Postgres Migration
Demo Video

Before you Begin
Capture the following outputs from the launched CloudFormation template as you will use them in the demo.
https://console.aws.amazon.com/cloudformation/home?region=us-east-1#/stacks?filteringText=&filteringStatus=active&viewNested=true&hideStacks=false
- EC2DeveloperPassword
- EC2HostName
- RedshiftClusterDatabase
- RedshiftClusterEndpoint
- RedshiftClusterPassword
- RedshiftClusterPort
- RedshiftClusterUser
- PostgresUser
- PostgresPassword
- PostgresPort
- PostgresDatabaseName
Client Tool
If you do not have a Remote Desktop client installed, you can use the instructions at this link to do so.
Challenge
Marie has been asked to migrate Red Imports LLC’s on-premises PostgreSQL data to Amazon Redshift in their AWS Account. The PostgreSQL hosts business critical applications. She also needs to make sure that both PostgreSQL and Redshift data warehouses are in sync until all legacy applications are migrated to Redshift. Marie will need to convert DDL structures into Redshift and perform a full data load from PostgreSQL to Redshift. Marie will also need to setup ongoing updates from PostgreSQL to Redshift to keep the data in synch. Marie will accomplish these tasks by doing the following:
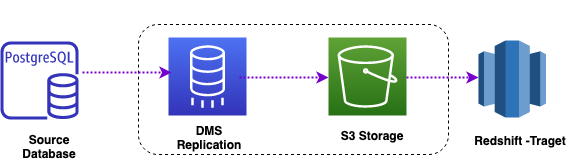
Client Connection
| Say | Do | Show |
|---|---|---|
| Marie logs into her workstation where she has already installed the required tools like SQL Workbench/J to connect to Redshift and PostgreSQL databases. |
The Cloud Formation template deploys a Windows EC2 instance with the required drivers and SQL Workbench/J is already installed. Connect to the EC2 instance using these parameters:
|
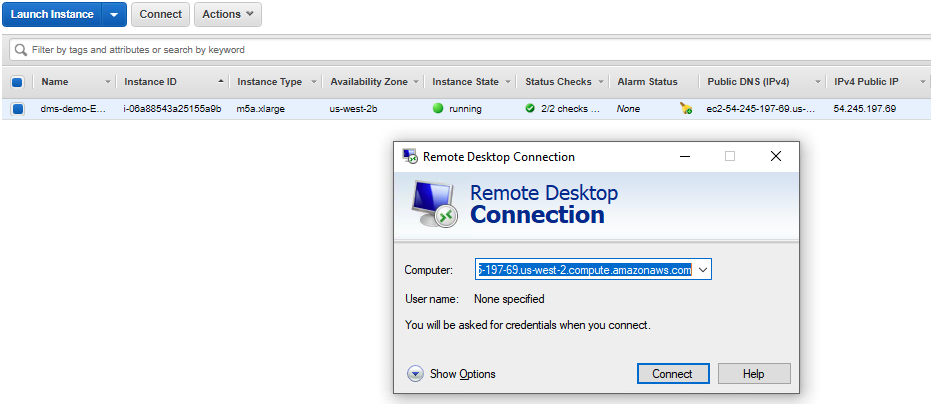
|
| Marie would like to verify that she can connect to target Redshift. |
Open SQL workbench/J from the taskbar shortcut then opens the new connection window. In that, click Manage Drivers in bottom left hand corner and select Redshift. Correct or ensure that the driver path is
|
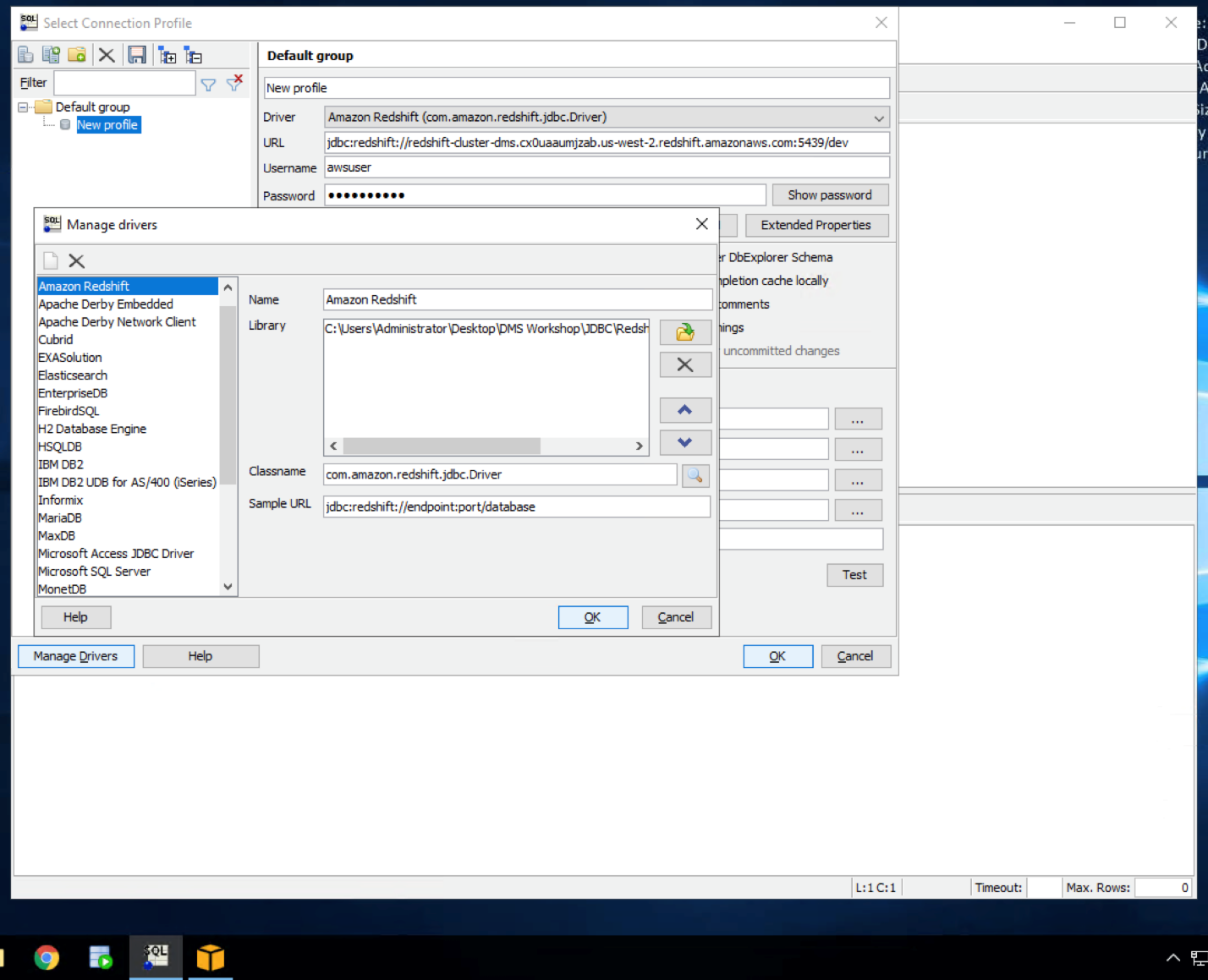
|
| She tests her connection |
On the connectivity screen, enter these inputs: Click |
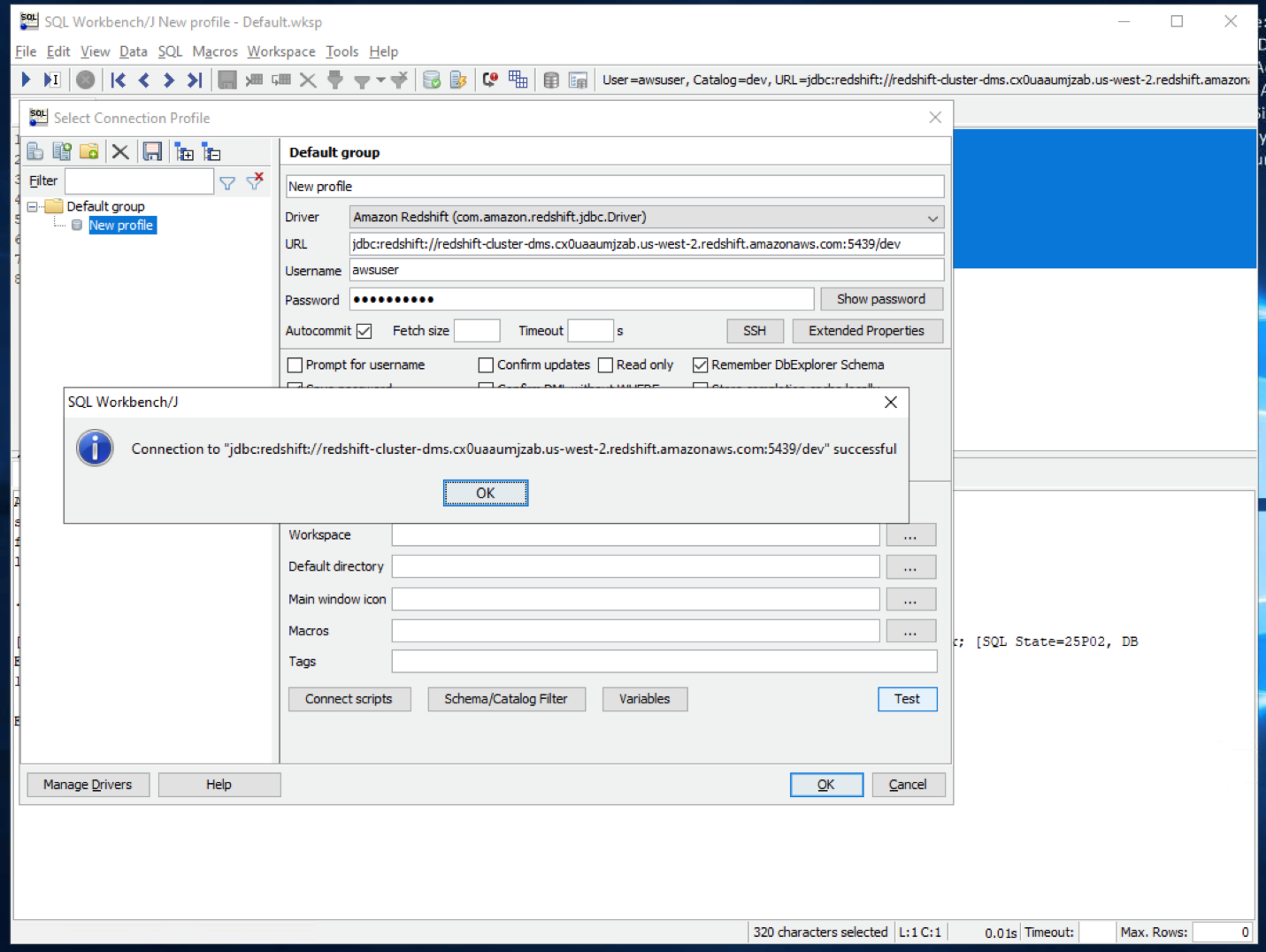
|
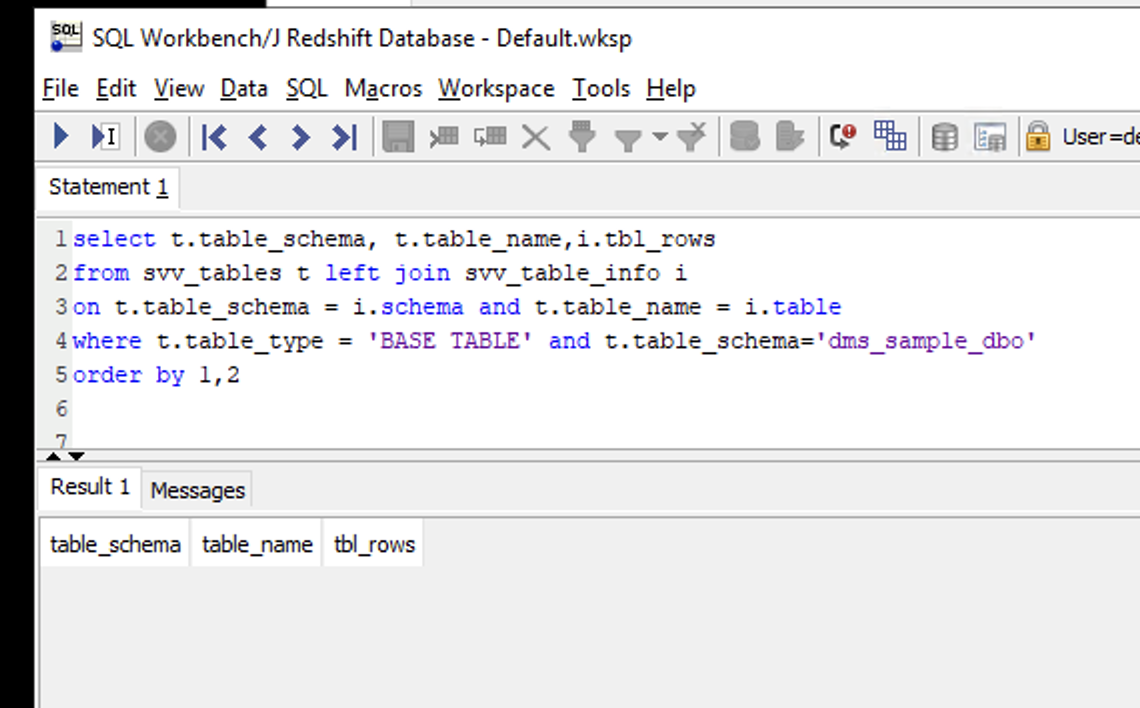
| Marie will confirm that the Postgres data is NOT in Redshift yet. |
Execute the following SQL statement in Redshift and confirm that the result set is empty
|
|
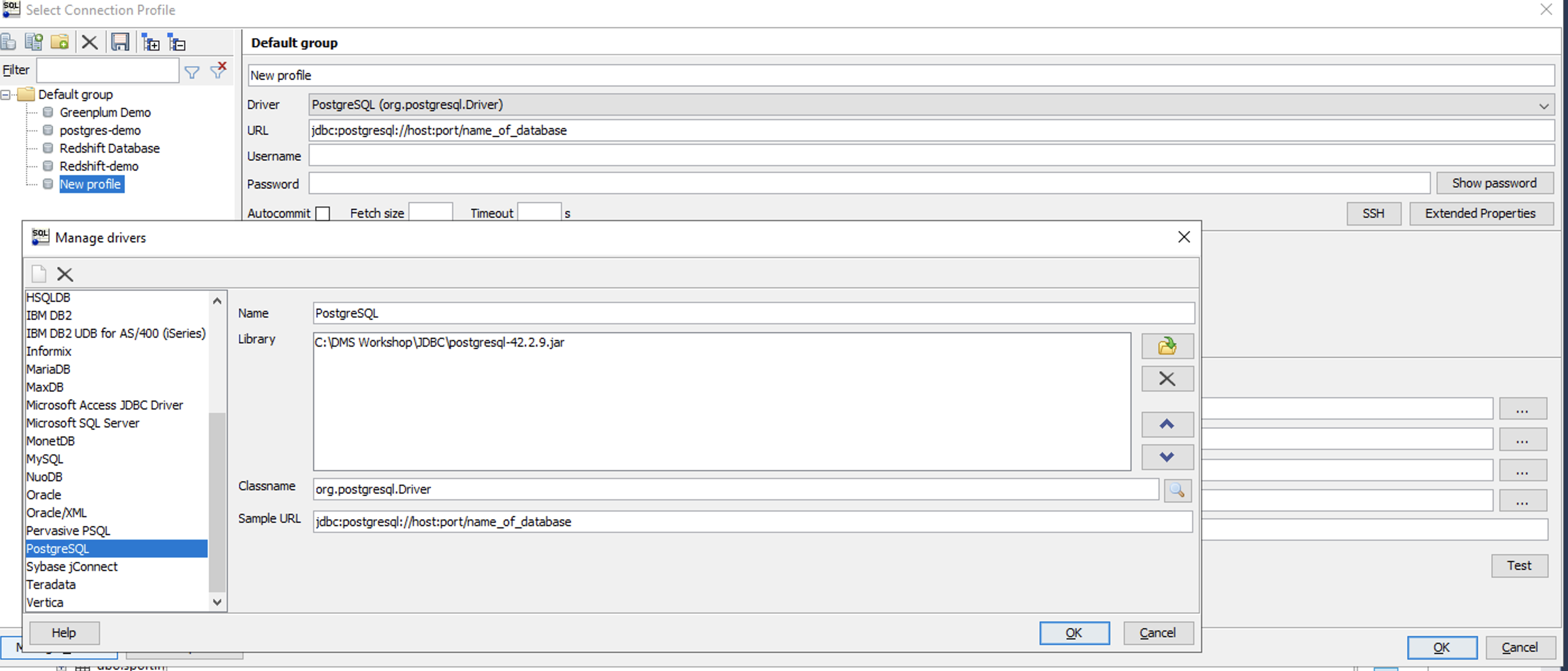
| Marie would like to verify that she can connect to source Postgres using a SQL client such as SQL workbench/J |
Open a new window and/or connection in SQL workbench/J from the taskbar shortcut, which opens the new connection window. In that, click Manage Drivers in bottom left hand corner and select Postgres. Confirm or Correct the driver path is:
|
|
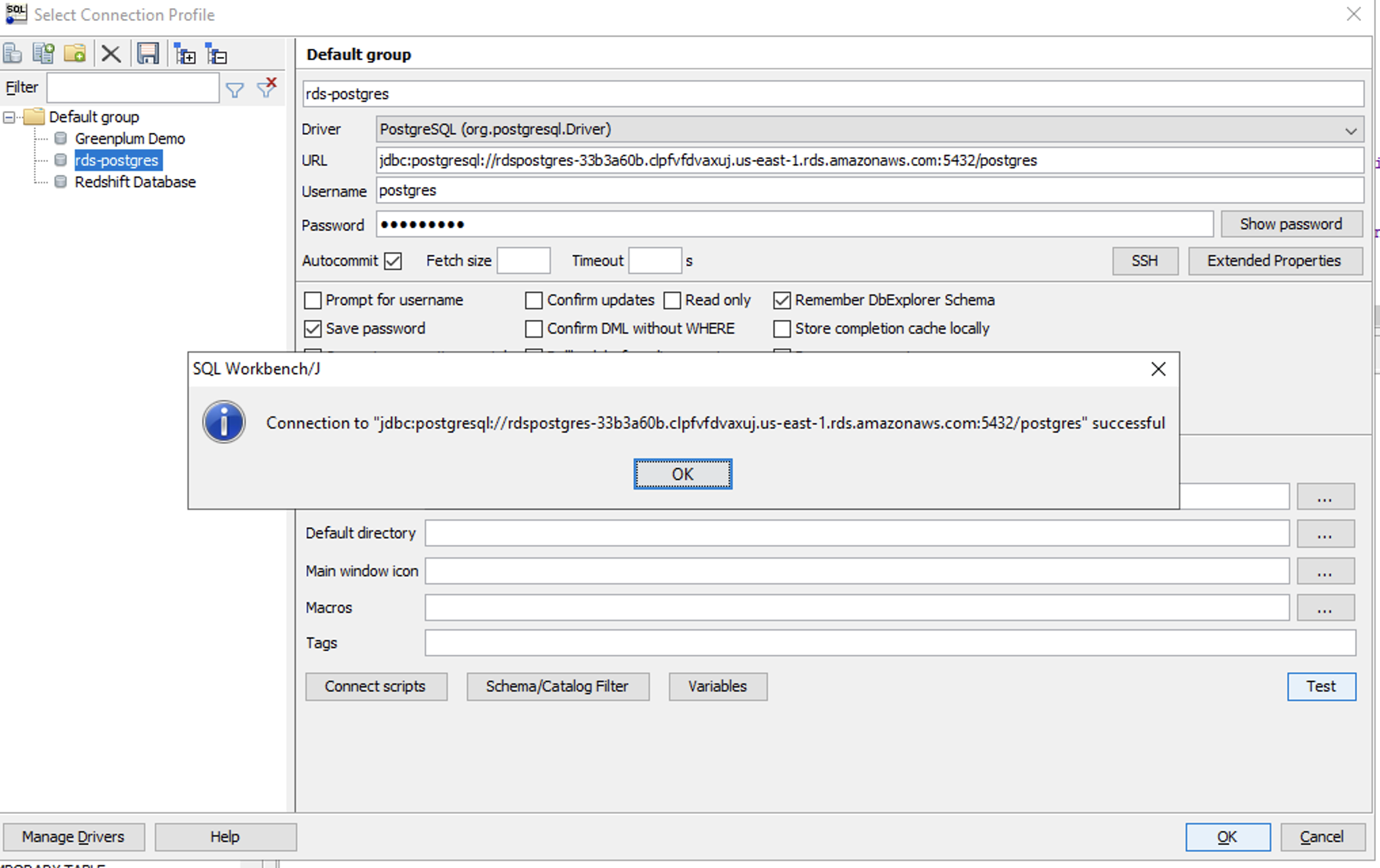
| She tests her connection to the Postgres source database. |
On the connectivity screen, enter these inputs: Click |
|
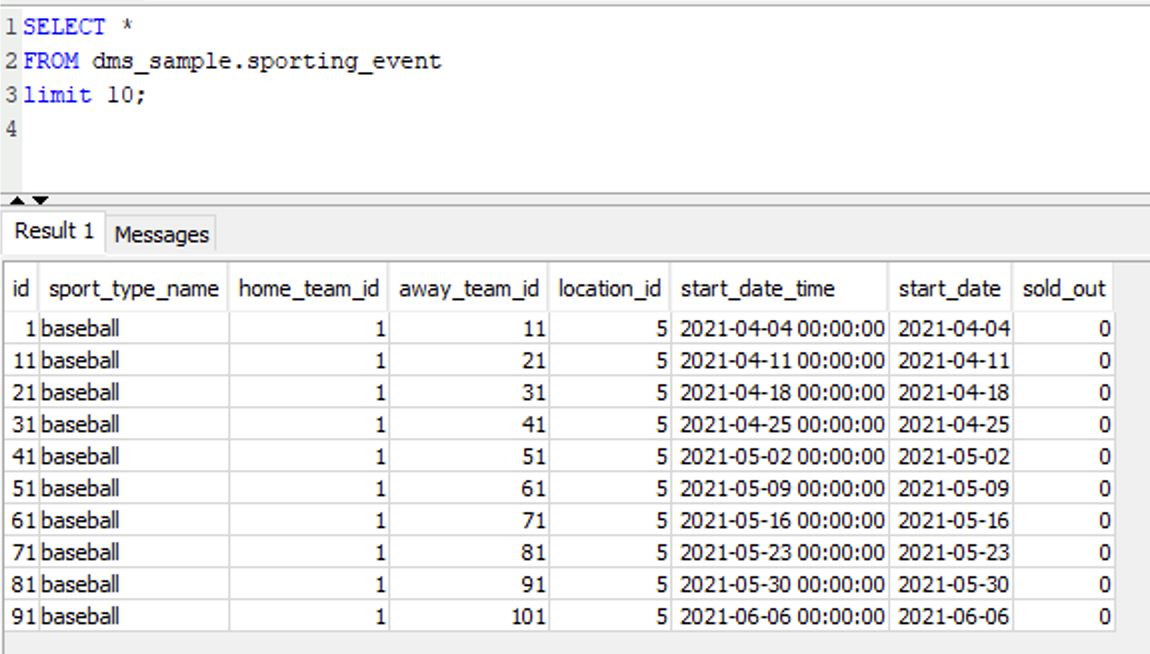
| She confirms that the data for migration is in Postgres |
Execute the following SQL in Postgres and confirm there is data in the result set: |
|
Migrate the data
| Say | Do | Show |
|---|---|---|
| Marie needs to migrate data from Postgres to Redshift using Amazon Data Migration Service (DMS). She must create a migration task in DMS to accomplish this using the AWS Console. |
Navigate to DMS service page on AWS Console. A task to replicate all existing data and as well as ongoing changes from Postgres to Redshift has already been created by the CloudFormation template. Navigate to Database migration tasks. You should be able to see a task in Ready state.
|

|
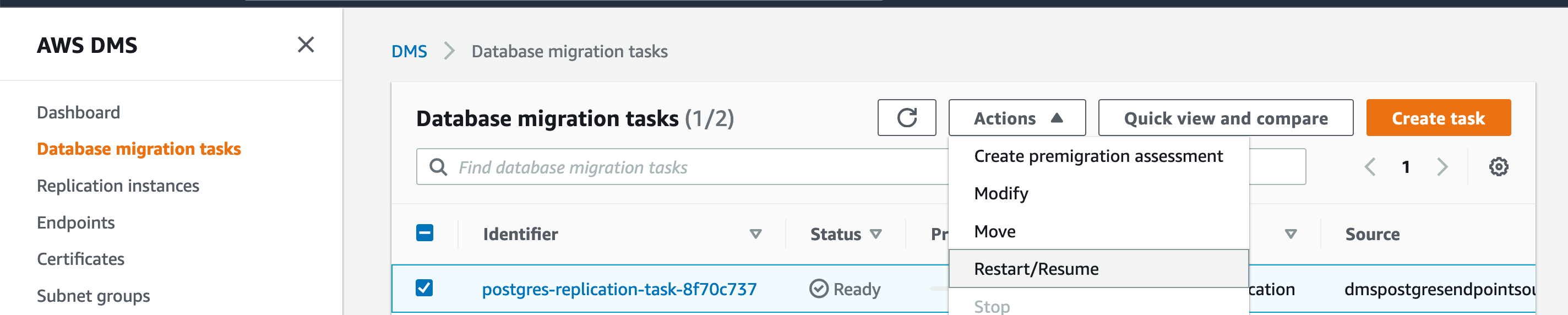
| Marie needs to launch the migration to do the initial data migration to Redshift. |
Select the replication task > click Action > restart/resume
This should take about 10 minutes to complete, consider starting the task before your customer meeting or incorporate this wait time in your agenda. |
|
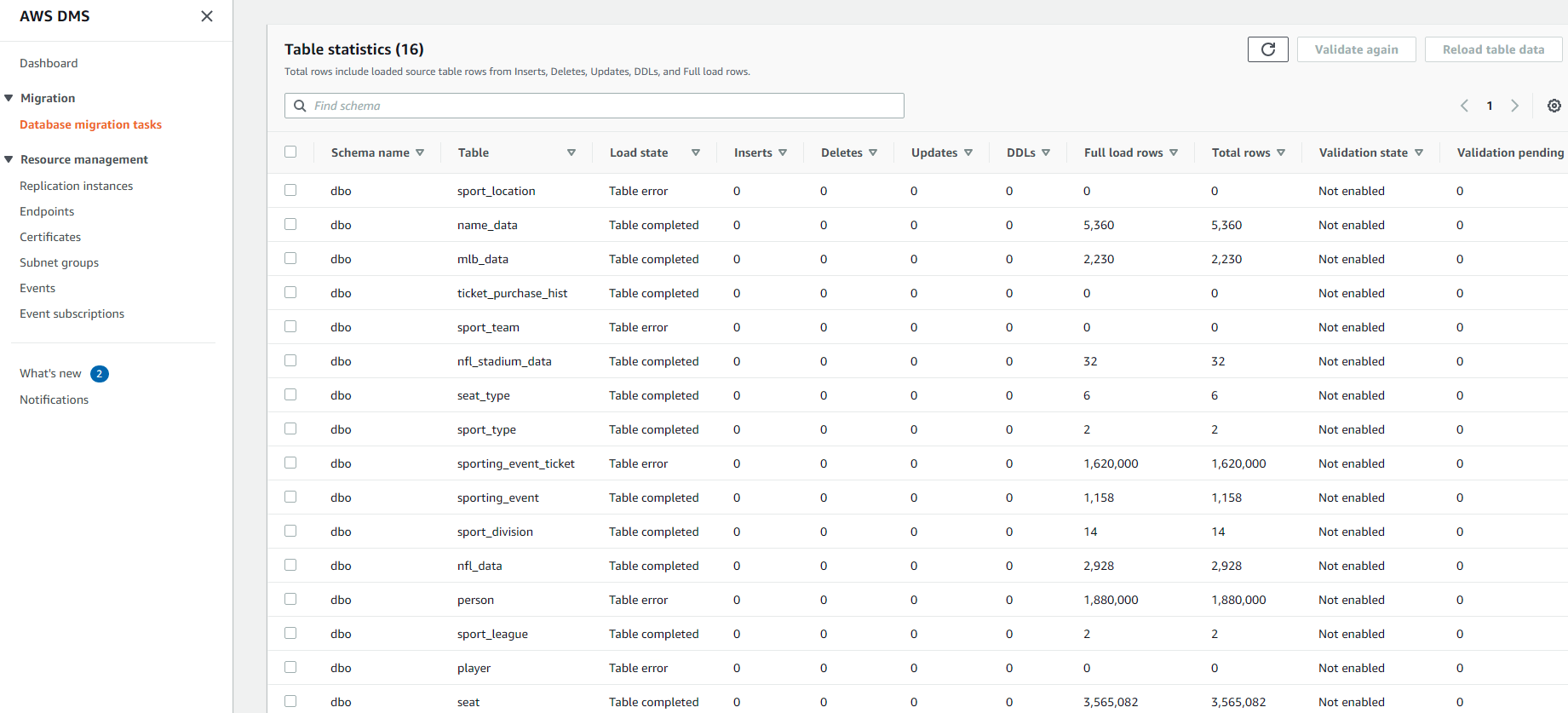
If Marie wants to view the statistics of what data is getting transferred, she can go to the summary page to view some details. The Table statistics tab allows her to view the statistics of how many records are getting transferred via DMS.
|
Click full load task and click Table statistics.
|
|
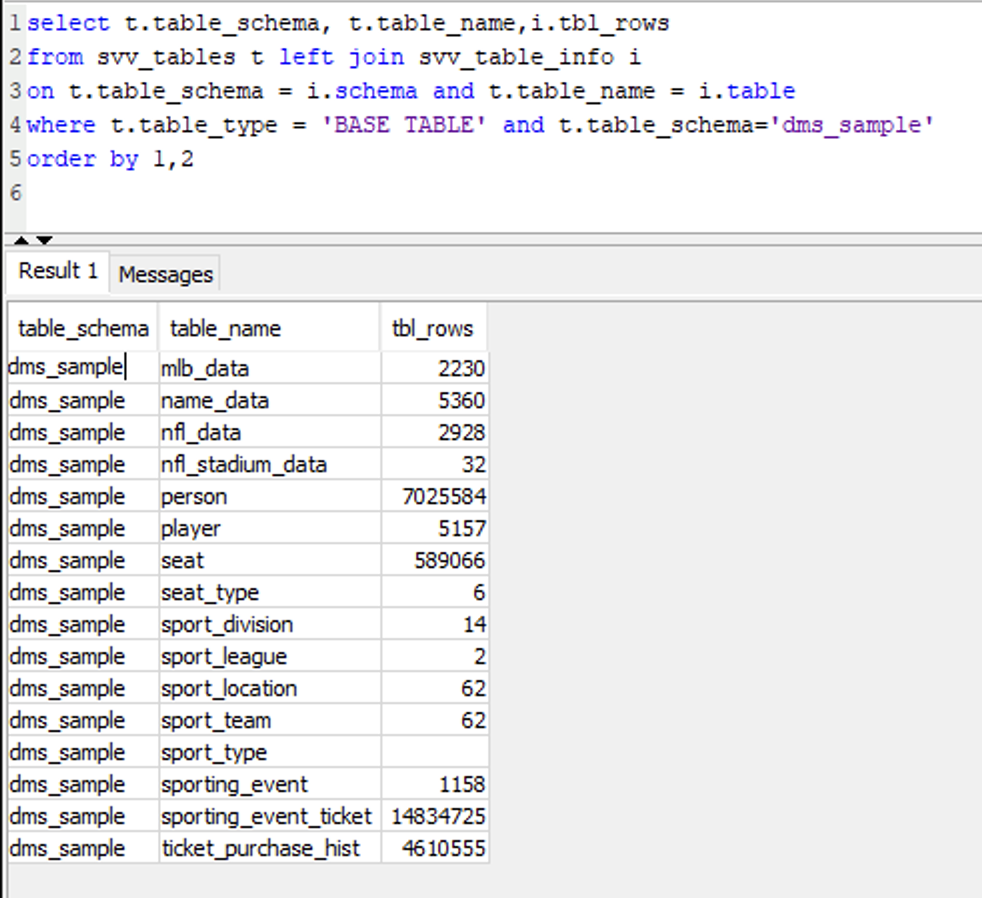
| She can also verify that the data is getting migrated to Redshift using SQL workbench/J. She can compare the result of a query to the table statistics in DMS to ensure all the data is copied over successfully. |
Execute this SQL in Redshift to view the record count
|
|
Keep the data in sync
| Say | Do | Show |
|---|---|---|
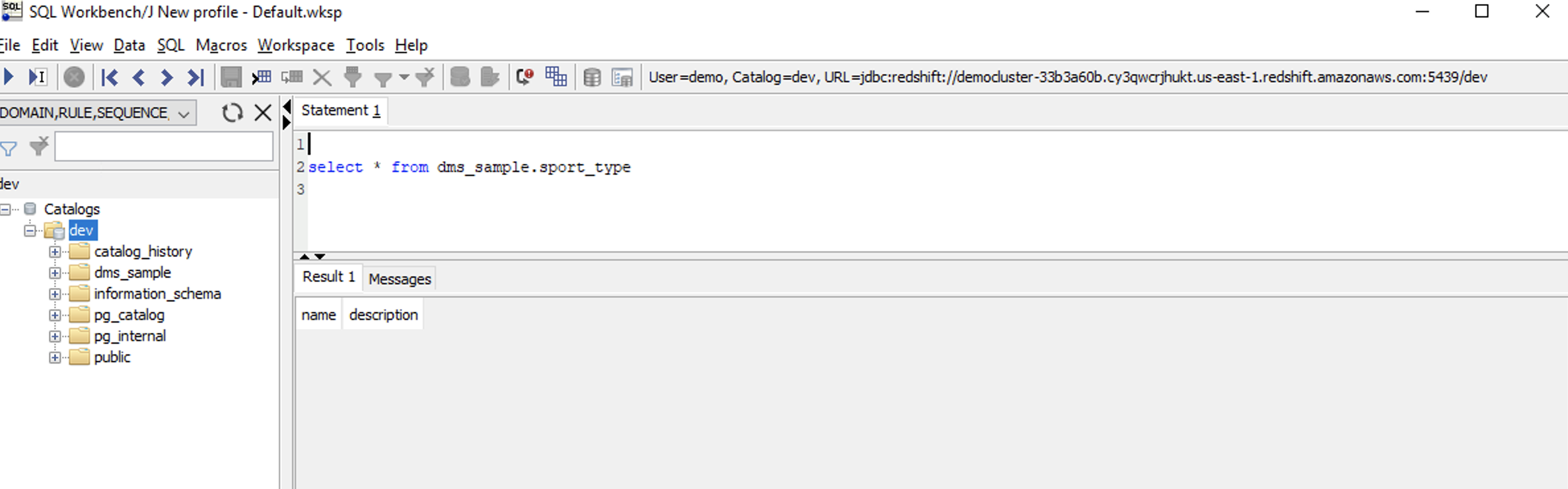
Marie wants to verify the change data capture functionality is working correctly. She will create some new records and verify that they are migrated into Redshift automatically. But first she checks how many records are in the table sport_type
|
Execute the command below in Redshift to view the data in the |
|
| She can view this table in Postgres as well. This also shows zero records. |
Execute the command below in Postgres to view the data in the sport_type table.
|
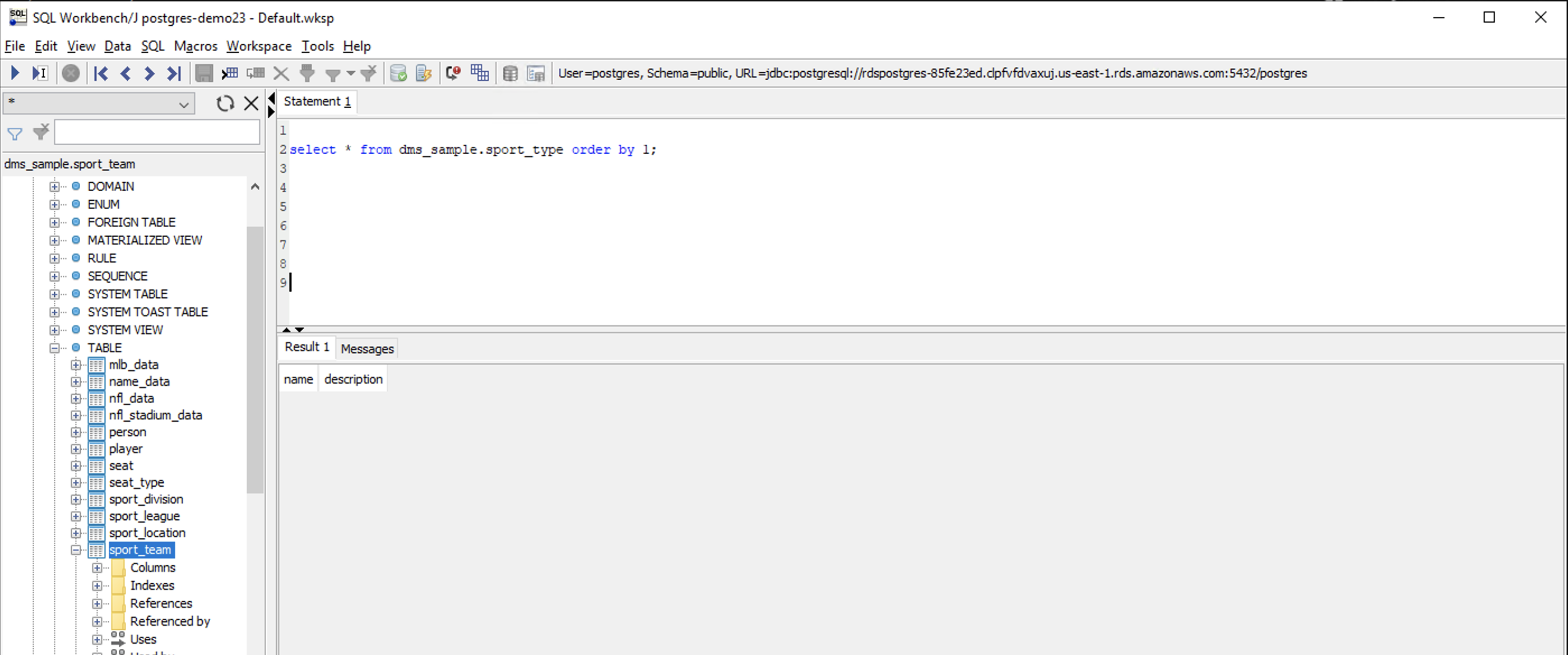
|
Marie wants to confirm that the CDC process is operational. For that she will insert some records in the sport_type table in Postgres Server. She will insert a few rows in this table in the source Postgres and see if it gets migrated to Redshift.
|
Execute below command in Postgres to insert five additional records in sport_type table.
|
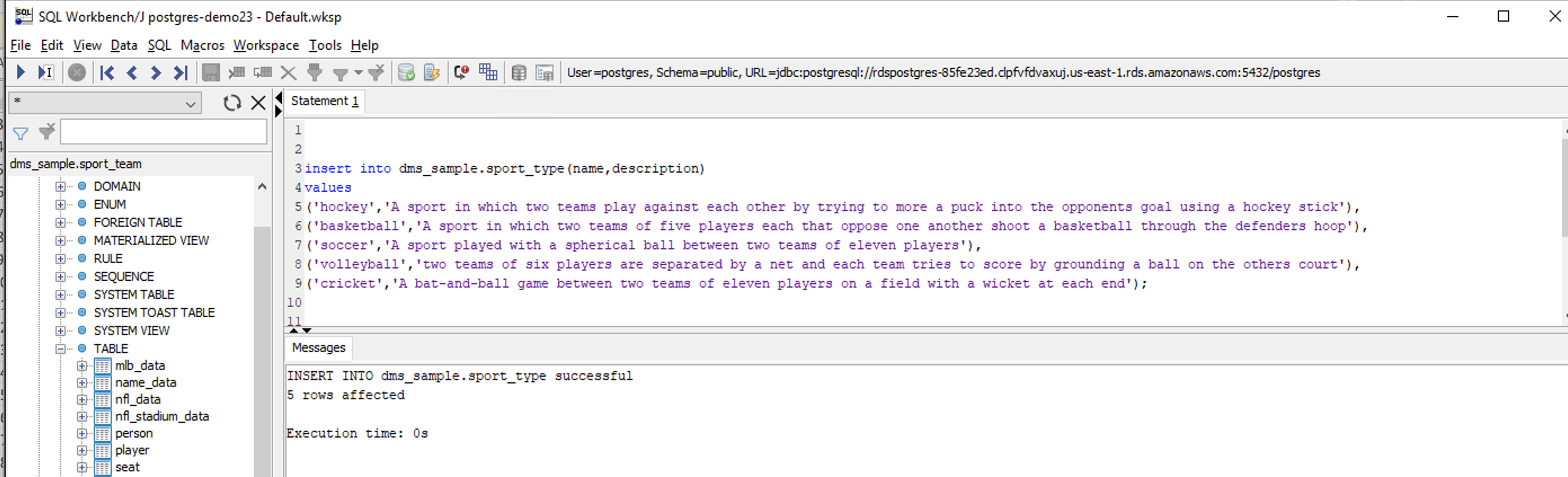
|
| When she views the table again in Postgres, she should see five records in total now. |
Execute below command in Postgres to view data in the sport_type table.
|
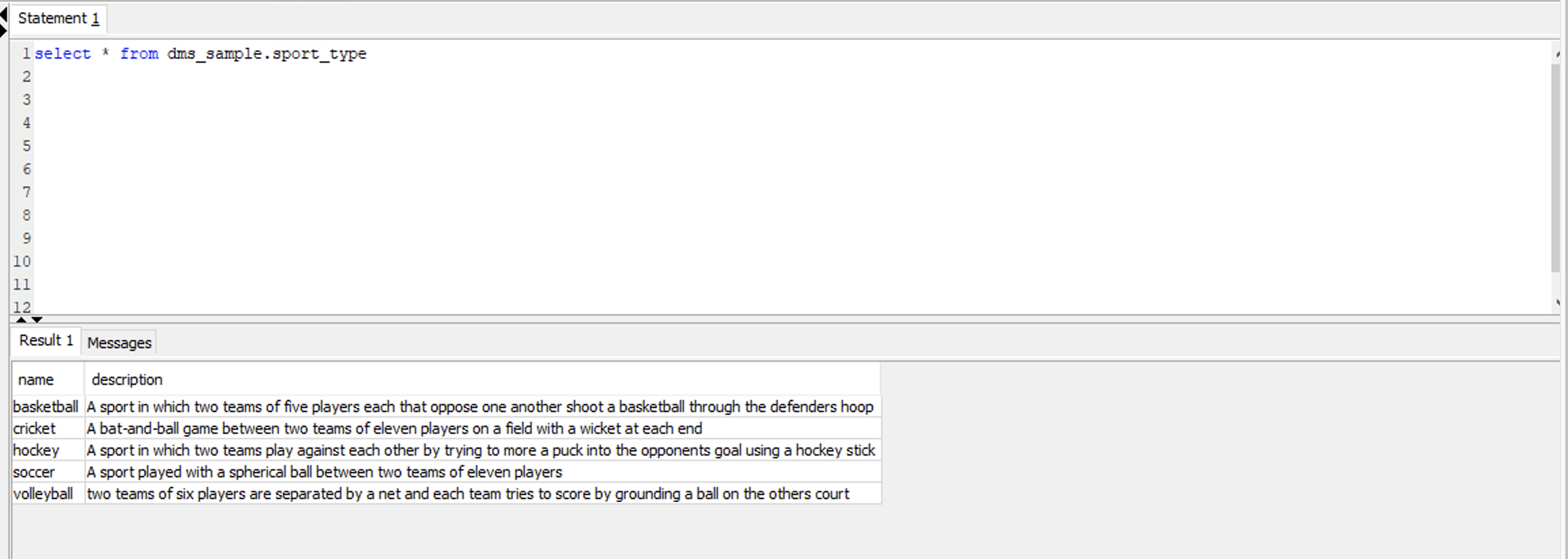
|
|
When she goes back to Redshift, she should see the five newly inserted records there as well.
While this is real-time, there could be a slight delay in data copy. |
Execute below command in Redshift to view the data in the sport_type table.
|
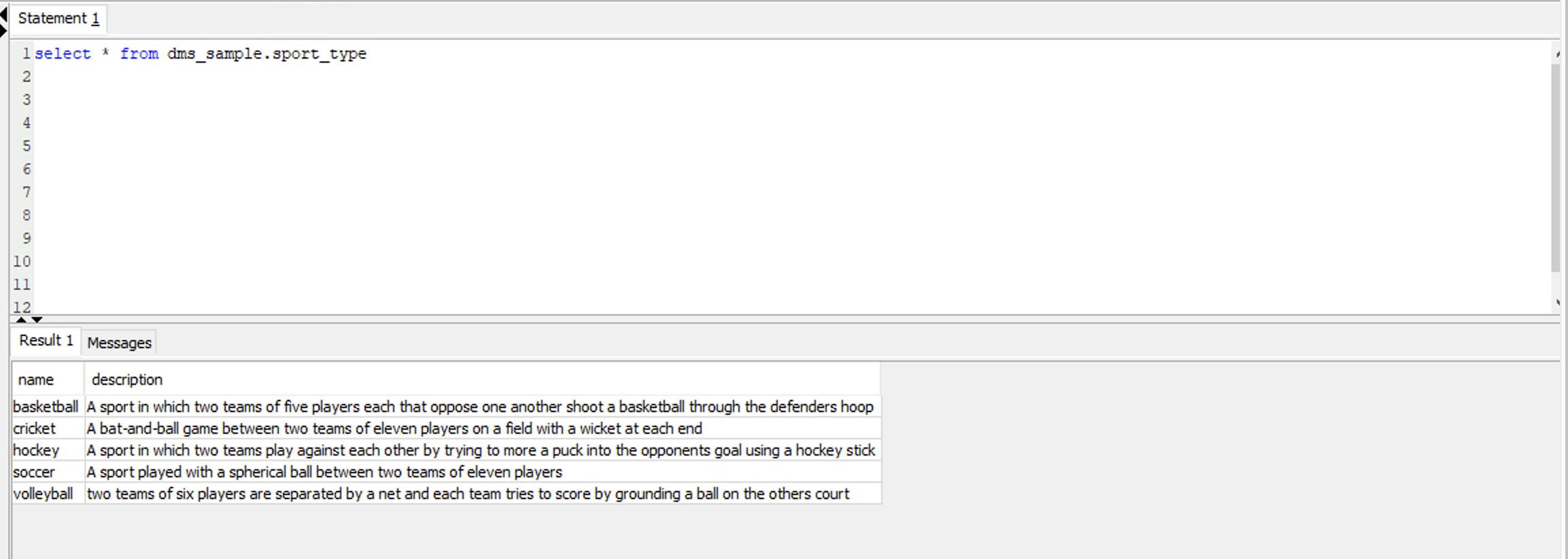
|
|
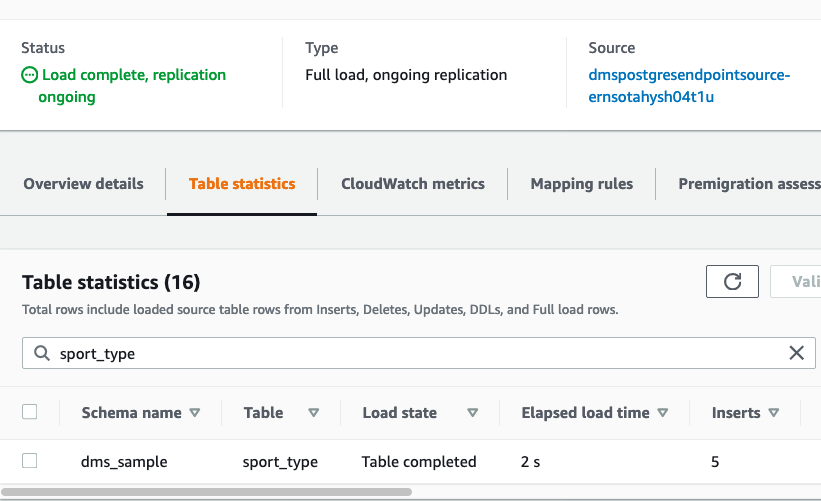
If she wants to view the logs of the CDC process, she can used the DMS console to see a table of metrics that shows a number of key statistics for each table. |
Navigate to DMS page in the AWS console and select the Ongoing Replication task and click table statistics.
|
|
Before you Leave
To reset your demo, drop the tables created by executing the following SQL statement in Redshift.
drop table if exists dms_sample.person cascade;
drop table if exists dms_sample.ticket_purchase_hist cascade;
drop table if exists dms_sample.sporting_event_ticket cascade;
drop table if exists dms_sample.sporting_event cascade;
drop table if exists dms_sample.seat cascade;
drop table if exists dms_sample.sport_type cascade;
drop table if exists dms_sample.sport_location cascade;
drop table if exists dms_sample.sport_team cascade;
drop table if exists dms_sample.sport_league cascade;
drop table if exists dms_sample.sport_division cascade;
drop table if exists dms_sample.seat_type cascade;
drop table if exists dms_sample.player cascade;
drop table if exists dms_sample.name_data cascade;
drop table if exists dms_sample.nfl_stadium_data cascade;
drop table if exists dms_sample.nfl_data cascade;
drop table if exists dms_sample.mlb_data cascade;
Execute the following SQL on Postgres to delete the inserted records:
delete from dms_sample.sport_type where name in ('hockey', 'basketball', 'soccer', 'volleyball', 'cricket');
If you are done with your demo, please consider deleting the CFN stack. If you would like to keep it for use in the future, you may do the following to avoid having to pay for unused resources:
- Pause your Redshift Cluster
- Pause your Postgres Server
- Stop the DMS task
- Stop the EC2 instance