Redshift Configuration Comparison
Demo Video
Coming soon!
Before you Begin
Capture the following outputs from the Outputs tab from running the main Cloud Formation template:
- TaskDataBucketName
- SubnetAPublicId
- VpcId
The state machine can take up to 1 hour to run, so you may want to run the execution steps before your customer meeting.
Client Tool
We will leverage Redshift Query Editor for this demo.
Challenge
Manhar has been asked to find the best configuration for his Data Warehouse, which would be used for real-time dashboards. The dashboard has a hard Service Level Agreement (SLA) requirement to meet 20 seconds for a single user query running sequentially and a 10 second SLA for 5 concurrent queries. He needs to find the best Redshift cluster configuration that can meet this requirement. For that, he would like to test different node count and node types and also different workload management settings in Redshift to determine his best configuration. Doing this manually could be a time consuming task and repeating it could prove difficult. To overcome this challenge he has developed an automation script that leverages AWS Step Functions and AWS Lambda to run an end-to-end automated test to find the best Redshift configuration based on price/performance expectations. Below image shows what the overall architecture looks like. Manahar will:
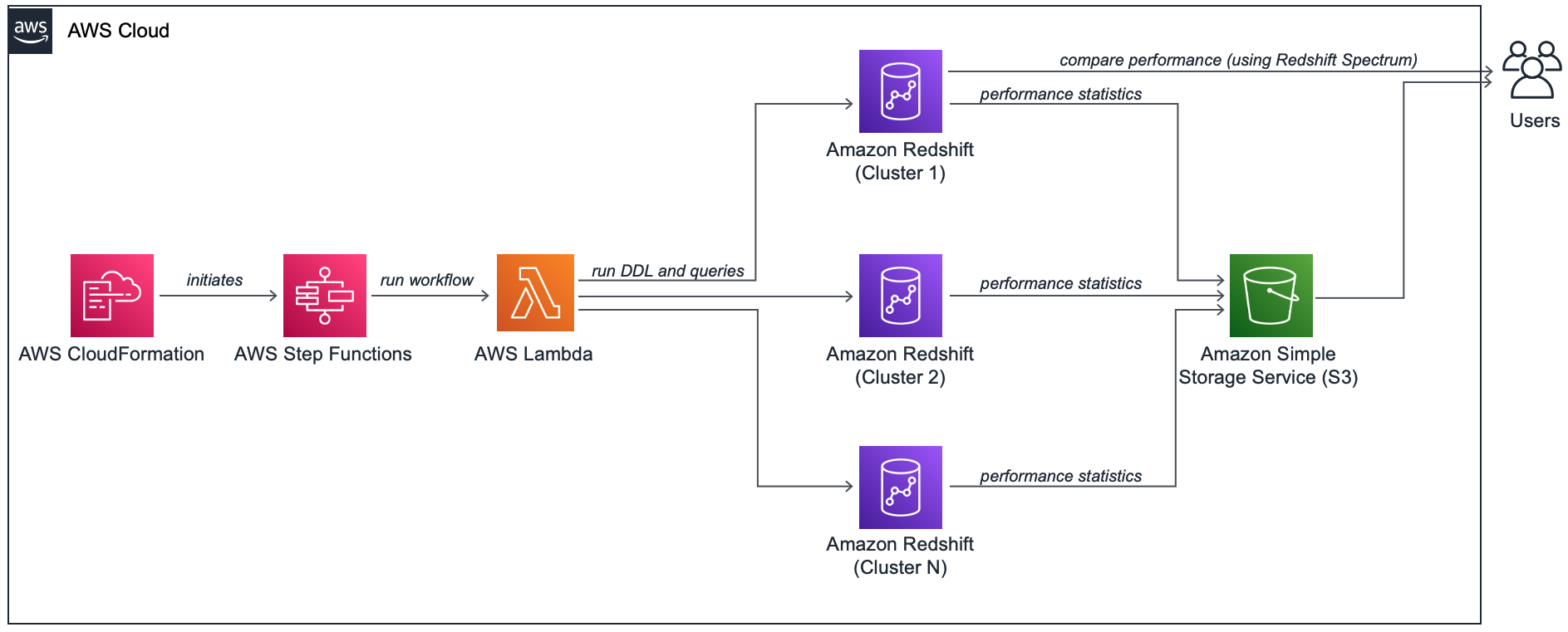
Configure and Run Automation Tool
| Say | Do | Show |
|---|---|---|
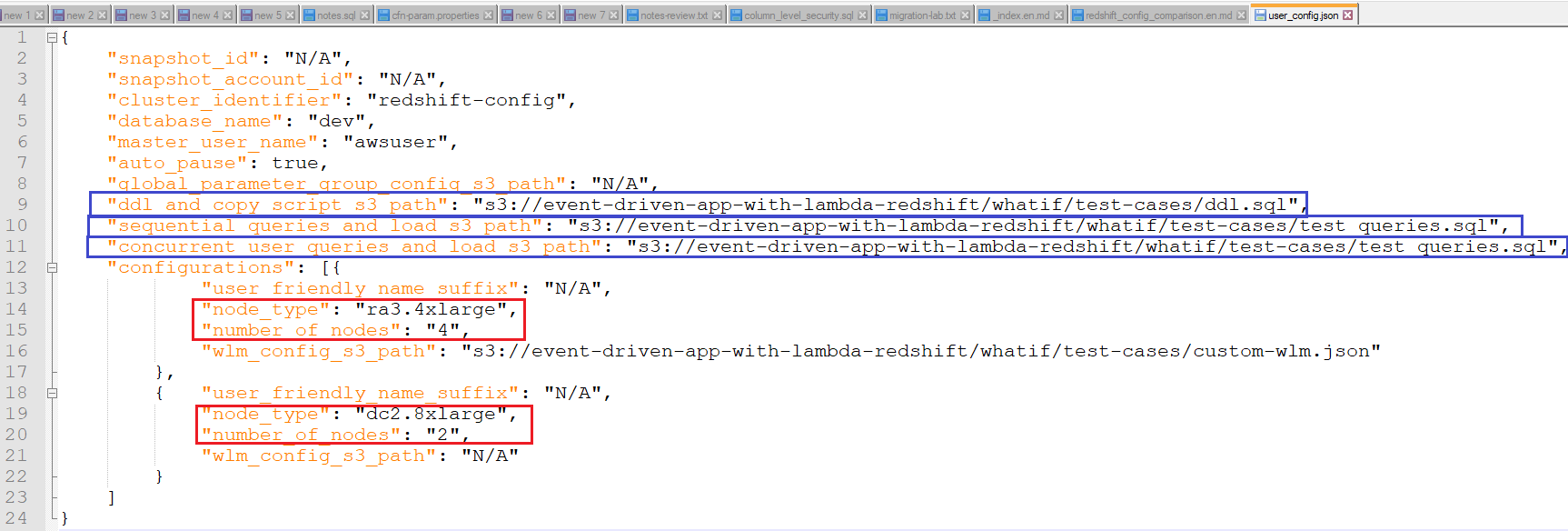
Manhar opens up a configuration file user_config.json, where he can put the node configurations he would like to test his queries. He would like to test 2 nodes of DC2.8XLarge and also 4 nodes for RA3.4XLarge. He has already uploaded his DDL and select query scripts in S3, for which he would like to test Redshift performance. He updates these S3 paths in his configuration file:
Alternatively, he could have selected an existing Redshift cluster snapshot, which would have saved time on running the DDL statements from scratch. He could have also taken a hybrid approach on restoring from snapshot and then add DDLs for just couple of tables he might like to test. For the concurrent queries test, this process breaks each SQL statement in his script and runs them in parallel using Amazon Redshift Data API. Number of concurrent sessions is therefore same as number of SQL Statements in this script. Please also note that each Data API call takes around 0.4 seconds to submit to statements. Therefore to perform concurrency test for very short queries, a tool like JMETER might be better suited. |
Right-click and download this file to your local machine. Open user_config.json file in an editor like Atom or Notepad++ and show these sections to the customer:
|
|
|
He then uploads his |
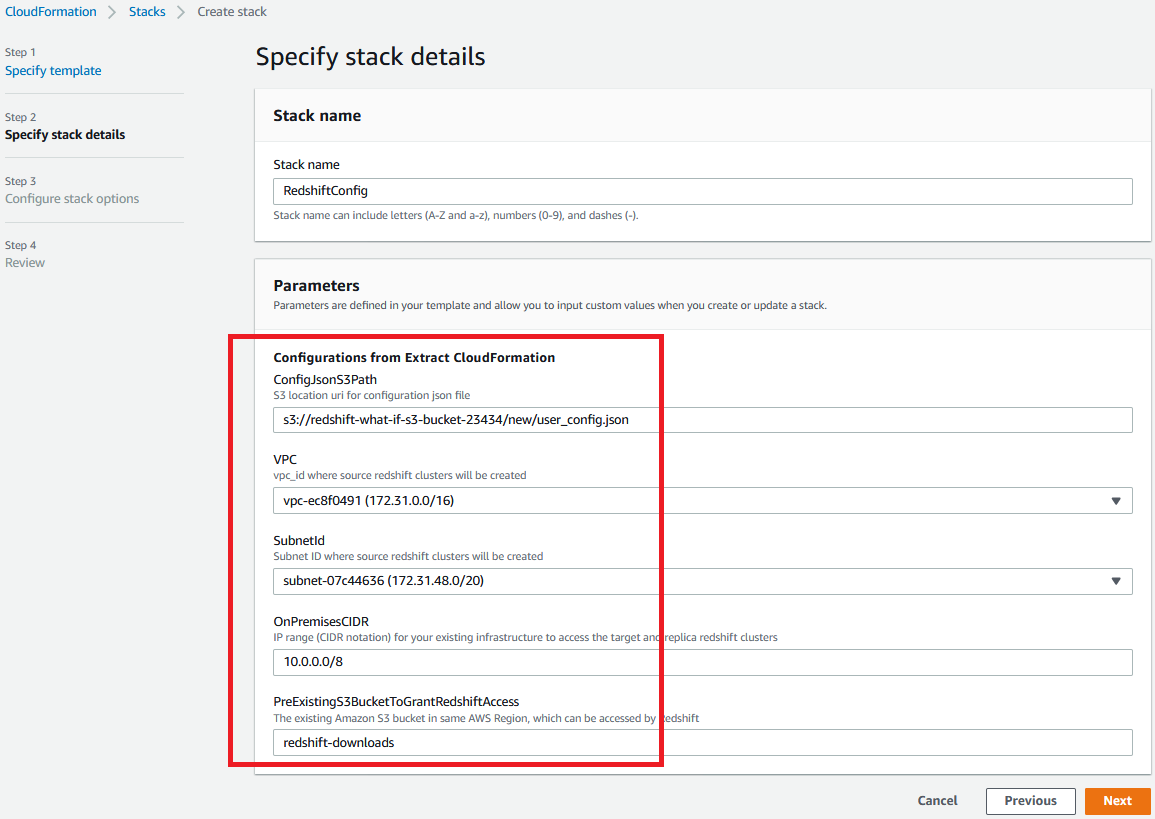
Upload the file to the S3 Bucket that you captured above as TaskDataBucketName. Navigate to your AWS Console S3 location where you uploaded the user_config.json file and copy the S3 URI.
|
|
|
After that, he would launch and deploy an AWS CloudFormation template to perform this end-to-end testing. |
Click here to launch the Cloud Formation Template. This template needs input parameters for |
|
|
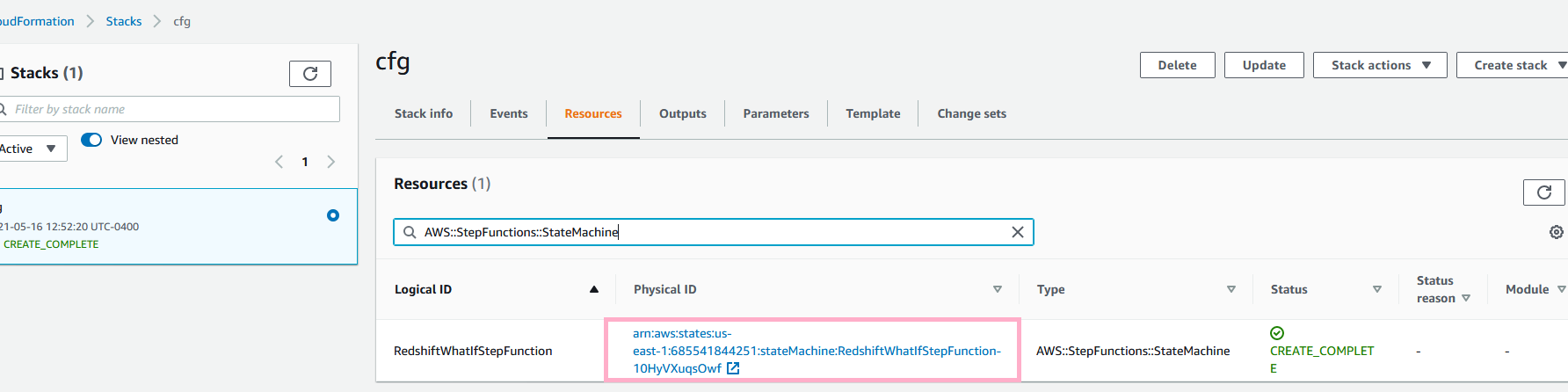
Once deployed, the CloudFormation creates and initiates an AWS Step Functions state machine, that takes care of the end-to-end testing for his workload. |
For your deployed CloudFormation template, navigate to AWS Step Functions state machine will take about 1 hour to complete, plan to run the demo up to this point before hand to avoid wait time. If it fails for any reason, please re-run the state machine by clicking New Execution. Also try to ascertain the reason for failure from the step function logs, which most likely may be resource quota in your account. |
|
|
This state machine would take care of creating the new Redshift clusters based on the node type, count and WLM settings, he mentioned in his initial |
Open the state machine under Step Functions in the AWS console to show the overall workflow |
|
|
This state machine automatically pauses the Redshift clusters after running the workload, as Manhar had set the parameter |
Navigate to Amazon Redshift in AWS Console and resume one of the Redshift clusters created by this test. Wait for the cluster to be in available state (would take close to five minutes) |
|



Analyze Results
| Say | Do | Show |
|---|---|---|
|
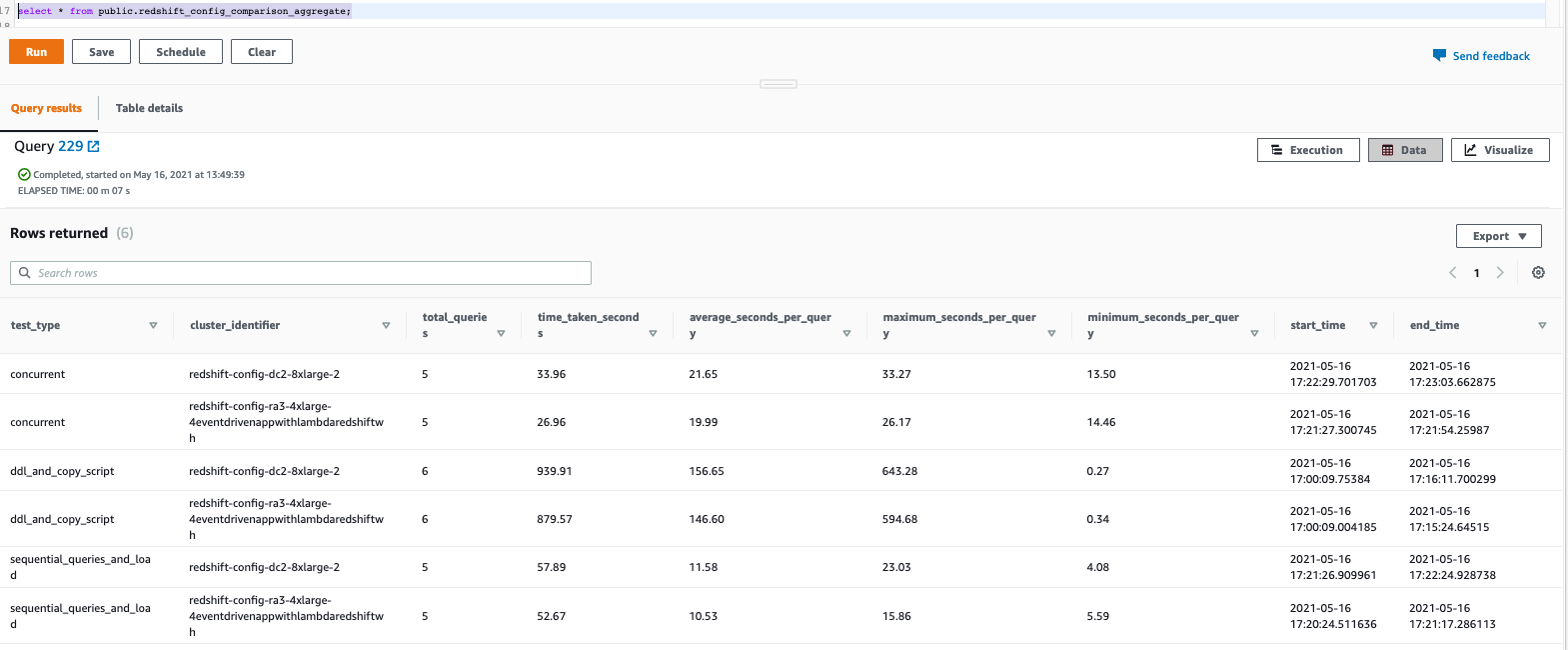
Now Manhar can run below queries to see the final results on how much time it took in each of these Redshift configurations to run his workload. He can verify the test results to compare metrics of different configurations you used in the test.
As shown here, concurrent queries took around 20 seconds on average, the DDL statements took around 900 seconds and the sequential queries took around 11 seconds on average. But the RA3 configuration outperformed DC2 configuration for this test and Manhar may select the RA3 configuration for his production workload based on this testing. |
Navigate to Redshift query editor and connect to the cluster you resumed in above step. Then run below query in that cluster: |
|
|
He may also dive deep into the query level metrics on which query took how much time, but summary information above might be crucial for him to make the final decision on the node configuration for his production workload. |
Run below query in redshift query editor, which gives the detailed level metrics about each query that was run on these clusters. |
|

Before you Leave
If you are done with the demo, please delete the Redshift clusters and then delete the Cloud Formation template, which will clean up all the resources used in this demo.
If you plan to repeat what you did for your customer, then leave your clusters paused to avoid having to pay for unused Redshift clusters.