Streaming Data Ingestion
Demo Video

Before you Begin
Capture the following parameters from the launched CloudFormation template as you will use them in the demo.
https://console.aws.amazon.com/cloudformation/home?region=us-east-1#/stacks?filteringText=&filteringStatus=active&viewNested=true&hideStacks=false
- GlueExternalDatabaseName
- InfrastructureSimpleStackId
Client Tool
The screenshots for this demo will leverage the SQL Client Tool of SQLWorkbench/J. Be sure to complete the SQL Client Tool setup before proceeding. Alternatives to the SQLWorkbench/J include:
- SageMaker: streaming.ipynb
- Redshift Query Editor
Challenge
The data analyst Miguel needs to get latest product reviews in as soon as possible so he can build a dashboard to show the latest product trend and customer purchase habits. He asks Marie to build an ingestion pipeline to load the latest data into the Redshift data warehouse. The architecture of the new pipeline will look like the following:
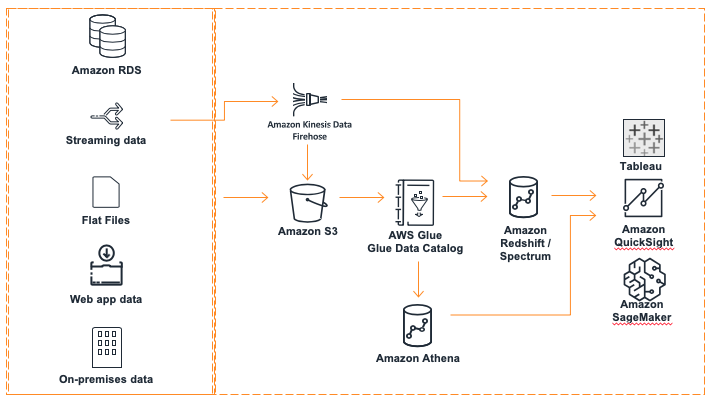
To solve this challenge Marie will do the following:
Create the data pipeline
| Say | Do | Show |
|---|---|---|
|
First, Marie must create a table in Redshift where the streaming data will land. |
Using your SQL editor, execute the following statement.
|
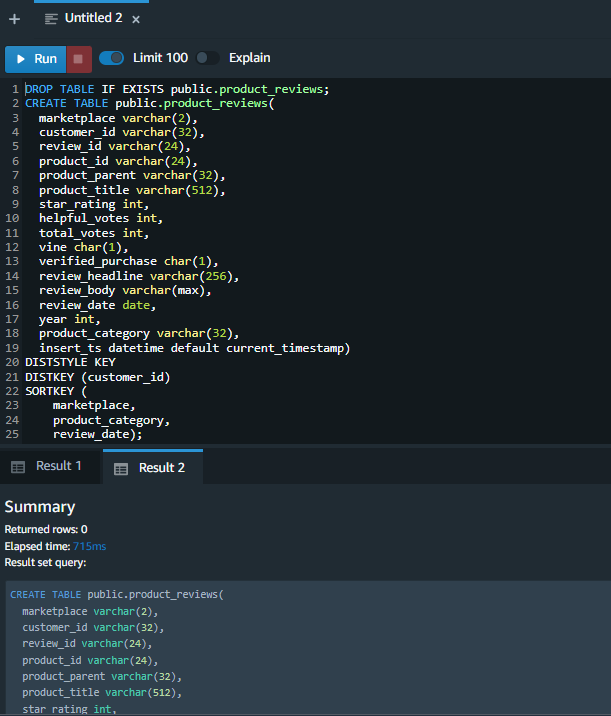
|
| Now, Marie must create a Firehose Delivery Stream to receive the incoming data and populate that data into the Redshift table she created. This Firehose Delivery Stream was automatically created using the Cloud Formation template. Let’s take a look at how it was configured. | Navigate to the product_reviews Firehose Delivery Stream. |
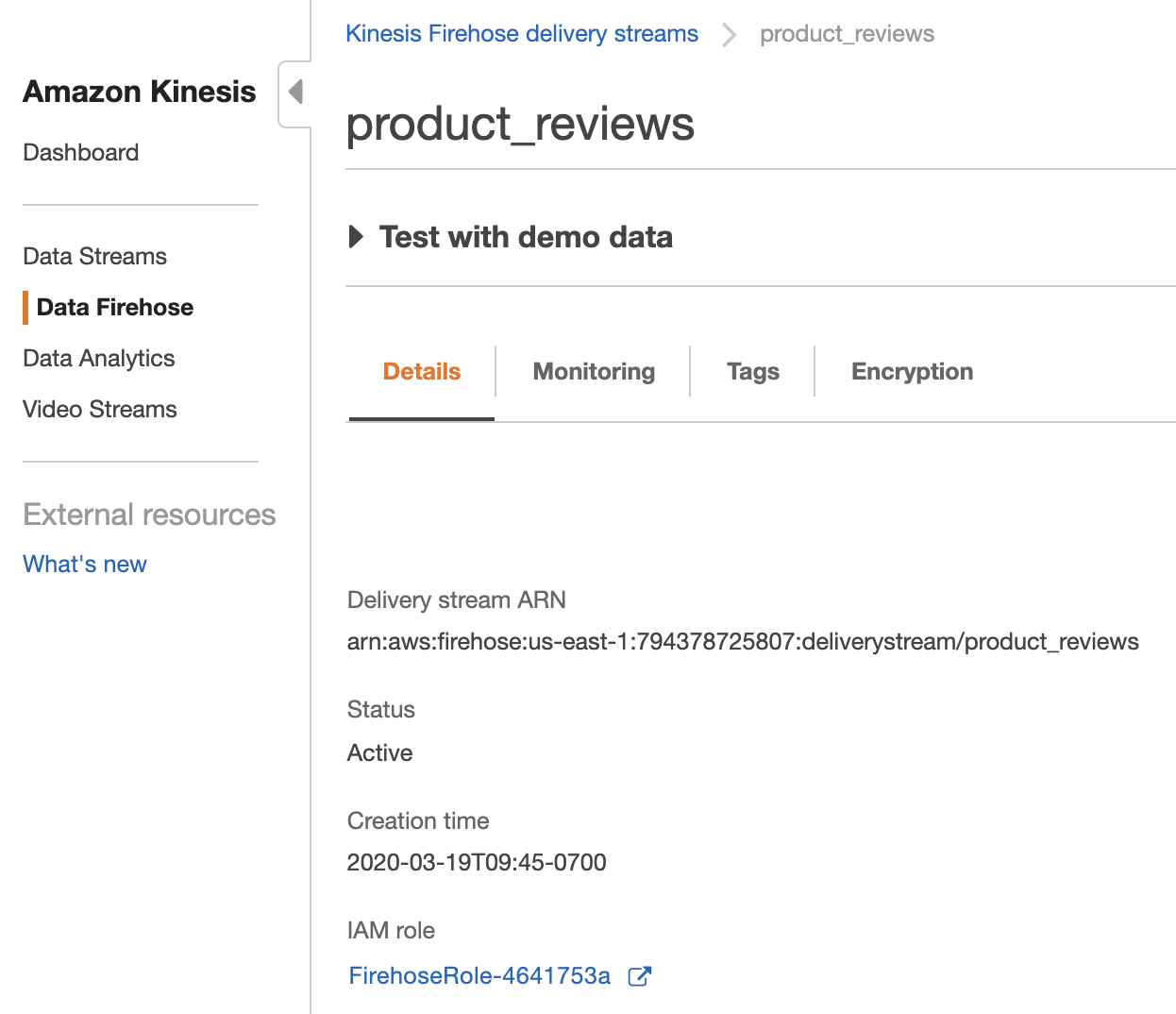
|
| Let’s also see how the Redshift Cluster was configured. | Scroll to the “Amazon Redshift destination” section. Note the JSON ‘auto’ clause which tells the copy operation how to parse the JSON file containing the product reviews. Also, note the Redshift connection configuration. |
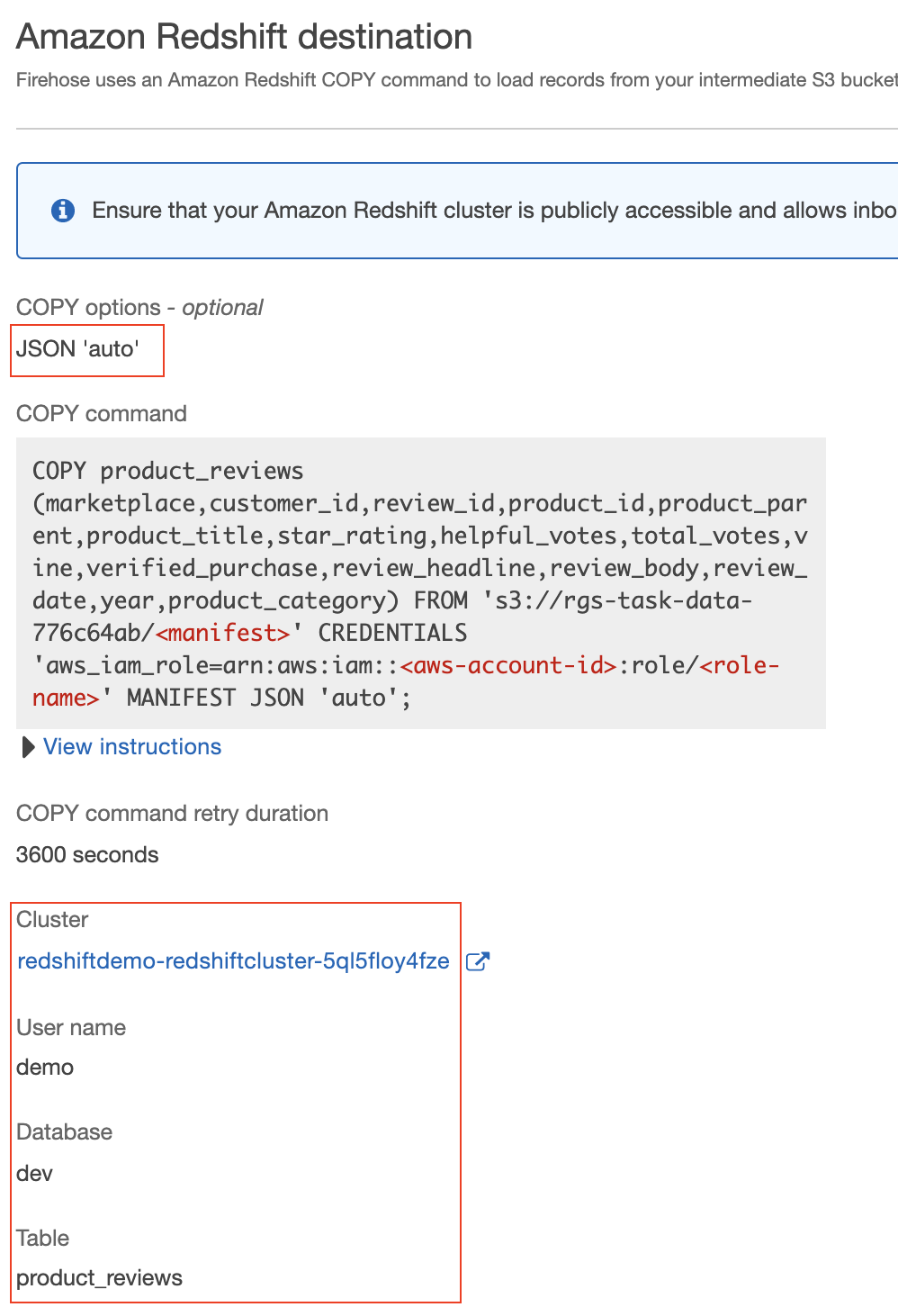
|
|
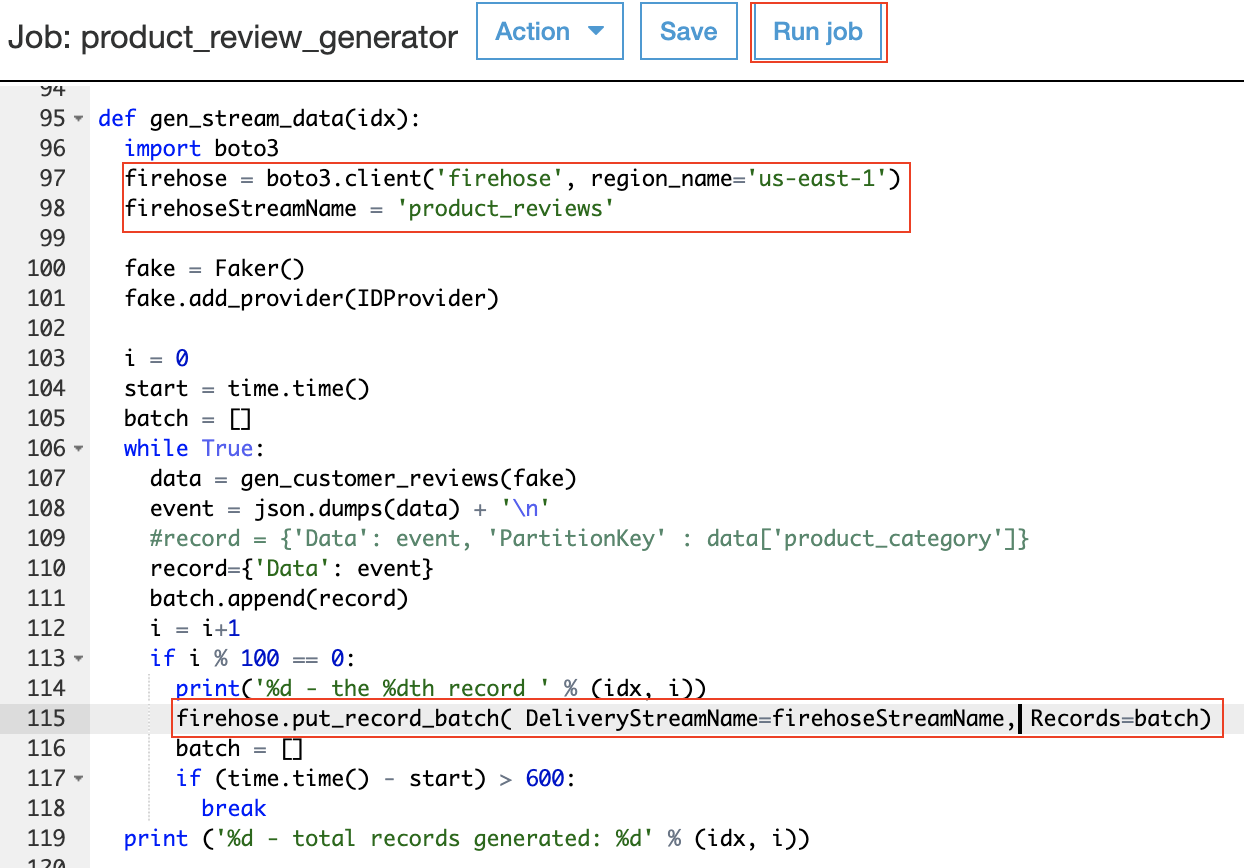
Next, Marie needs a mechanism to send the reviews to the Kinesis Delivery Stream. She identifies that she can use the put_record_batch function within the boto3 library she is already using in her python code. A Glue Python Shell job was automatically created using the Cloud Formation template. Let’s take a look at how it was configured.
Find the job named product_review_generator-<InfrastructureSimpleStackId> with the value previously determined. |
Navigate to the Glue Job and inspect the script. Scroll down to the gen_stream_data function (line 95). Note the lines to connect to the Firehose Delivery Stream and the line to put records into the stream. Click on the Run Job button to start generating data.
|
|
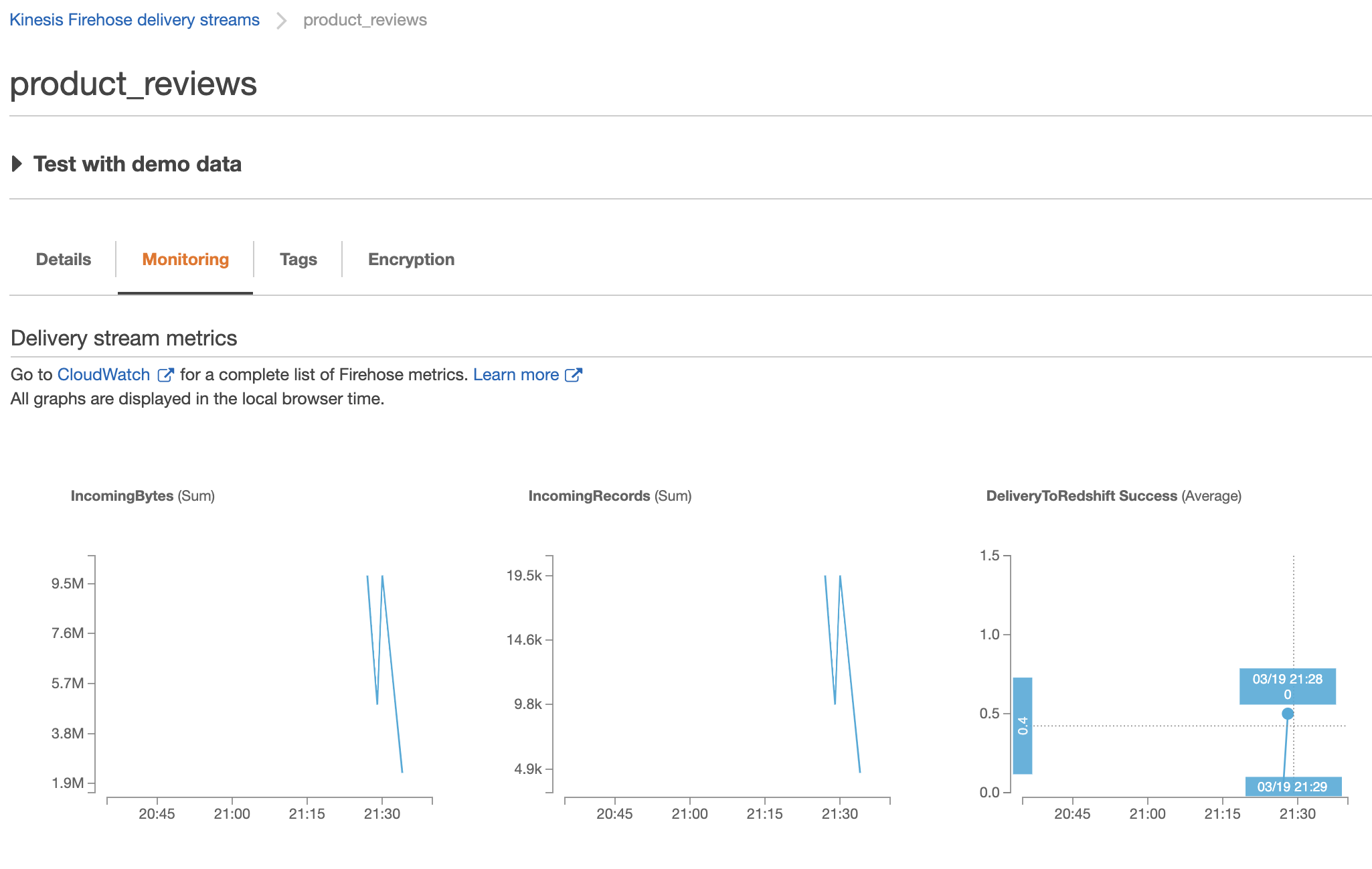
| Marie wants to make sure the data is being sent to Firehose. Let’s see if we can monitor the load. |
Navigate to Firehose to monitor the data being sent to S3 and Redshift. Please plan for 3+ minutes before data starts loading into Redshift.
|
|
Query the data
| Say | Do | Show |
|---|---|---|
|
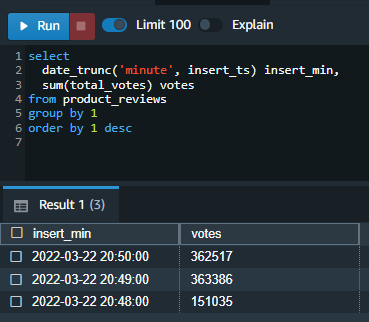
Marie wants to now validate the data is loading into Redshift every minute. |
Using your SQL editor, execute the following statement. Note that the data is continually loading including the most recent minute.
|
|
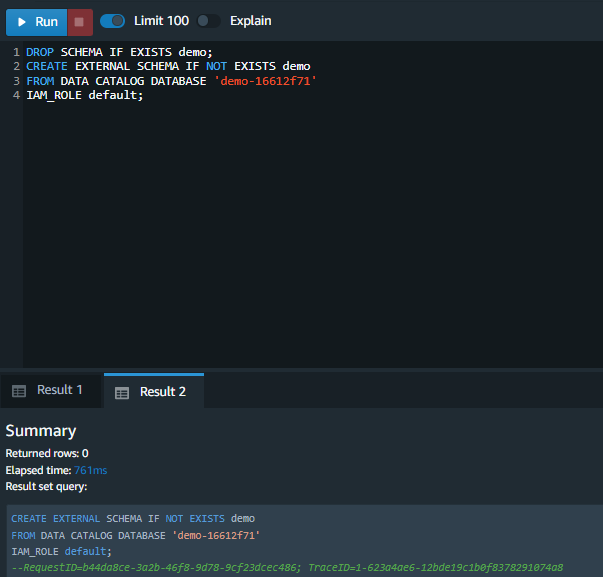
| Marie knows that the product review data will be very large and she already has older data in the Data Lake. She can catalog expose that data in Redshift by tying an external schema to her data lake database. |
Execute the following command, replacing the values for the <GlueExternalDatabaseName>
Amazon Redshift now supports attaching the default IAM role. If you have enabled the default IAM role in your cluster, you can use the default IAM role as follows. |
|
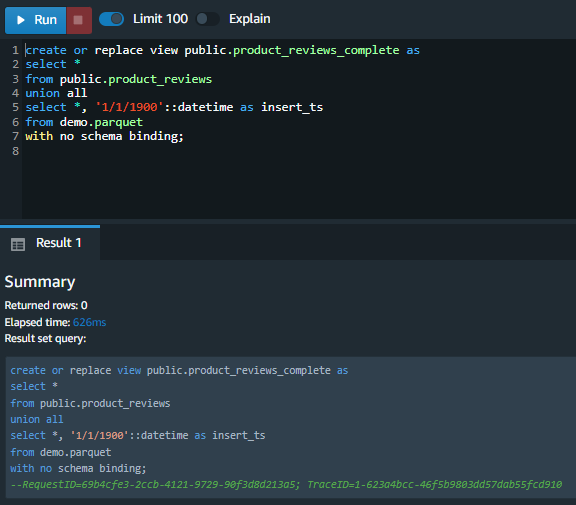
| Now that Marie has access to the data lake data, she wants to create a consistent view for Miguel to see both the hottest data which is loaded into Redshift and the older data which is in S3. She will need to create a union all view around the two data sets. |
Execute the following command, Note the use of no schema binding as the data in S3 will leverage a schema on read strategy.
|
|
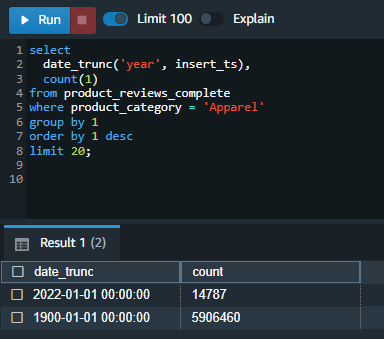
| Finally, Marie will test the consolidated view to ensure that both the hot and cold data is accessible. |
Execute the following query. Note the most recent data along with the older data from the data lake is available for querying.
|
|
Before you Leave
If you want to re-run the demo, make sure you run the following cleanup steps:
- Delete Redshift tables/views
drop table product_reviews;
drop view product_reviews_complete;
- Navigate to S3 and empty your <TaskDataBucketName> bucket.
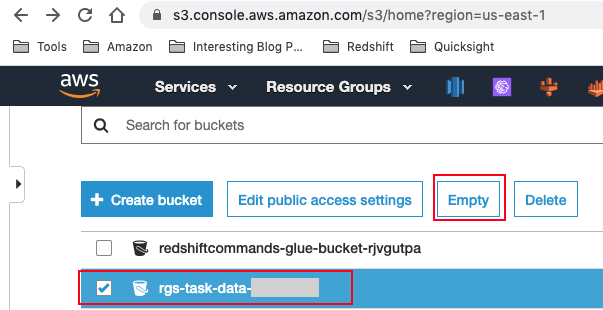
If you are done using your cluster, please think about deleting the CFN stack or Pausing your Redshift Cluster to avoid having to pay for unused resources.