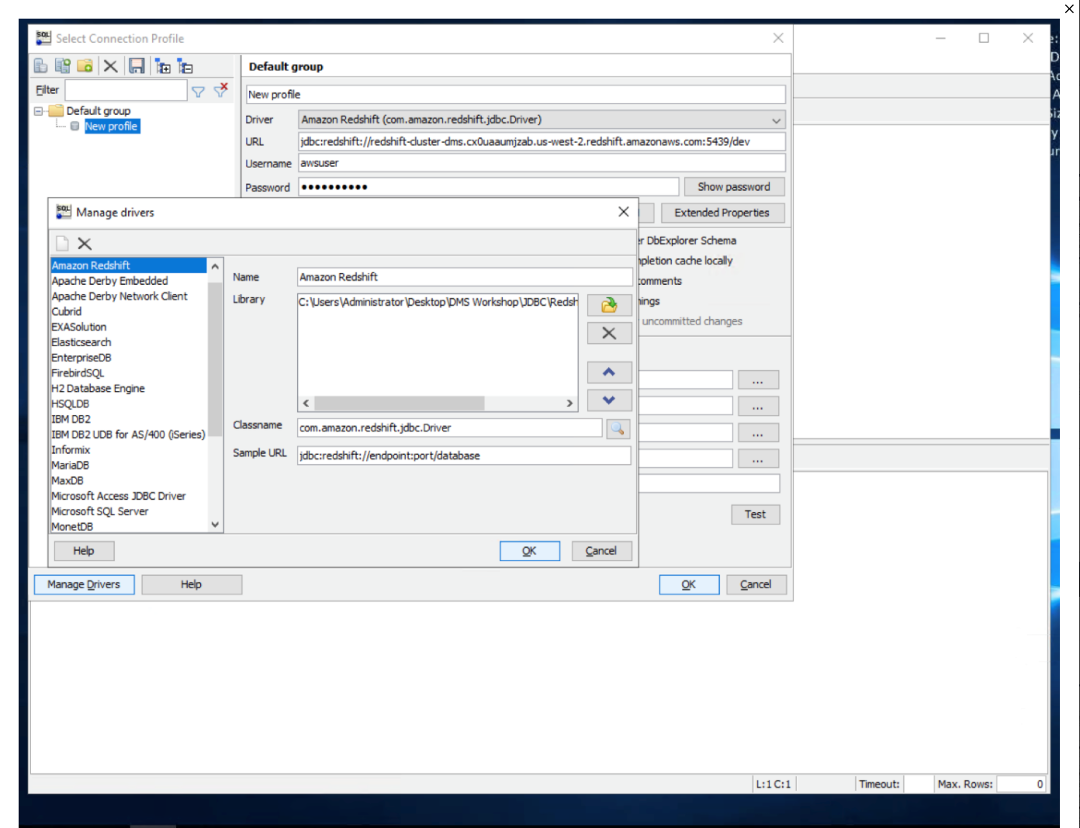
|
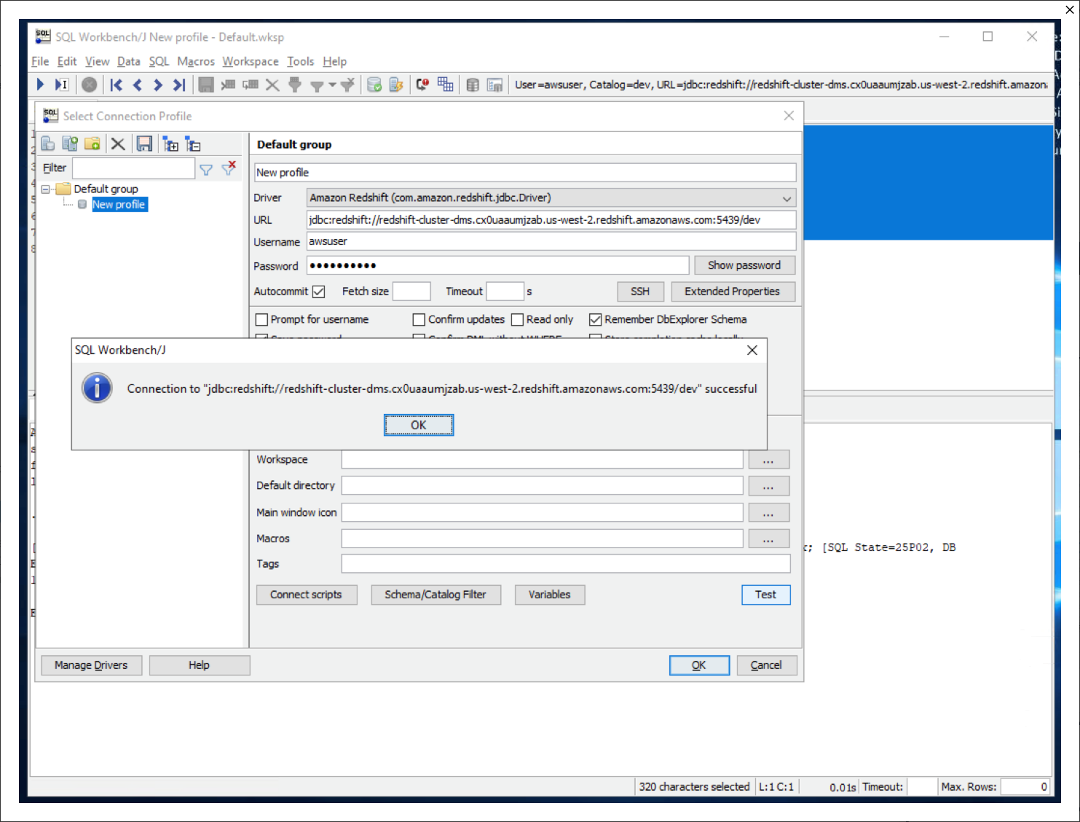
| Then provide the connectivity settings |
On the connectivity screen, select inputs: Click |
|
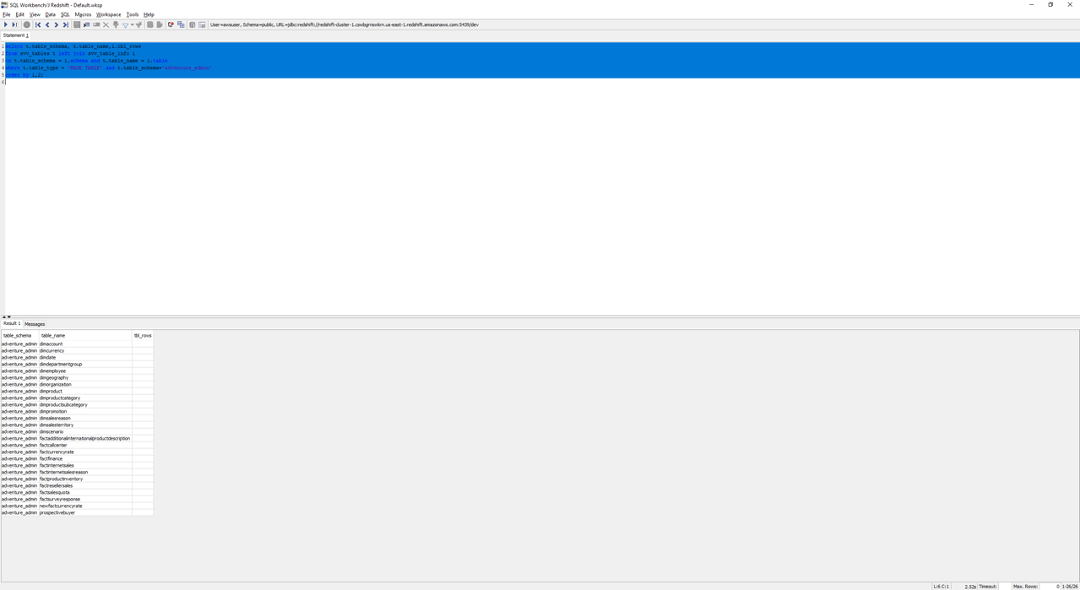
Marie can now check what does adventure_admin schema contain. All these tables have been successfully migrated to the redshift schema, but there are no records in it. AWS SCT schema conversion tool took care of the schema conversion. Next Marie will use SCT-Extractors for migrating data from Netezza DW to Redshift
|
|
|
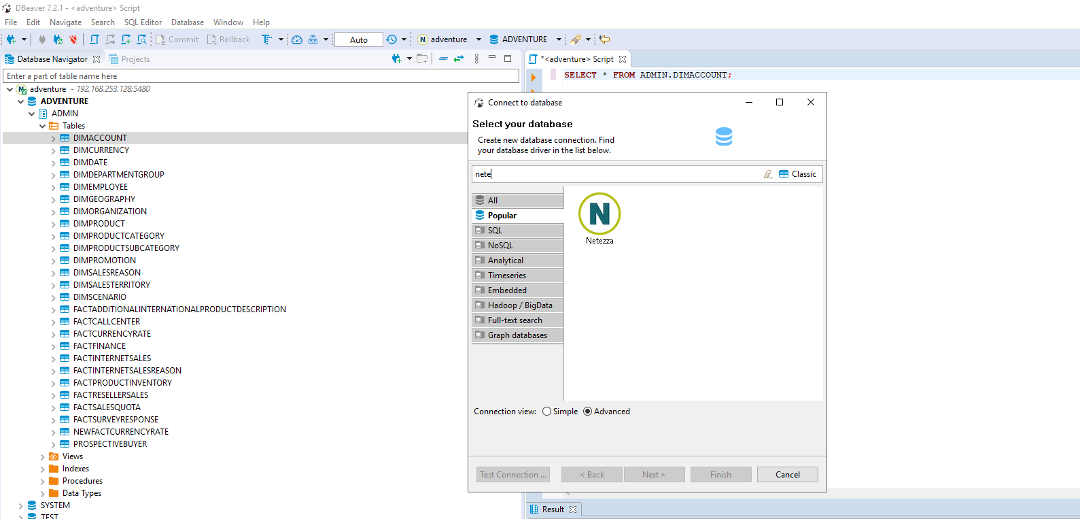
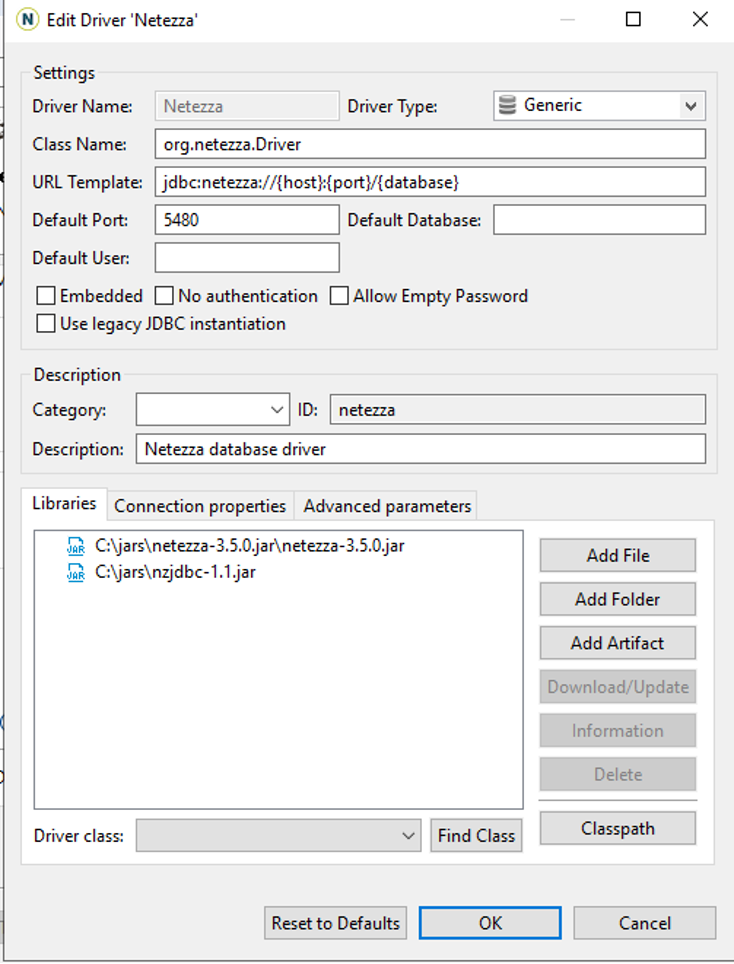
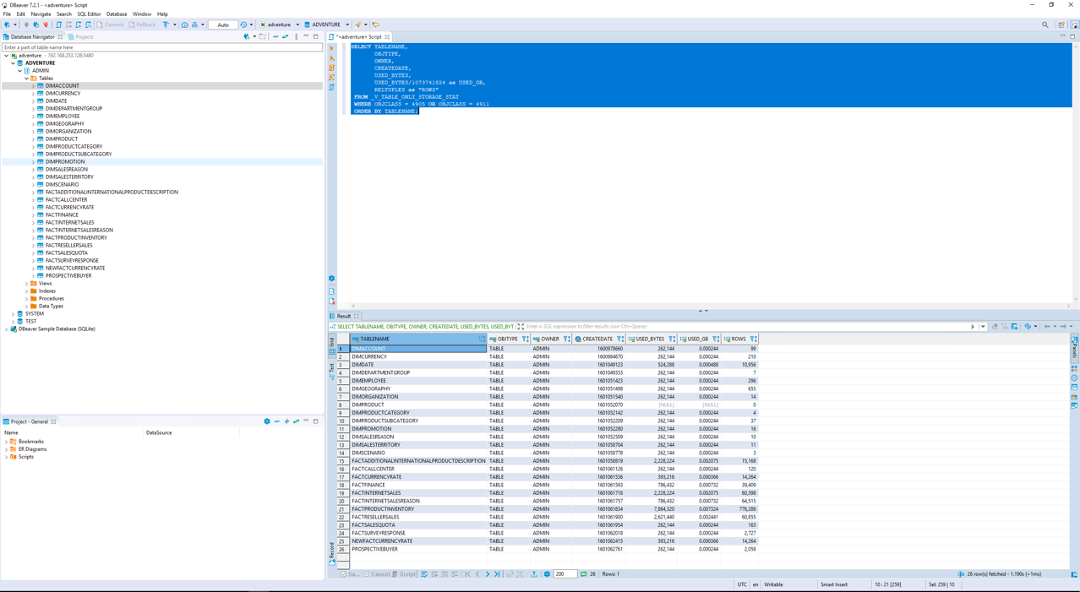
| Marie can now connect to Netezza (source) and run a query to check if all the tables have been converted to Redshift. She would use open source tool, DBeaver to connect with Netezza. |
|
|
Migrate the data
| Say | Do | Show |
|---|---|---|
|
Marie, will now configure the SCT-extractor to perform one time data move. When dealing with large volume of data multiple extractors can be used for migrating data. She will register the SCT-extractor to the SCT tool. |
Open this folder Click Save. Right-click New agent registration screen would pop-up. Fill in these details: Click One agent can be registered to one project at a time. To re-use same agent you will need to un-register from existing project and then register again. |
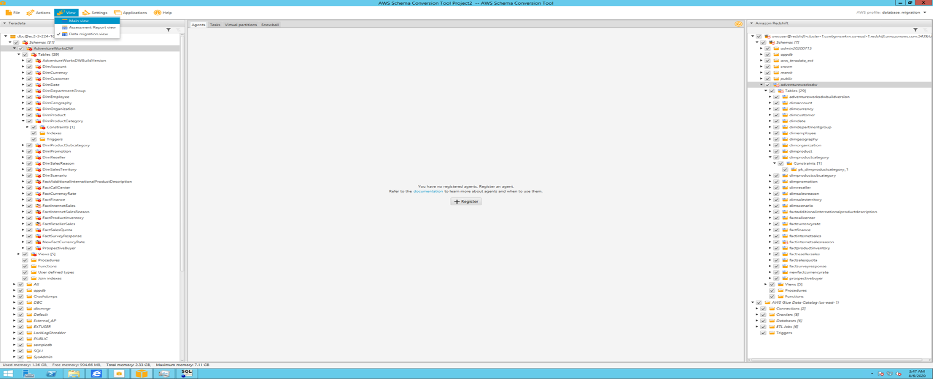
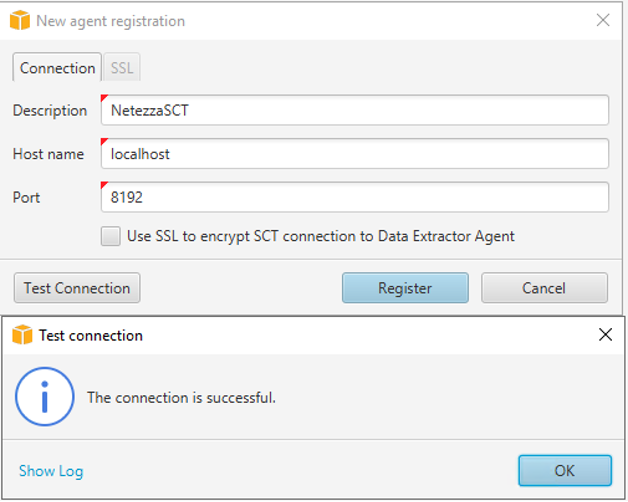
|
|
Marie will create a task for extractor to extract data, upload to S3 bucket and copy the data into tables created on Redshift. |
Right click tables under Click the AWS S3 settings tab and select the AWS S3 bucket previously noted above. S3 bucket folder: «TaskDataBucketName» Click |
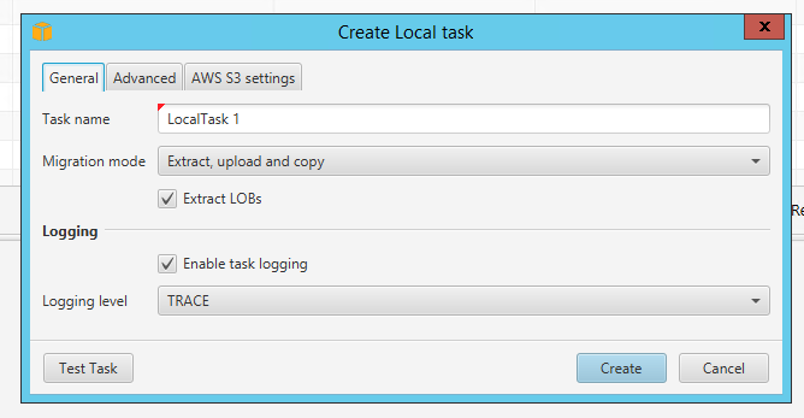
|
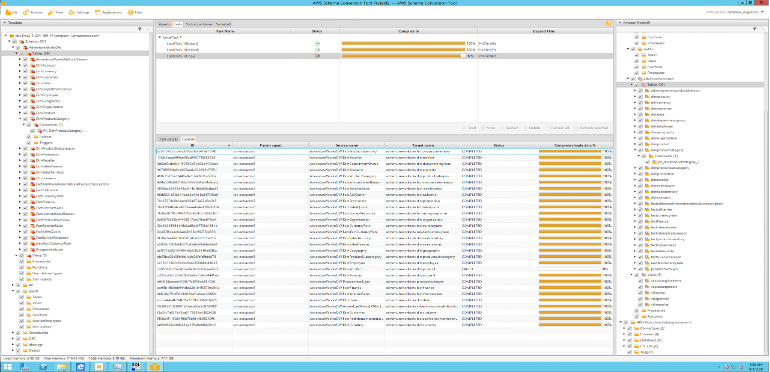
| Finally, Marie will execute the created task and monitor |
Click |
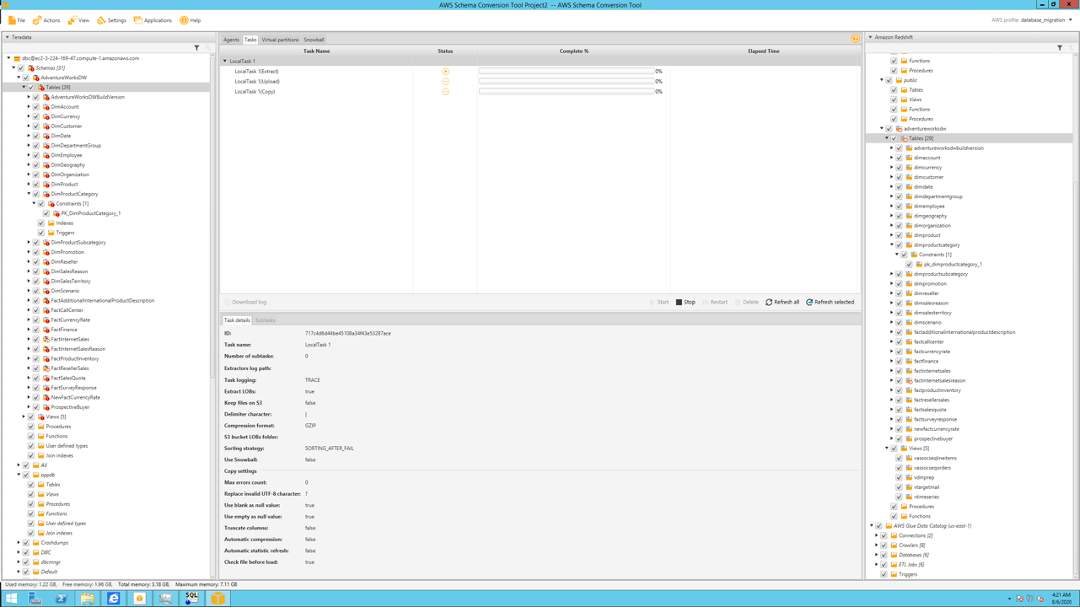
|
|
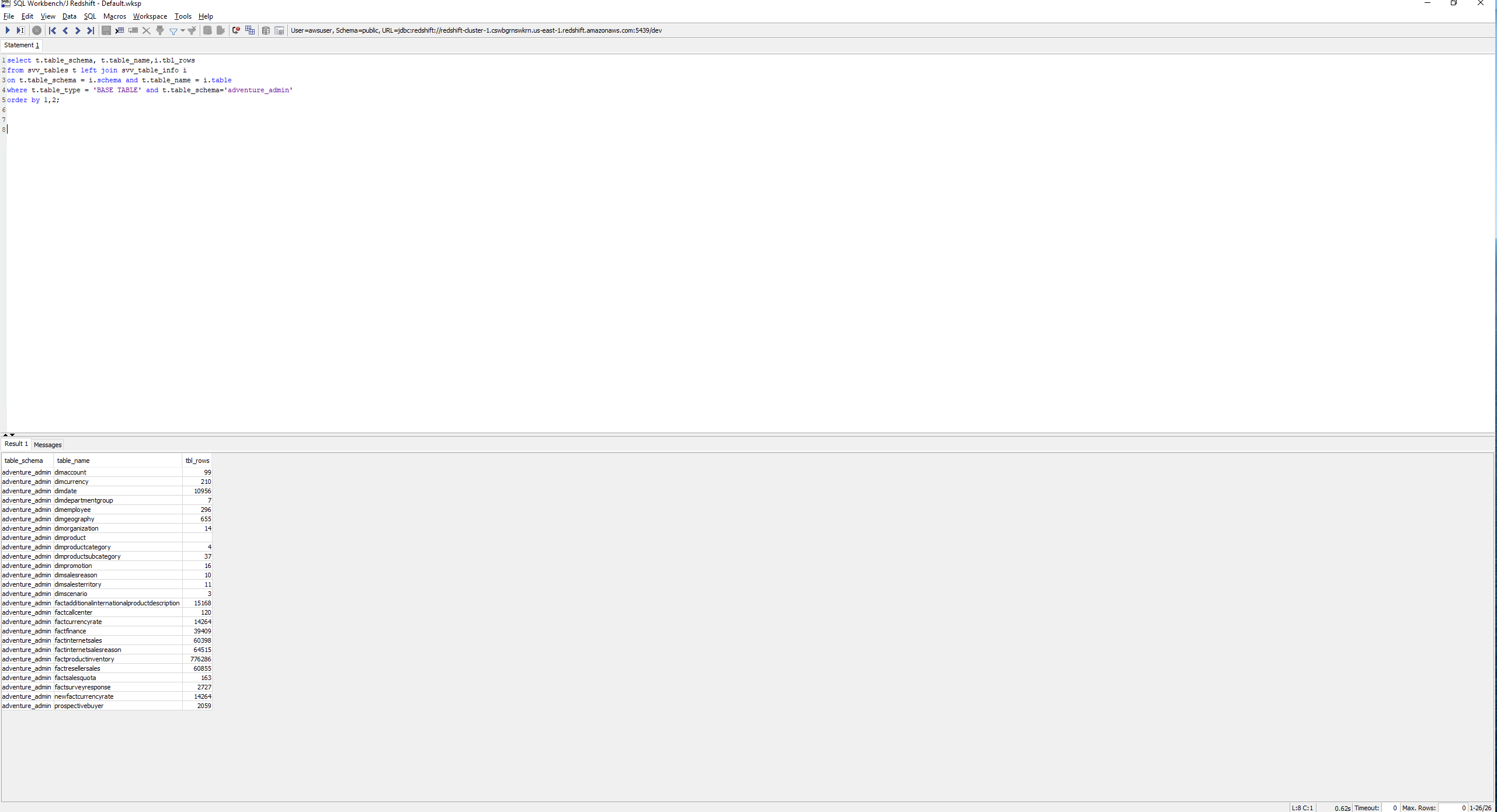
Mary can monitor status of tasks and % complete and tables which were loaded successfully. She will also need to verify the count of records loaded in the Redshift database. |
Click each Task to get a detailed breakdown of activity completed. Errors during Extract/Upload/Copy will need to be investigated. Connect to SQL workbench and execute the following query: |
|
Keep the data in sync
| Say | Do | Show |
|---|---|---|
|
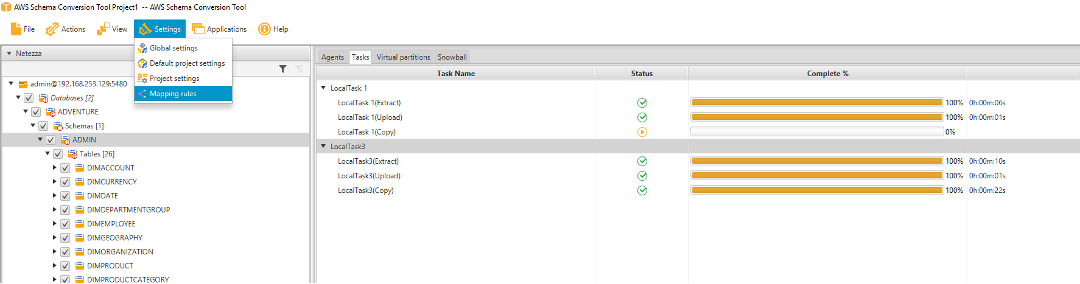
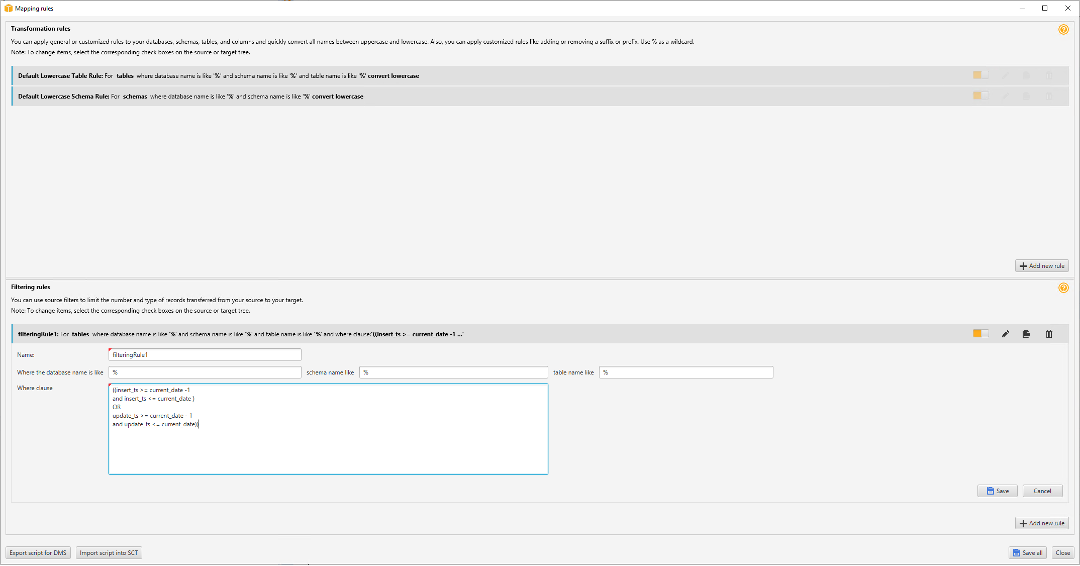
After a one time data move Marie will need to define CDC (change data capture) to migrate changed data from Netezza server to Redshift. |
|
|
Before you Leave
To reset your demo, drop the tables created by executing the following SQL statement in Redshift.
drop schema adventure_admin cascade;
If you are done using your cluster, please think about deleting the CFN stack or to avoid having to pay for unused resources do these tasks:
- pause your Redshift Cluster
- stop the Oracle database
- stop the DMS task