Machine Learning - BYOM to Redshift ML
Demo Video
Coming Soon
Client Tool
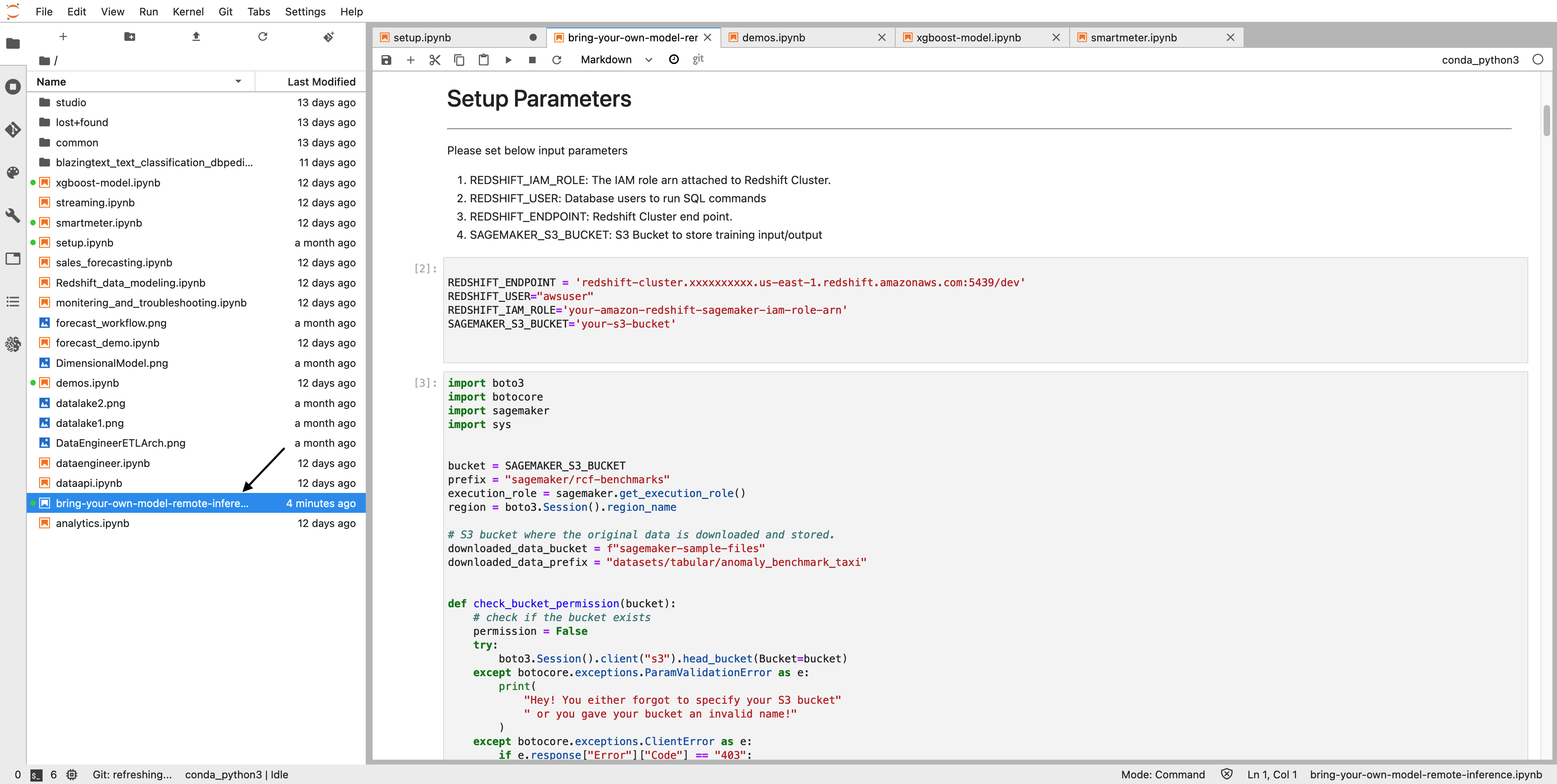
This demo will use Amazon Sagemaker notebook to create a Sagemaker model.
Please go through Steps 1 and 2 from Demo preparation first.
Then open notebook bring-your-own-model-remote-inference.ipynb.
Execute steps in notebook to create SageMaker model that will be used in the demo.
Challenge
Kim is a Data Scientist at a ride sharing company and she is tasked to employ ML methodologies for identifying anomolies predicting special events by analyzing ridership data. Amazon SageMaker Random Cut Forest (RCF) is an algorithm designed to detect anomalous data points within a dataset. Examples of anomalies that are important to detect include when website activity uncharacteristically spikes, when temperature data diverges from a periodic behavior, or when changes to public transit ridership reflect the occurrence of a special event. In this case Kim will use Random Cut Forest (RCF) model to detect anomolies. We downloaded the data and stored it in an Amazon Simple Storage Service (Amazon S3) bucket. The data consists of the number of New York City taxi passengers over the course of 6 months aggregated into 30-minute buckets. We naturally expect to find anomalous events occurring during the NYC marathon, Thanksgiving, Christmas, New Year’s Day, and on the day of a snowstorm. We then use this model to predict anomalous events by generating an anomaly score for each data point.
To accomplish this Kim will have to do the following steps.
The screenshots for this demo will leverage the SQL Client Tool of SQLWorkbench/J so be sure to complete the setup before proceeding. Alternatives to the SQLWorkbench/J are the Redshift Query Editor.
Data Preparation
| Say | Do | Show |
|---|---|---|
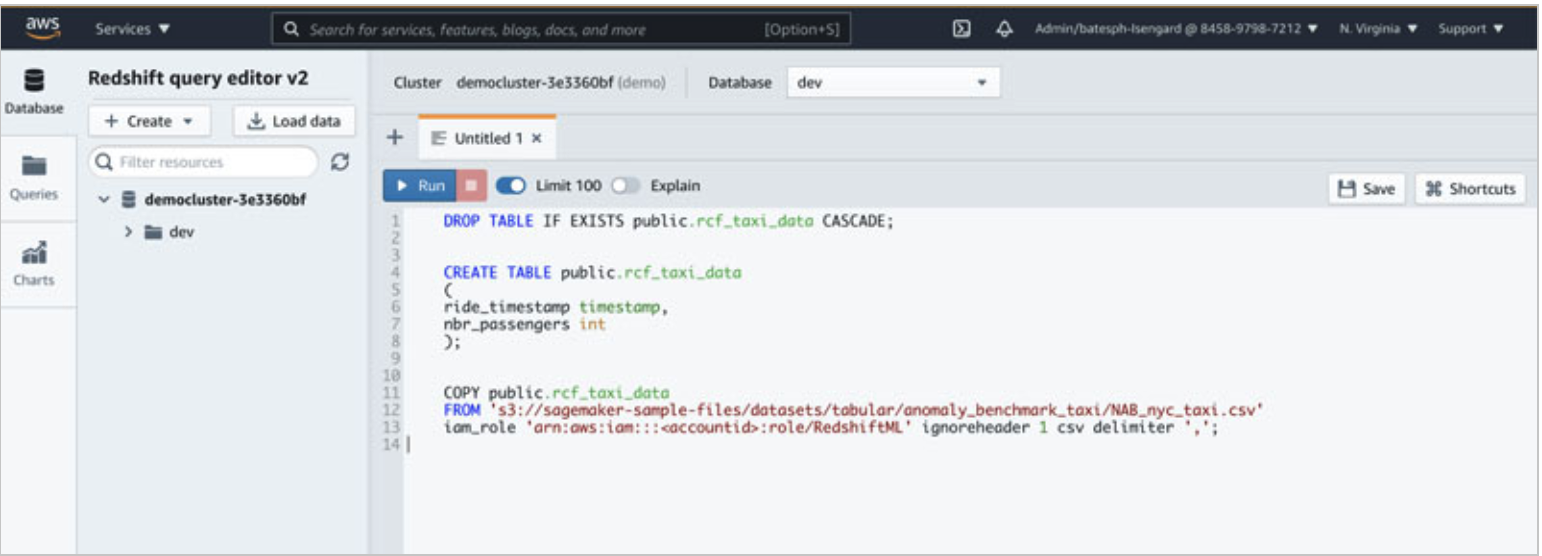
| Kim downloaded the data and stored it in an Amazon Simple Storage Service (Amazon S3) bucket. The data consists of the number of New York City taxi passengers over the course of 6 months aggregated into 30-minute buckets. She creates a data preparation script and then run the same to load the data into Redshift tables - rcf_taxi_data |
Go to Aamazon Redshift Cluster created by cloud formation template and You can use the Amazon Redshift query editor v2 to run these commands. Create the schema and load the data in Amazon Redshift using the following SQL statements.
Amazon Redshift now supports attaching the default IAM role. If you have enabled the default IAM role in your cluster, you can use the default IAM role as follows. |
|
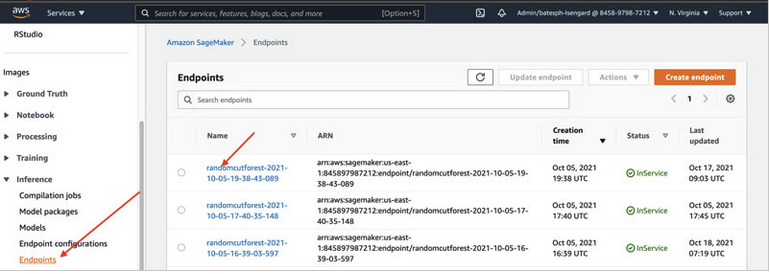
| Kim is using the model created in Amazon Sagemaker from the first step. She wants to use this model for the analysis in Redshift via remote inference. | Go to Amazon SageMaker console, under Inference in the navigation pane, choose Endpoints to find the model created in previous Sagemaker step. Capture the ‘endpoint’ of the model. |
|
| Now Kim will use Amazon Sagemaker end point and Create a model in Amazon Redshift ML using the SageMaker endpoint she captured in the previous step. |
Go to Redshift query editor v2 , update the IAM roles attached to the Redshift cluster and execute SQL below.
You can also use the default IAM role with your CREATE MODEL command as follows: |

|
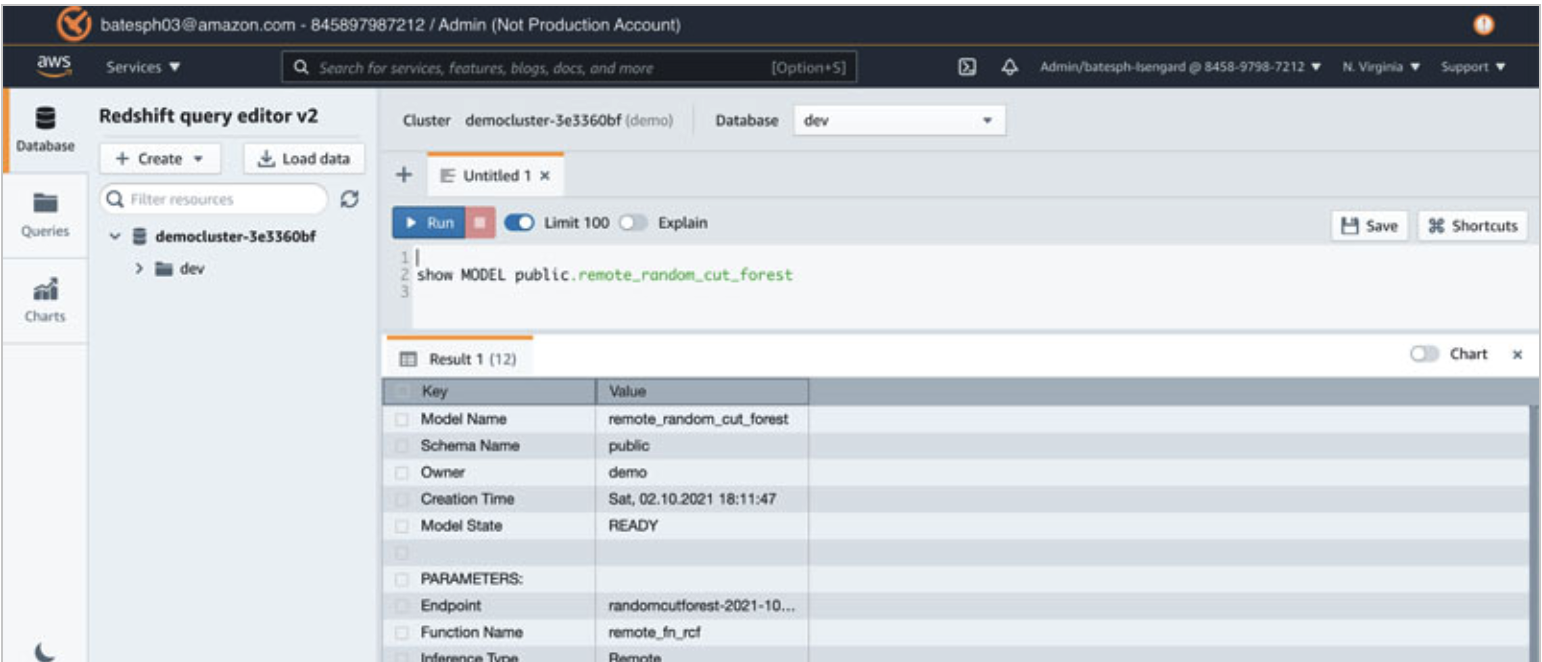
| Kim checks if the model creation is complete and ready for use. |
Go to Redshift query editor v2 and use the show model command to view the status of the model.
Once the model state says ‘READY’, then go to next step. |
|
Model Evaluation
| Say | Do | Show |
|---|---|---|
| Next, Kim will use this model and compute anomoly scores for entire taxi dataset. |
Go to Query editor and run the inference query using the function name from the create model statement.
|
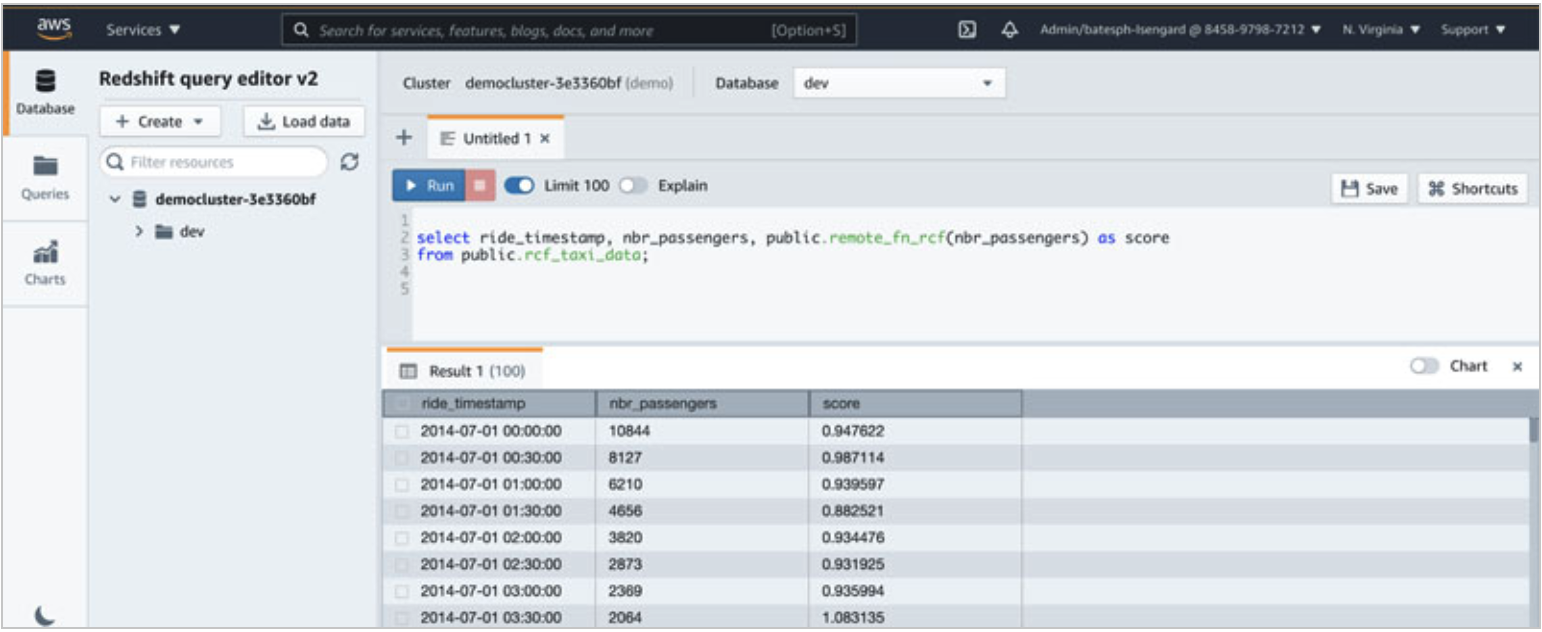
|
Model Inference
| Say | Do | Show |
|---|---|---|
|
Now Kim has anomaly scores. She need to check for higher-than-normal anomalies.
The data in the screenshot shows that the biggest spike in ridership occurs on November 2, 2014, which was the annual NYC marathon. We also see spikes on Labor Day weekend, New Year’s Day and the July 4th. |
Run query for any data points with scores greater than three standard deviations (approximately 99.9th percentile) from the mean score.
Go to query editor and execute query below.
|
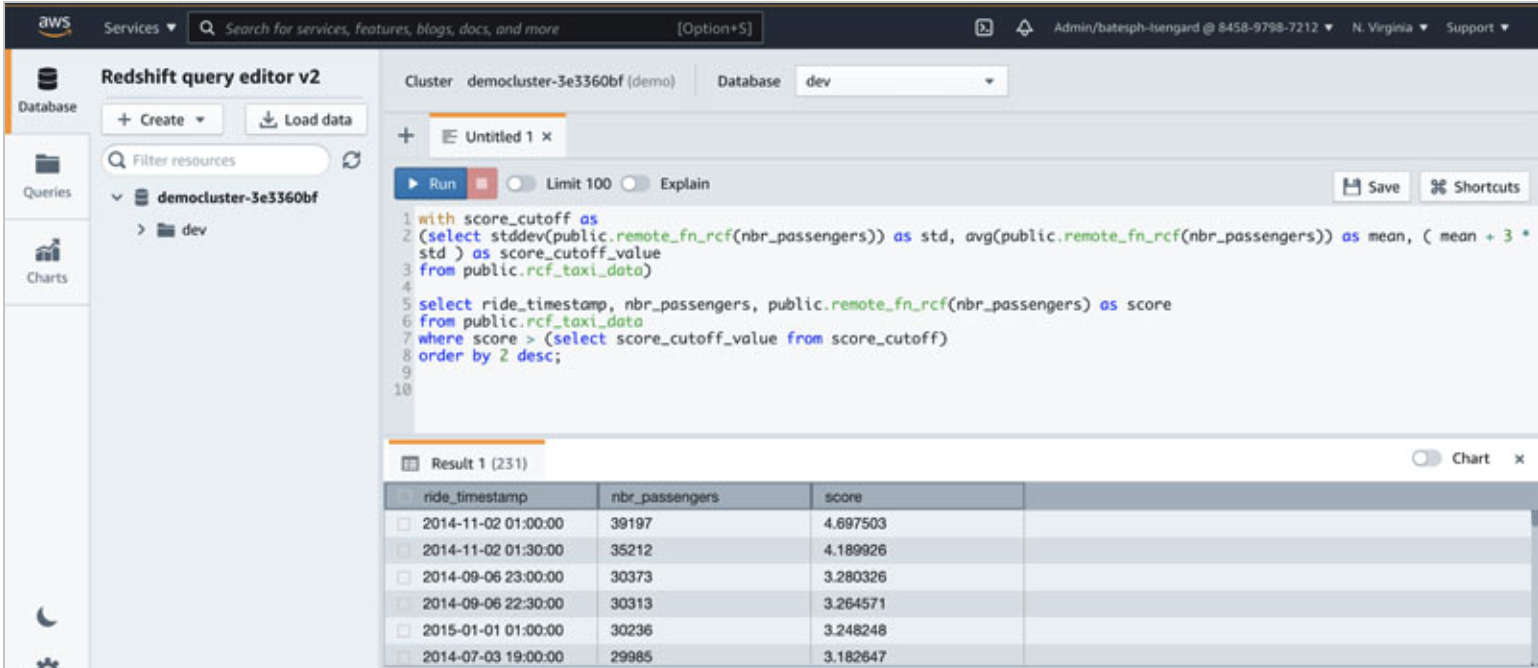
|
Before you Leave
Please execute the Cleanup step to clear out any changes you made to Redshift database during the demo.
drop table public.rcf_taxi_data;
drop model public.remote_random_cut_forest;
If you are done using your cluster, please think about deleting the CFN stack or to avoid having to pay for unused resources do these tasks:
- Pause your Redshift Cluster