Manage workloads with Auto WLM
Demo Video

Before you Begin
Ensure you have access to the AWS Console and an existing Redshift cluster with permissions to modify it. Capture the following parameters from the launched CloudFormation template as you will use them in the demo.
https://console.aws.amazon.com/cloudformation/home?region=us-east-1#/stacks?filteringText=&filteringStatus=active&viewNested=true&hideStacks=false
- RedshiftClusterIdentifier
Client Tool
The screenshots for this demo will leverage the the AWS Redshift console. No other client is required for this demo. Some of these steps can be performed using the AWS CLI but the console is still required for other steps.
Challenge
Joe, who is a DBA, has just set up a data warehouse for the marketing team. After reading about workload management documentation, he now wants to make sure that the data warehouse is configured so that critical workloads get higher priority than others. There will be three groups of users using the data warehouse, BI users, ETL users and Data scientists. Of these, the BI users have the highest priority, followed by ETL users and then data scientists. Also, Joe wants to set up a process that dynamically identifies poorly written queries and take action during run time. He also wants to log queries which have longer queue times for further analysis. All BI user ids are prefixed with ‘bi_', the ETL user ids are prefixed with ‘etl_’ and the data scientists are prefixed with ‘ds_'. To accomplish this, Joe will execute the following three steps.
Set up Auto Workload Management with Query Priorities
| Say | Do | Show |
|---|---|---|
| First, let’s go to the Redshift Console |
Navigate to https://console.aws.amazon.com/console/home?region=us-east-1#
Type Redshift in the Find Services search bar and press Enter
|

|
| Now, that we are on the Redshift Console, let us click on Clusters to see a list of Redshift clusters running on the account | Click Clusters on the left panel
|
|
|
Let’s click on the cluster that needs to be modified. This will take you to the page with the cluster details. | Click the demo cluster named <RedshiftClusterIdentifier>
| 
|
|
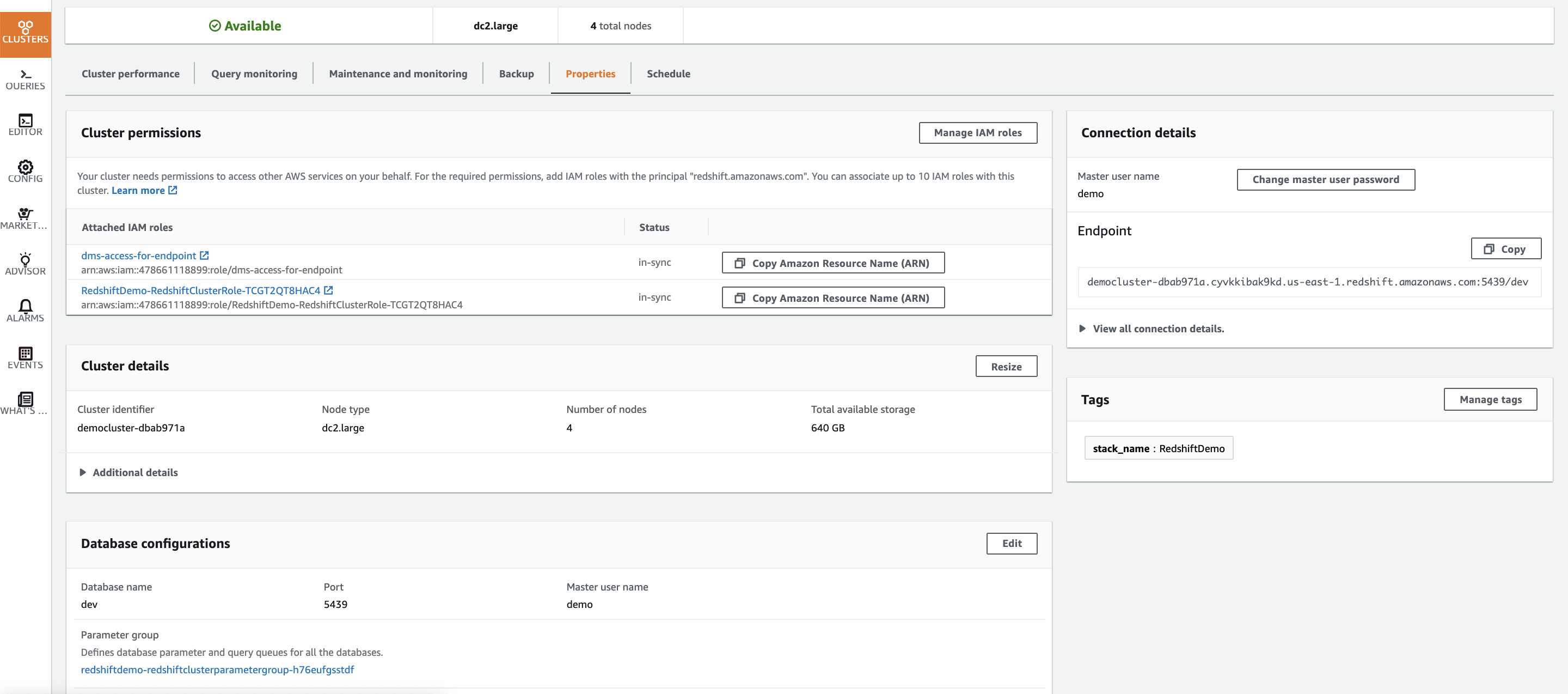
The parameter group attached to your cluster determines the WLM settings for your cluster. You cannot modify the default parameter group. So, if you are using the default parameter group, you will need to create a new parameter group. You can attach the same parameter group to multiple redshift clusters in your account and reuse it. | Switch to the Properties tab and scroll down to the Database Configuration section. Click the parameter group name listed there.
| 
|
|
Let’s create a new parameter group with the required settings. | Click Create to create a new parameter group
| 
|
|
We will now need to enter a name and brief description for the parameter group | Enter demo-parameter-group for the Parameter Group Name.Enter Parameter group for demo in the description. Click the Create button.
| 
|
|
You can see a green banner on the top of the screen confirming the creation of the parameter group. This new parameter group has the default settings for the group. | Click on demo-parameter-group
| 
|
|
You can see that Automatic WLM is the default option and we will keep it that way. You can also see that Short Query Acceleration is enabled by default. This keeps your short running or tactical queries in a separate queue so that they are not waiting on longer, more complex queries to complete. Let us modify the workload queues now. | Click on Edit workload queues
| 
|
|
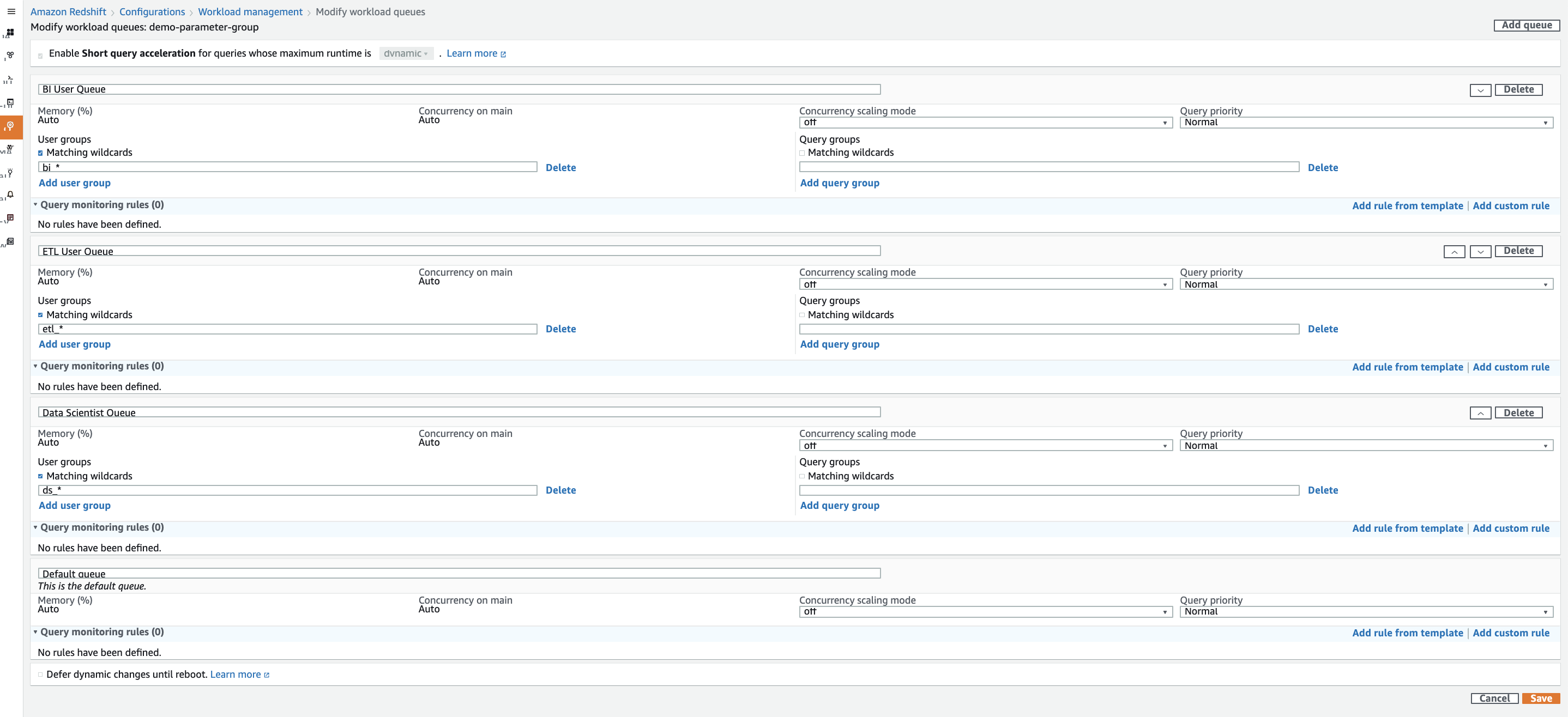
We will create three different queues for the BI, ETL and Data Scientist groups. Since these user groups can be differentiated by the prefix, we can enable ‘Matching wildcards’ and just list the prefix. |
|
|
|
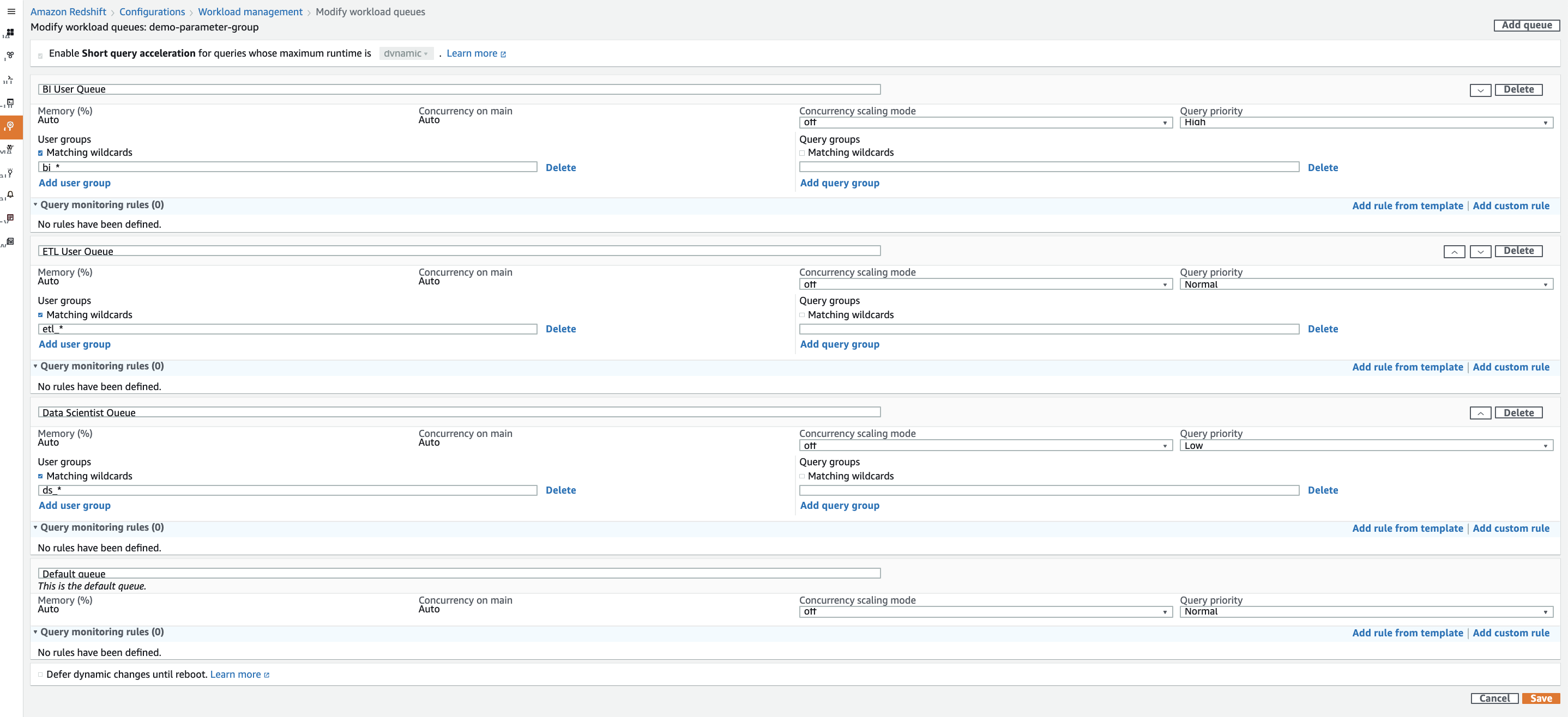
We will now assign priorities to each queue as per the requirements. We will assign a priority of high to the BI user queue, normal to the ETL user queue and low to the data scientist queue. We can do this by choosing the appropriate priority from the dropdown for each individual queue. | 1. Choose a priority of high for the BI user queue2. Choose a priority of normal for the ETL user queue3. Choose a priority of low for the Data Scientist queue
|
|
|
We have now created 3 separate queues for the three workloads and assigned the appropriate priorities to each queue. This will allow Redshift to prioritize queries during run time without manual intervention. | Click on demo-parameter-group
|

|
Set Up Query Monitoring Rules
| Say | Do | Show |
|---|---|---|
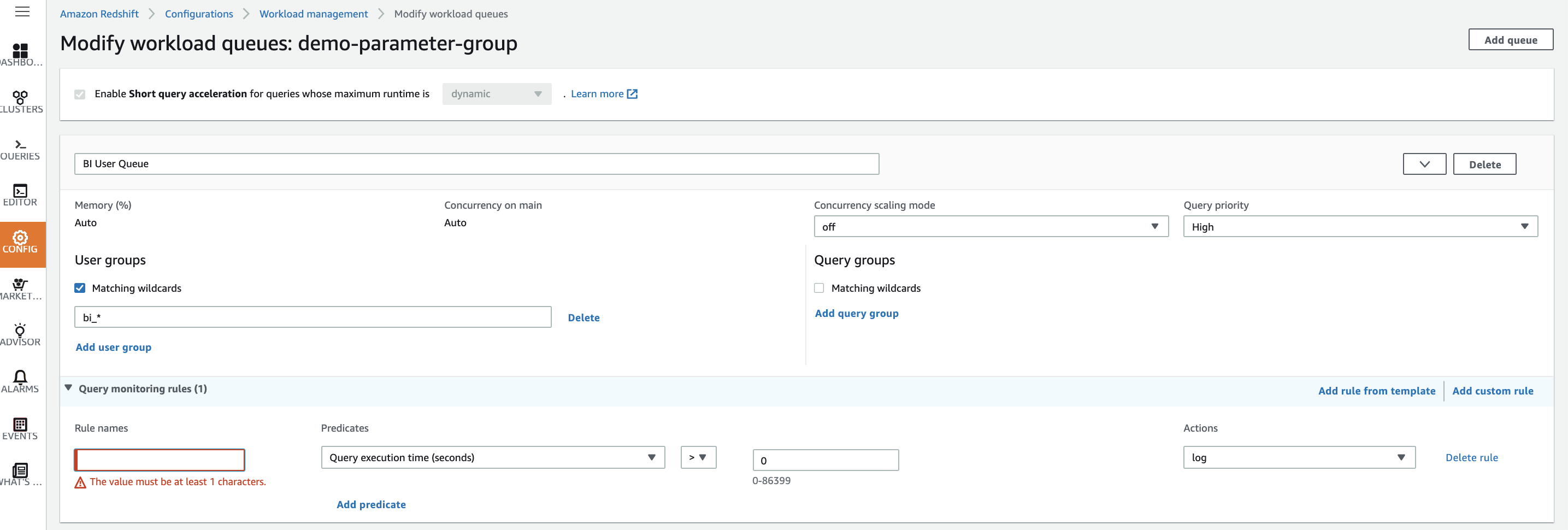
| We will now add some query monitoring rules to the BI queue to dynamically manage workloads during runtime. We will add three rules |
Click on Add custom rule in the Query monitoring rules Section of the BI user queue.
Remember to expand the Query monitoring rules section by clicking the arrow next to it to be able to view the rules you are adding. |
|
| The first one will abort any queries that exceed 1 million for the number of rows in a Cartesian product join. |
|

|
|
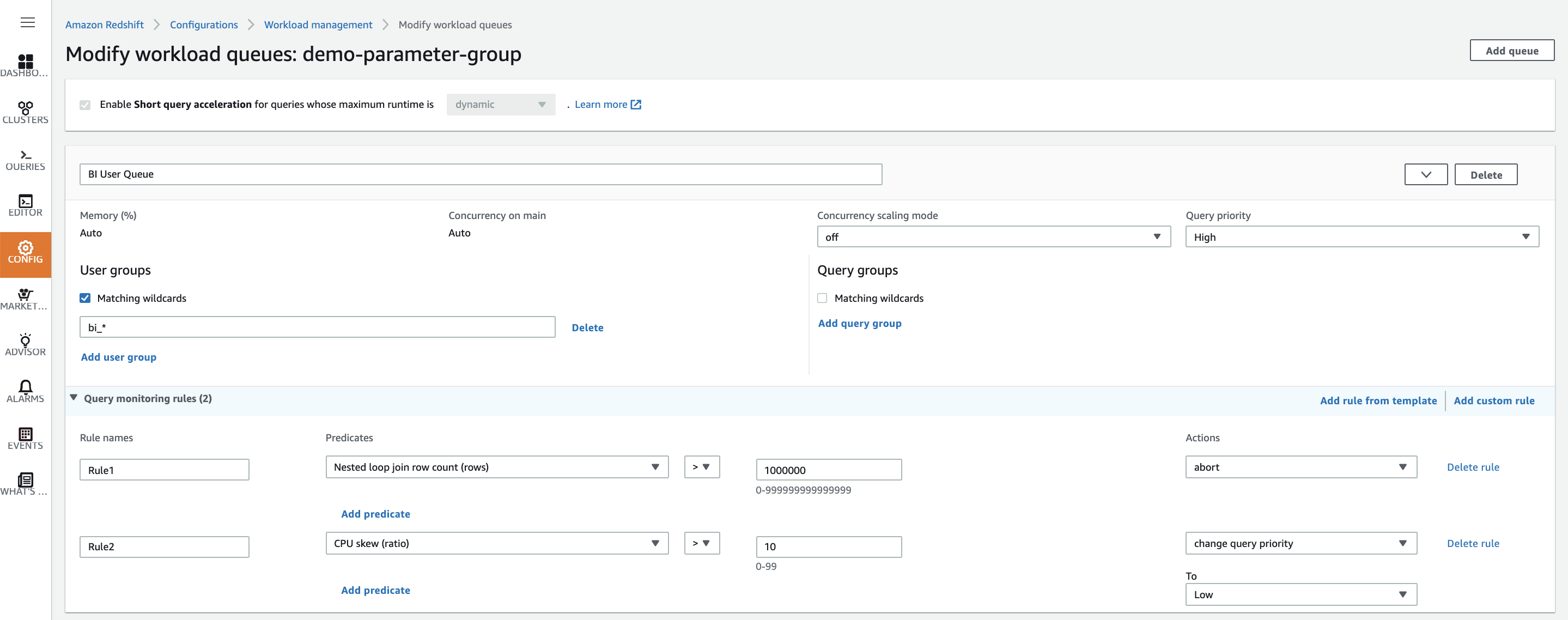
Now, let’s add a second rule which will reduce the priority for any skewed queries in the BI queue. |
| 
|
|
Now, let’s add one more rule which will log any queries that had a queue time of over 30 seconds. |
| 
|
|
Now we can save the changes. With these rules in place, Redshift will automatically take action on any queries in the BI queue which satisfy the conditions specified in the rules without any manual intervention. | Click Save to save the changes.
|

|
Before You Leave
Delete the parameter group that you just created by going to Configurations > Workload management and then clicking the name of the parameter group and then clicking the Delete button.
If you are done using your cluster, please think about deleting the CFN stack or to avoid having to pay for unused resources do these tasks:
- pause your Redshift Cluster
- stop the Oracle database
- stop the DMS task