Pivot Operations
Demo Video
Coming Soon!
Before you Begin
No parameters required in the demo.
Client Tool
For this demo we will use the Query Editor v2 to connect to the Redshift cluster. Be sure to complete the SQL Client Tool setup before proceeding.
Challenge
Marie is Red Import’s Data Engineer. Marie gets machine data from her source systems as normalized key value pairs. Miguel, the Data Analyst has asked her to present the data in columnar format as some of the Business Intelligence reports need that structure. Miguel needs data for machine models 100, 101 and 102 only. In order to achieve this task, she needs to limit the machine data, pivot the long key value data set into flat format as requested by Miguel. Below is an example of what Marie is trying to achieve:

To solve this challenge, Marie will use the new Amazon Redshift PIVOT clause that will dynamically pivot the rows into columns. She will limit the pivot to only the machine 100, 101 and 102 that are required by Miguel. She follows the below steps to access the source data using Redshift Spectrum and apply pivot clause in the select statement.
Create external table
| Say | Do | Show |
|---|---|---|
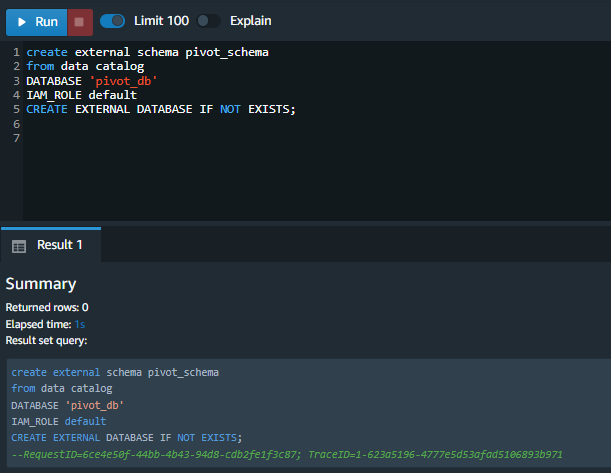
| After understanding the dataset that needs to be pivoted, Marie creates an external schema to place the external table. |
Execute the following SQL in the Redshift cluster using the Query Editor v2.
Amazon Redshift now supports attaching the default IAM role. If you have enabled the default IAM role in your cluster, you can use the default IAM role as follows. |
|
|
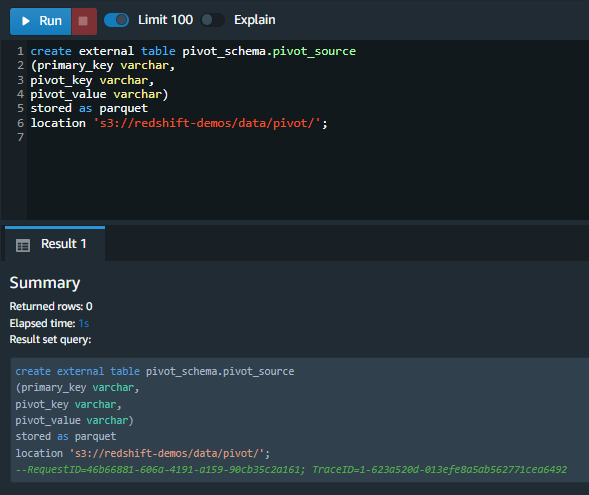
Then Marie creates an external table for the S3 data using an SQL script. |
Execute the following SQL in the Redshift cluster using the Query Editor v2.
|
|
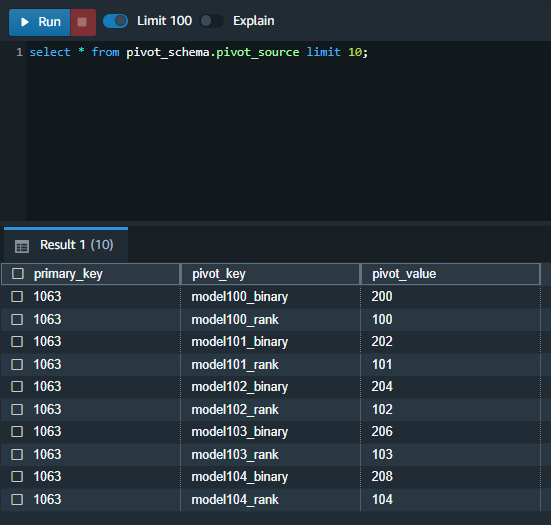
| Marie then queries the external table using Redshift Spectrum via the role she has created for her cluster. |
Execute the following SQL in the Redshift cluster using the Query Editor v2.
|
|
View pivoted data
| Say | Do | Show |
|---|---|---|
|
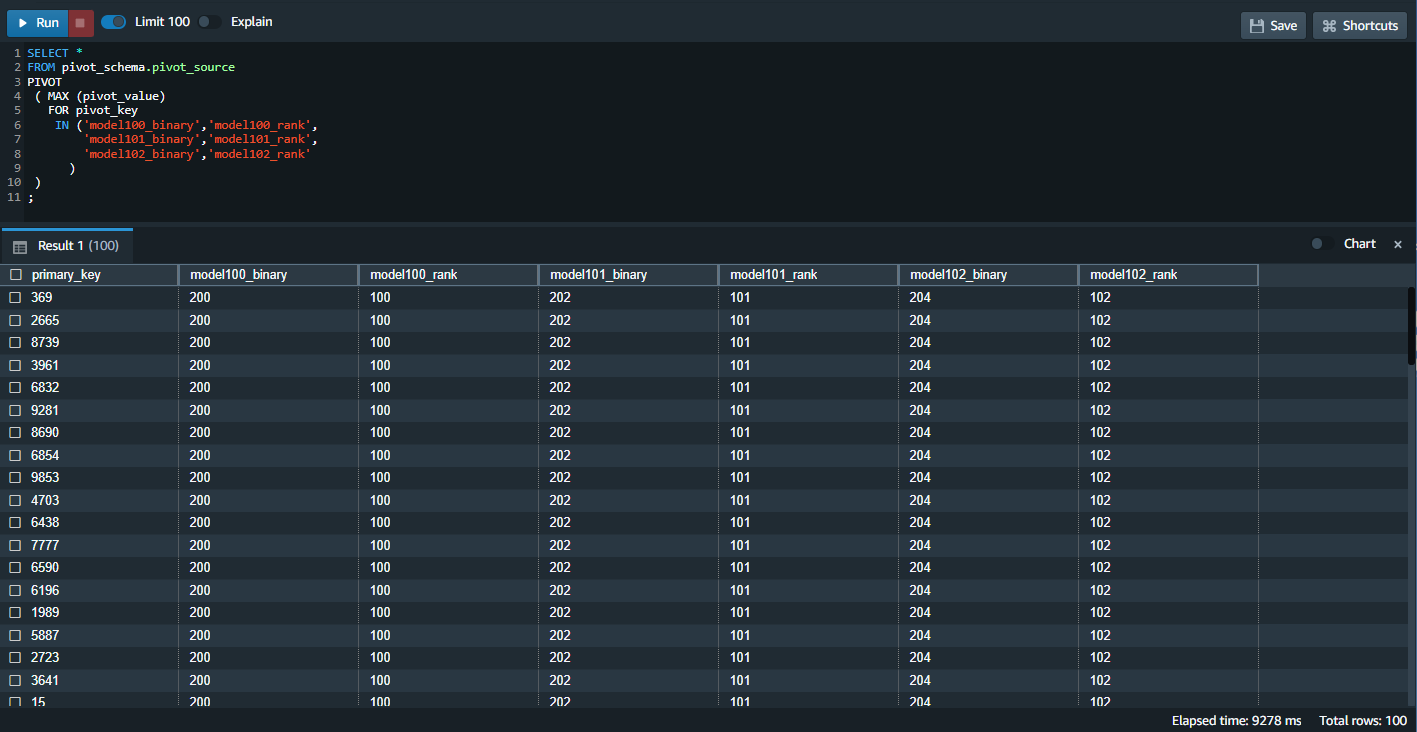
Marie uses the new PIVOT clause in Amazon Redshift to execute a pivot of the data from the pivot_source table. She uses the FOR clause and the IN list to restrict the pivotting for only machine models 100, 101 and 102 required for the report. |
Execute the following SQL command
|
|
Before you Leave
If you want to re-run the demo, make sure you cleanup the Redshift objects, using the following SQL:
DROP SCHEMA pivot_schema CASCADE;
If you are done using your cluster, please think about deleting the CFN stack or to avoid having to pay for unused resources do these tasks:
- pause your Redshift Cluster
- stop the Oracle database
- stop the DMS task