ETL Orchestration with Data API
Demo Video

Before you Begin
Please ensure that you have executed all the steps in the setup.ipynb SageMaker notebook as described in the preparing your demo section.
Challenge
Miguel, the Data Analyst has built store sales performance reports for the business users from the Data Lake and initially reached out to Marie, the Data Engineer, to see if there is a way to make the reports perform faster and reduce cost. Marie decided to build a new data pipeline so that these reports can be loaded into the Redshift Data Warehouse. Each job in the data pipeline is manually executed by Marie before start of business (9:00 AM) and later on Marie realizes that the existing process is time consuming and error prone as there are times when the jobs in the data pipeline are being executed out of order (or not at all), especially when there are job failures when a job runs for more than 15 minutes. The issue in the Store Sales data pipeline are due to manual tasks have also eroded some of the trust from the business users in delivering the critical store sales performance reports in a timely manner.
To address these issues, Marie will redesign the Store Sales data pipeline to automatically manage the execution of the jobs in the data pipeline that ensures jobs are executed in the proper order and only when the necessary dependencies have been met. To solve this challenge Marie will do the following:
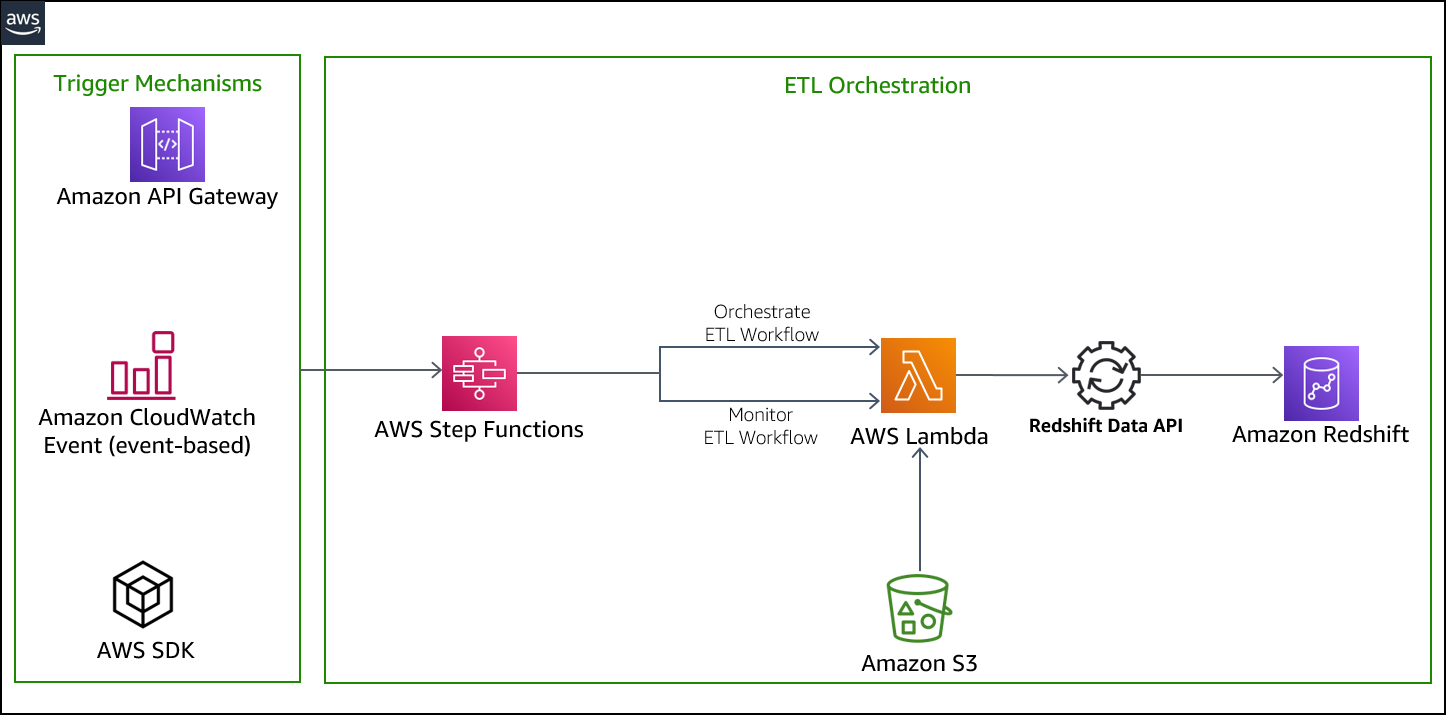
Here is the architecture of her updated data pipeline:
Write ETL script
| Say | Do | Show |
|---|---|---|
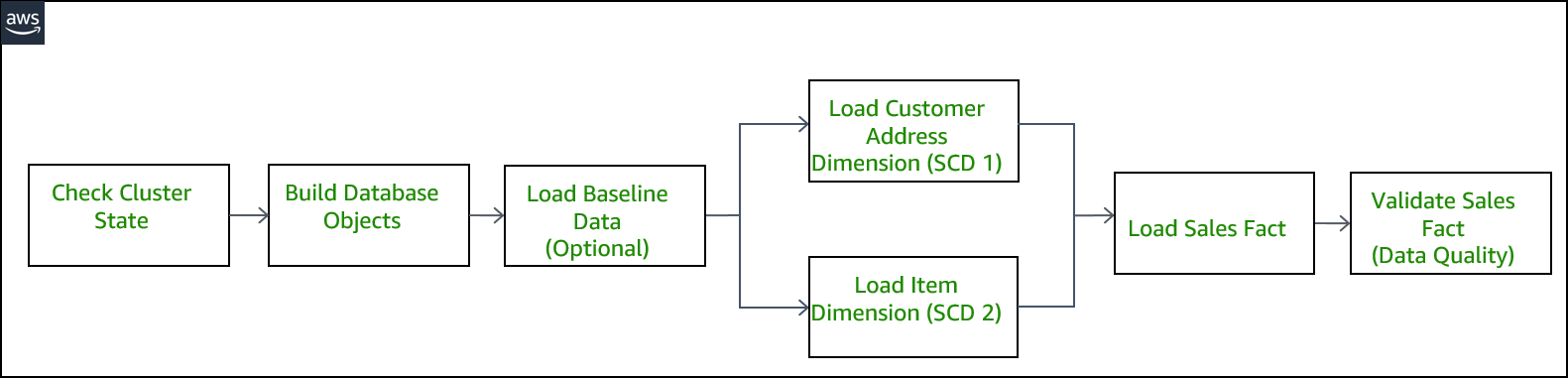
| Marie is looking for optimizations and reviews the job sequence of what she runs manually every morning. She identifies that two load jobs, Customer Address and Item dimension tables, can be executed in parallel. However, both need to finish successfully before the next load job for the Store Sales fact table can be executed. | Review the ETL workflow. |
|
|
Marie needs to create an orchestration layer that can execute the jobs, maintain the order, sequencing and remove the manual need to run these jobs daily. She will utilize AWS Step Functions to orchestrate. |
The Cloud Formation template has already created a Lambda Function containing ETL code in Python that has all the functions she will need to connect and run SQL commands on Redshift. This code utilizes Data API based methods to accomplish these tasks.
|

|
|
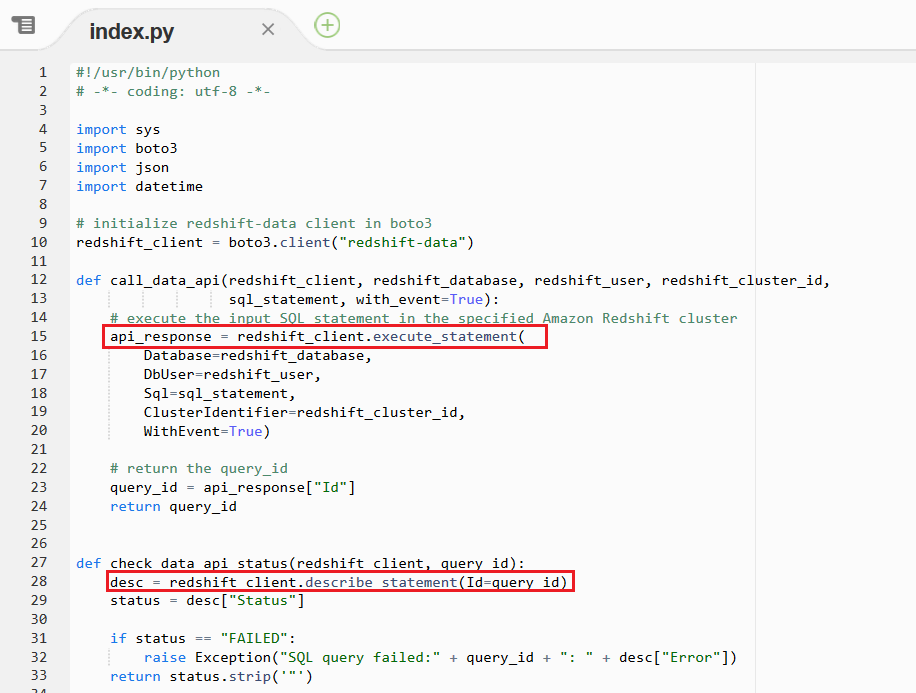
Marie inspects the ETL code to ensure it is ready for use in the new orchestration layer data pipeline. Redshift Data API provides asynchronous execution capability so that the host is not held captive while the ETL is executing. So she must have an execution method and polling method to determine when the job has finished. |
Scroll down to the Scroll down to the The ‘redshift-data’ client in the boto3 library (line 10) is initialized to use Redshift Data API |
|
Create ETL Orchestration
| Say | Do | Show |
|---|---|---|
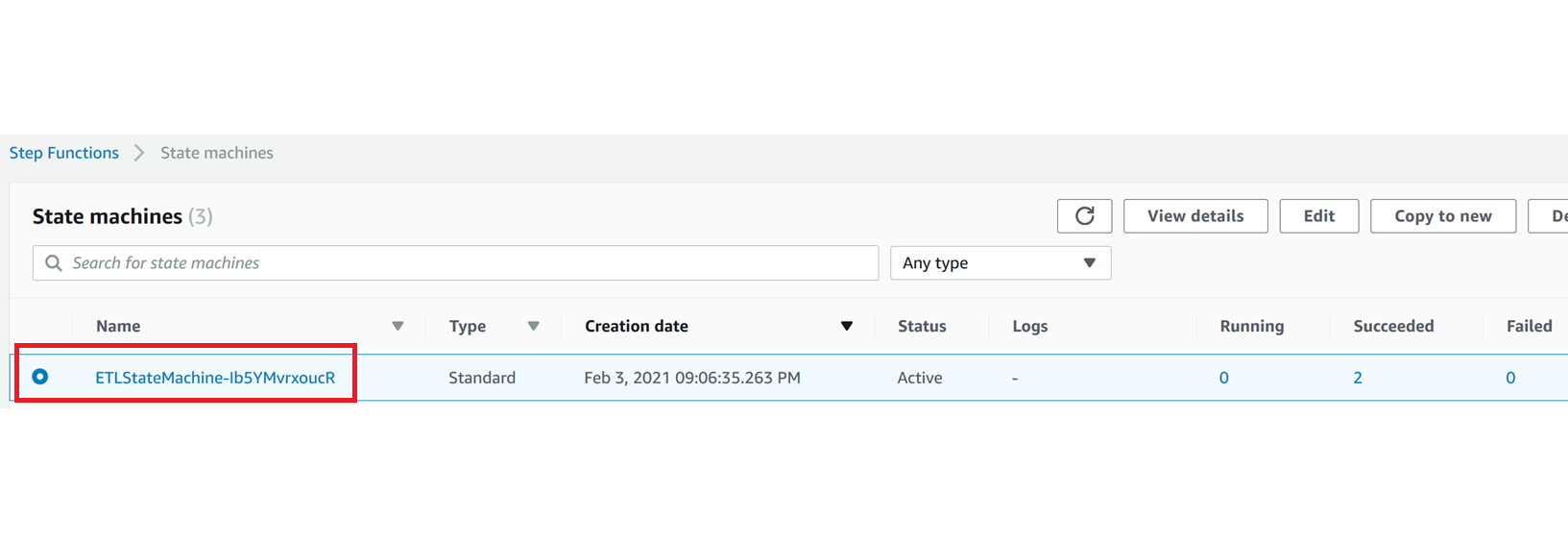
| Marie must create a state machine using AWS Step Functions in order to perform the ETL orchestration. AWS Step Functions provide easy access to AWS services, such as Lambda, to perform tasks (ie Execute an ETL job). With two simple methods noted before she can build complete automated workflows. |
A state machine was automatically created using the Cloud Formation template.
|
|
|
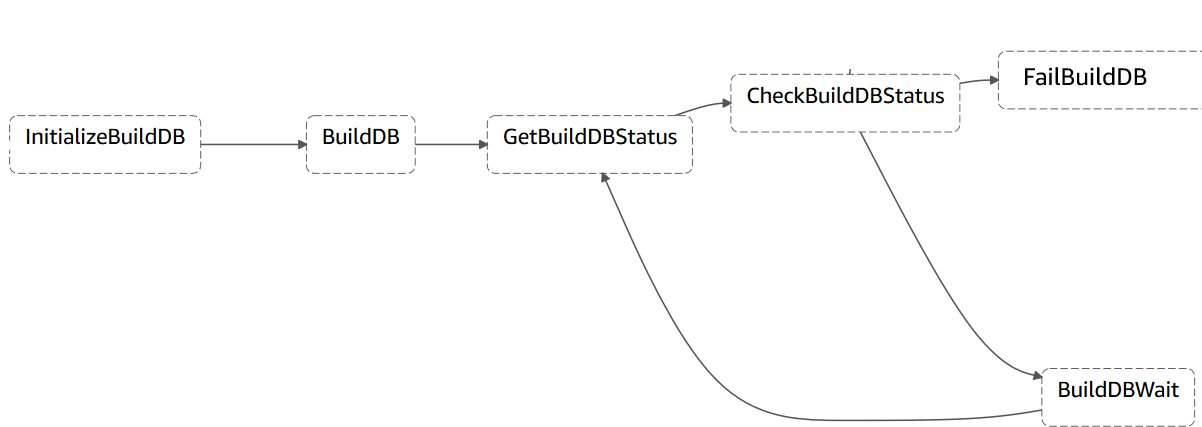
Marie needs a mechanism to execute the ETL jobs in the correct order and only when the appropriate conditions are met. She identifies a workflow definition using multiple states that allows automated polling of an ETL job status and execute corresponding downstream ETL jobs accordingly.
Here is a high level view of the workflow definition.
|
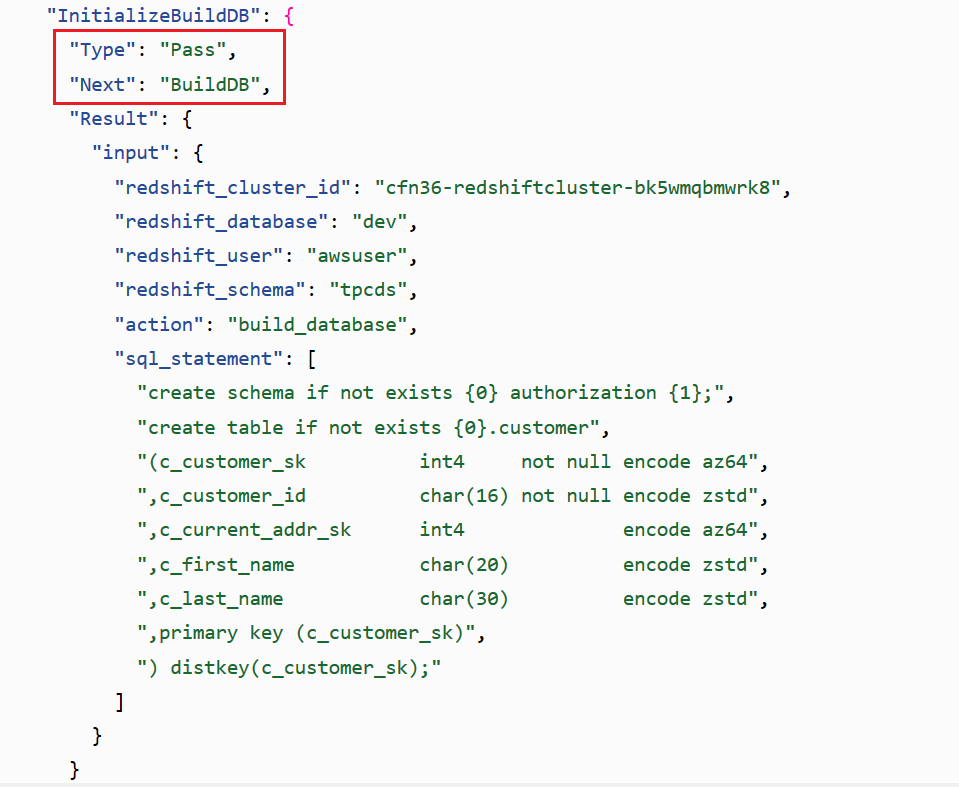
Review the following state machine and related code. The SQL statements defined in the InitializeBuildDB state are transitioned into the next state called BuildDB and in this state is where the SQL statements is passed as JSON input into the RedshiftDataApi Lambda function.
As you can see from the InitializeBuildDB state, you can execute multiple SQL statements when using Redshift Data API. |
|
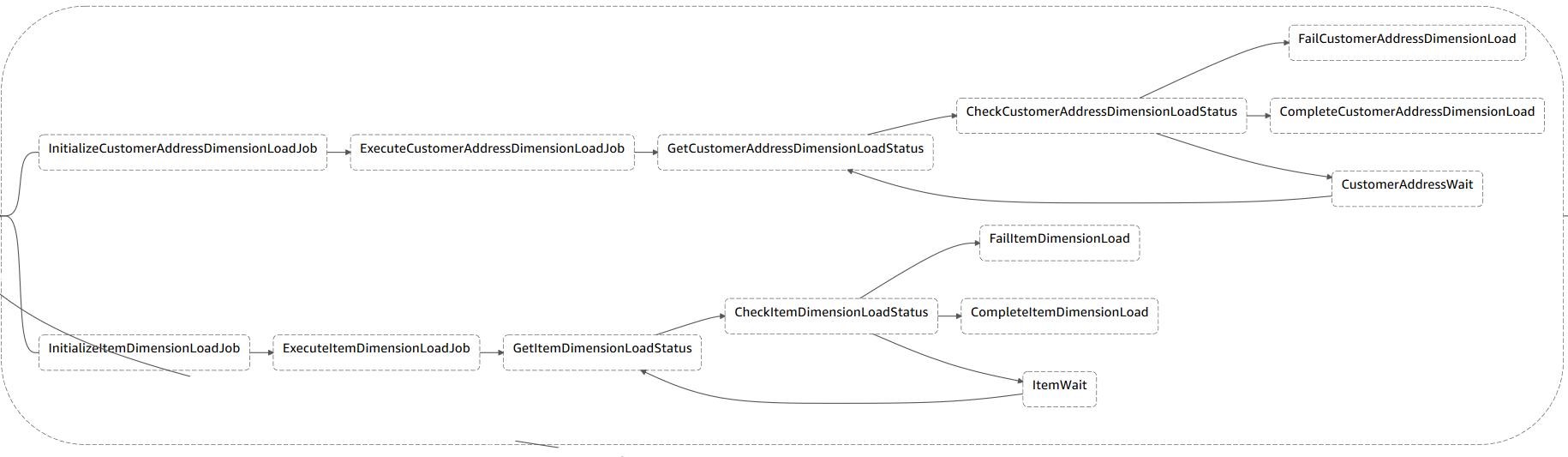
Marie identifies that she can use the parallel state in order to create parallel branches of execution for the two load jobs of Customer Address and Item dimension tables.
|
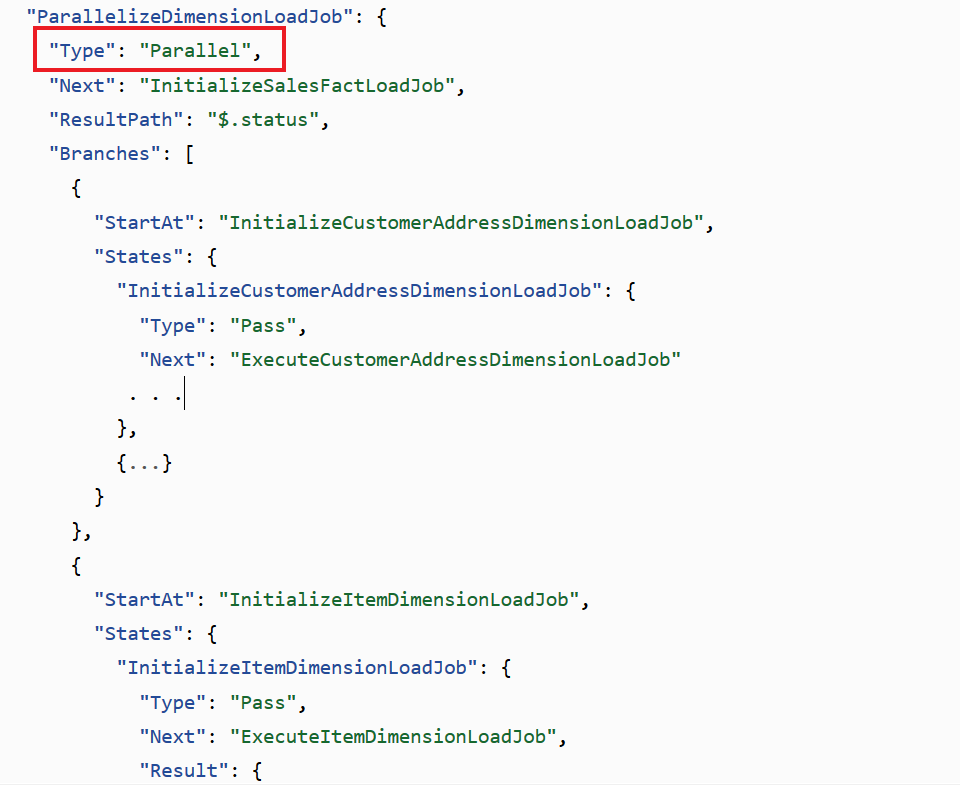
Review the following ParrallelizeDimensionLoadJob state machine’s code
Each branch must be self-contained. A state in one branch of a Parallel state must not have a Next field that targets a field outside of that branch, nor can any other state outside the branch transition into that branch. |
|
Execute the data pipeline
| Say | Do | Show |
|---|---|---|
Marie wants to validate the workflow of the revised Store Sales data pipeline and is now ready to execute the state machine.
|
|
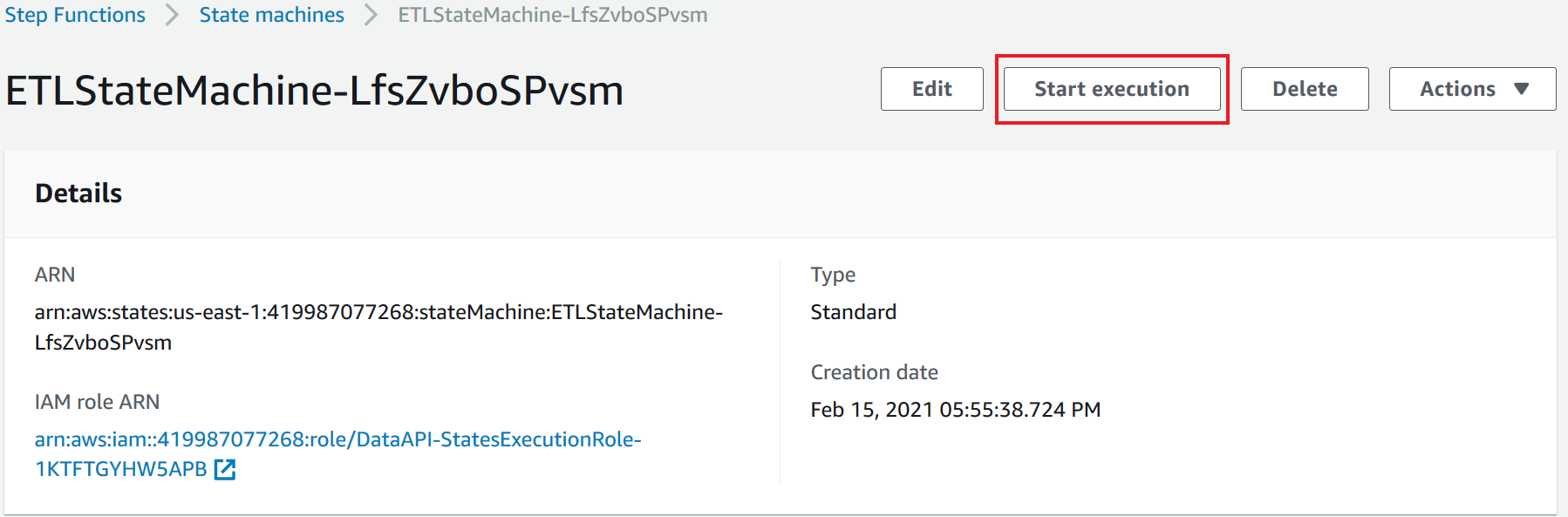
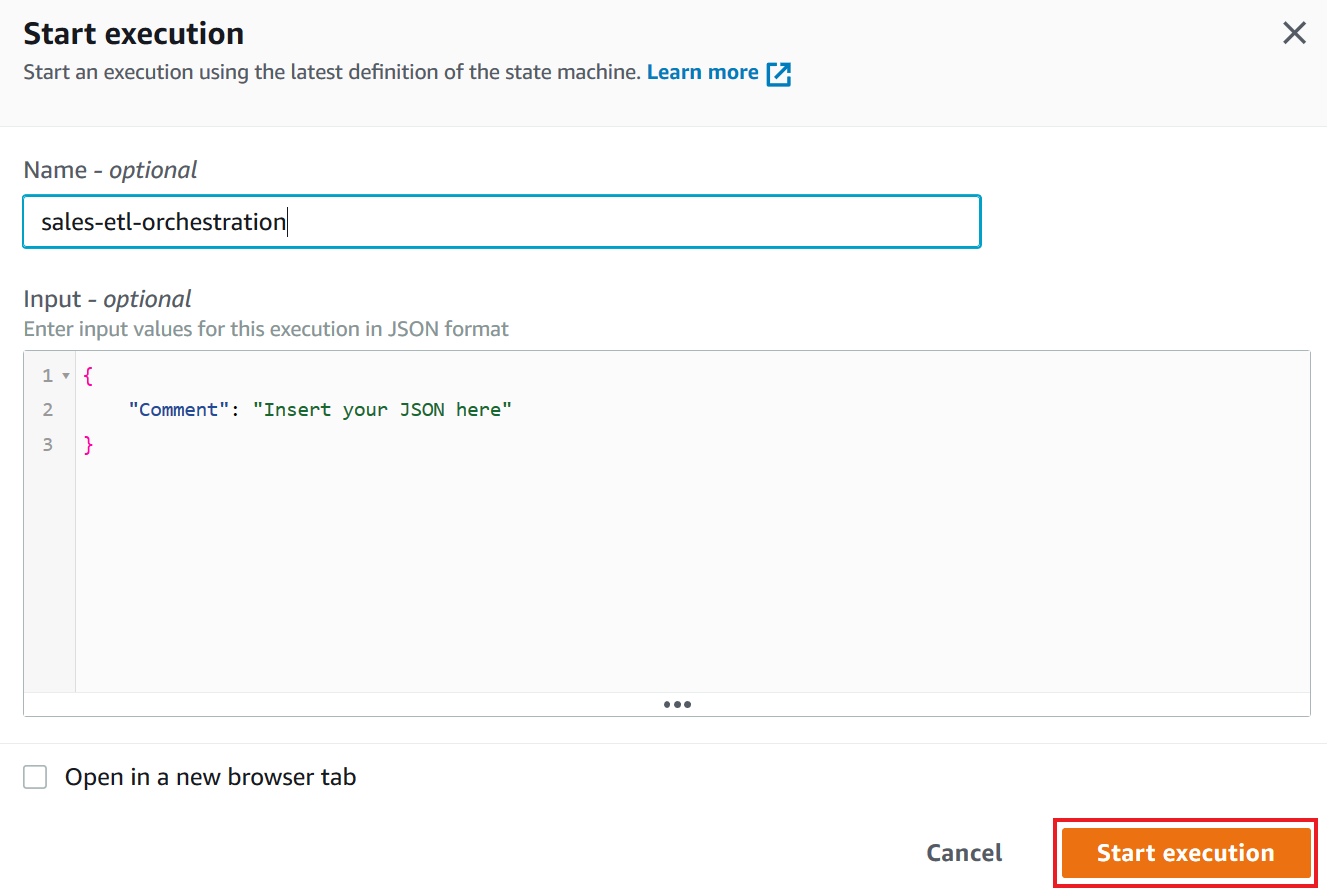
|
| Marie wants to monitor the execution of the ETL workflow to verify it is being executed using the correct database user. Let’s see if we can check the information passed to the Redshift Data API. |
The Store Sales data pipeline should finish in under 3 minutes. Prepare for a break here or come back to this step later. |
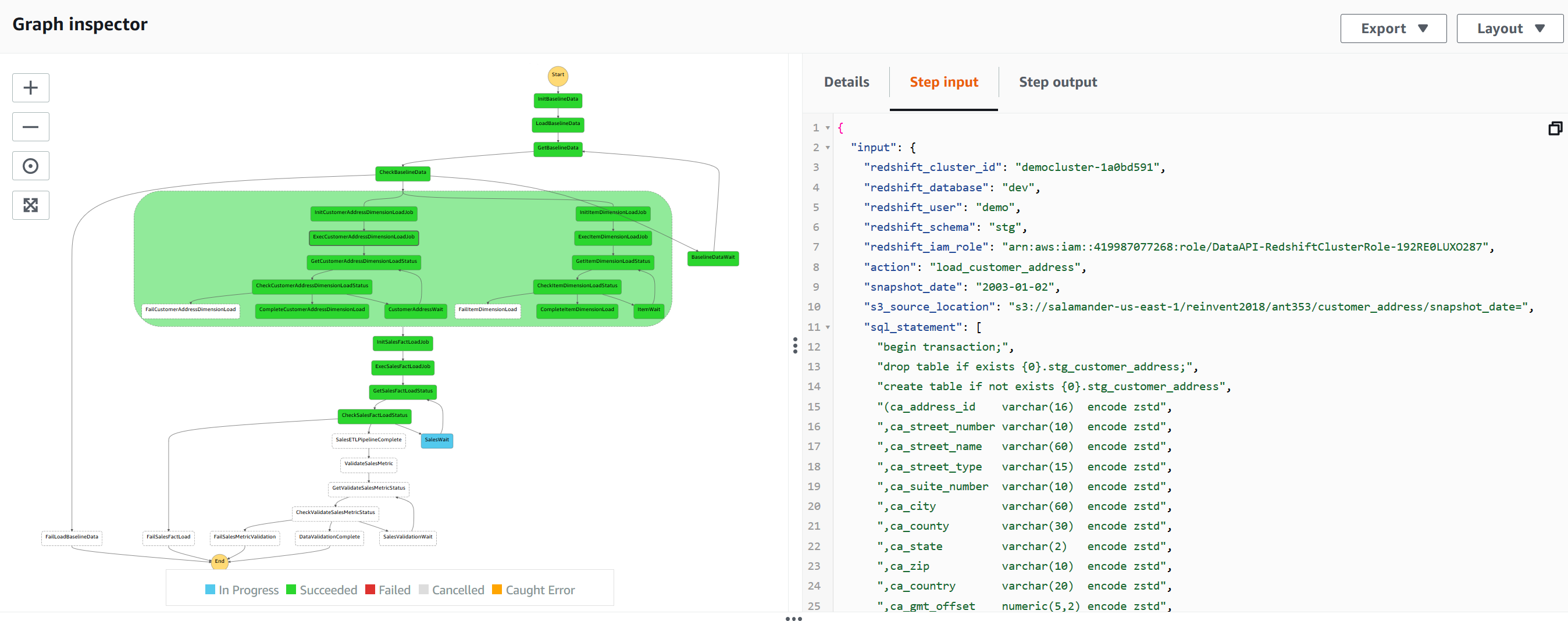
|
| Now that the ETL workflow has completed successfully, Marie wants to validate the execution time on each state to check if there is room for improvement in the data pipeline or just review it. |
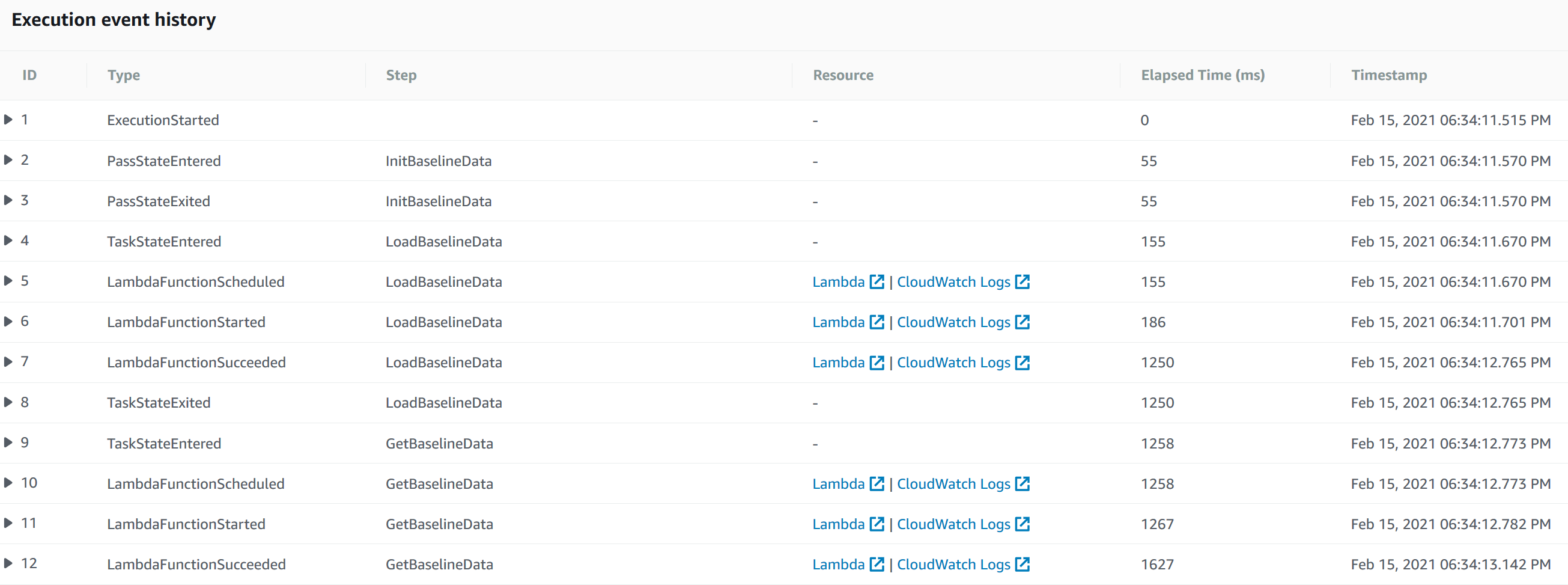
Once the Execution Status turns to Succeeded, scroll down to view the Execution event history and see the details of each state.
|
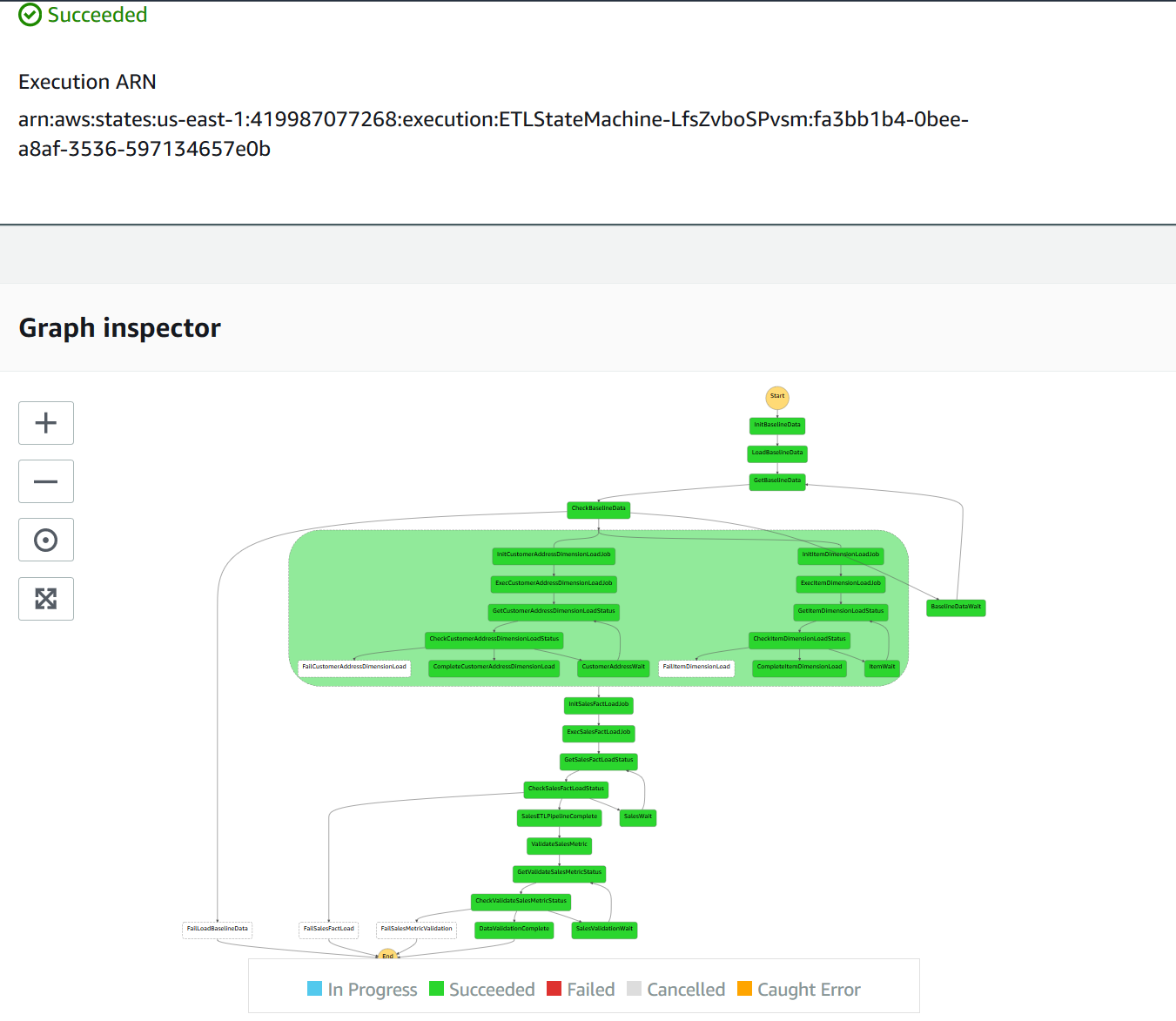
|
Test the data
| Say | Do | Show |
|---|---|---|
|
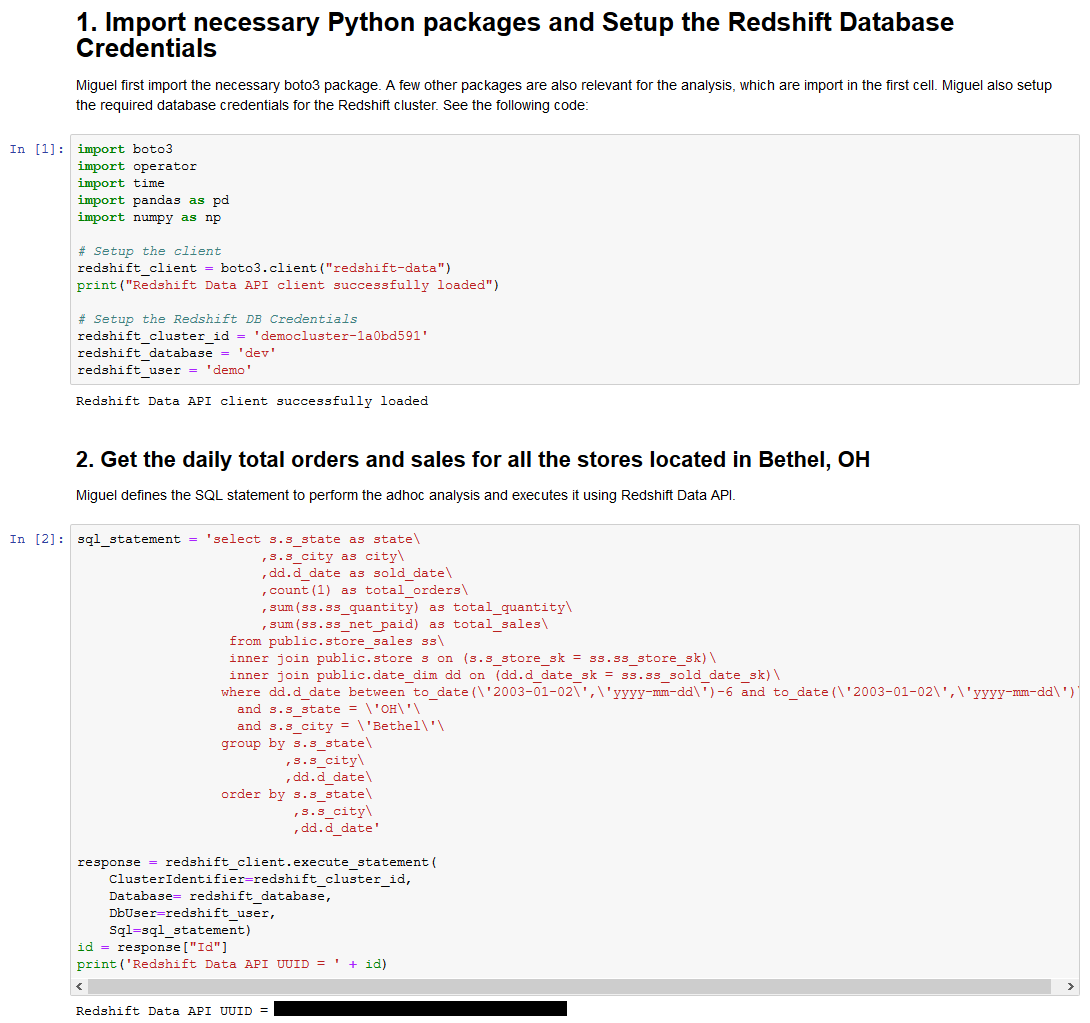
After receiving confirmation from Maria on the completion of the Store Sales data pipeline. Miguel wants to perform a sanity check and proceeds to run ad hoc analysis to view the store sales performance report for all the stores located in Bethel, OH. Miguel has login and password credentials and wants to be able to repeat his ad hoc test regular so he chooses to use Python Notebooks in SageMaker along with Redshift Data API to run this test.
This is a common scenario where customers want to execute queries against a Redshift cluster programmatically without doing Data Sharing or developing Rest APIs. |
This will execute SQL to obtain the daily total orders and sales for all stores located in Bethel, OH |
|
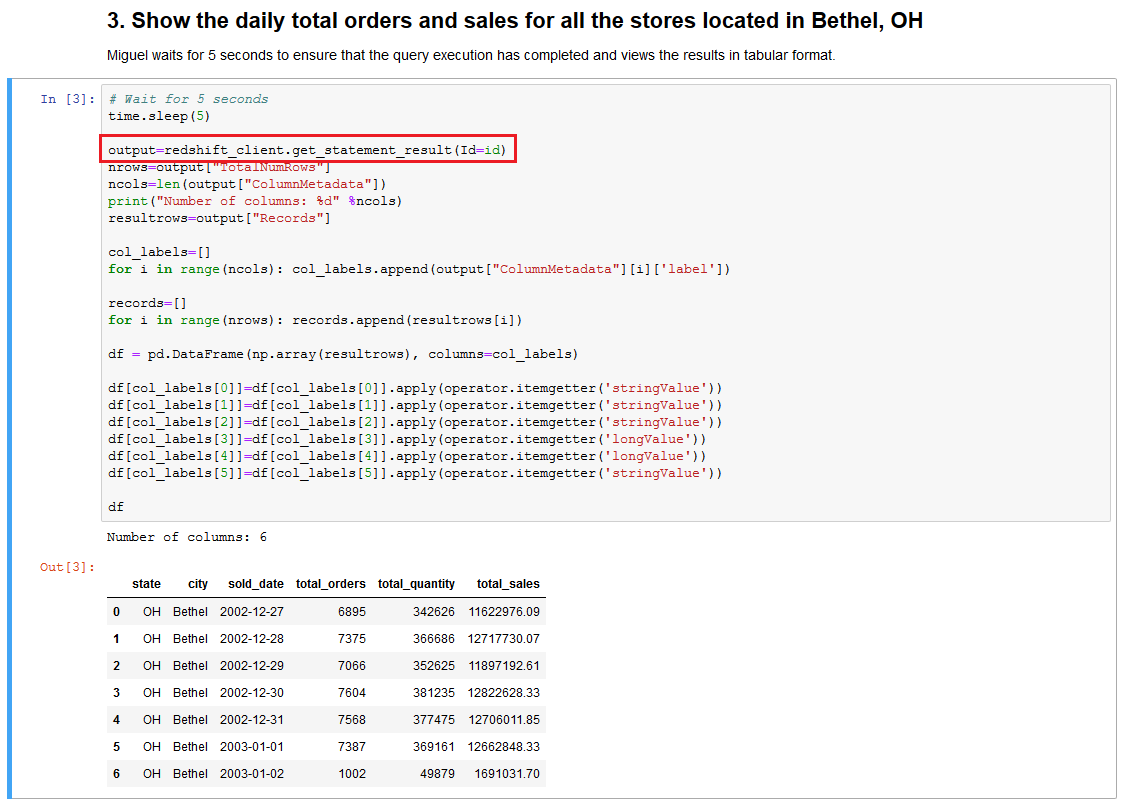
| Lastly, Miguel verifies the store sales metrics for one of the stores has been loaded correctly and confirms that the Weekly Store Sales Performance report for North America region can be generated. |
Go to the dataapi notebook and execute step 3. Inspect the code and note the line that passes the id (highlighted in red) to get the data using Redshift Data API. The get_statement_result command returns a JSON object that includes metadata for the result, the actual result set. In order to display the result in a user-friendly format, the Pandas framework is used.
|
|
Before you Leave
If you want to re-run the demo, you just need to rerun the ETLStateMachine Step Function and provide a unique execution name. The ETL implementation is idempotent i.e. if it fails, you can retry the job without any cleanup. For example, it recreates the stg_store_sales table each time, then deletes target table store_sales with the data for the particular refresh date each time.
If you are done using your cluster, please think about deleting the CFN stack or to avoid having to pay for unused resources do these tasks:
- pause your Redshift Cluster
- stop the Oracle database
- stop the DMS task