Loading & querying semi-structured data
Demo Video

Download the PowerPoint presentation
Before You Begin
No parameters required in the demo.
Client Tool
For this demo we will use the Query Editor v2 to connect to the Redshift cluster. Be sure to complete the SQL Client Tool setup before proceeding..
Challenge
Miguel has recently been tasked to analyze a stream of data which is landing in S3 that contains Customer, Order, and Lineitem information for a new POS system. This data is contained in JSON documents and arrives in a real-time stream every few minutes. Most reporting will need to be accurate as of yesterday. That reporting needs to be fast and efficient. In addition, some users may be interested in the data that arrives hourly and a small population will require real-time updates. Miguel passes these requirements to Marie to build an ingestion pipeline. Marie will have to complete these tasks to meet the requirements:
- Load data using COPY - to get a sense of the data and structure without any knowledge of the schema
- Load data using COPY with shredding - to load the data with light/automatic parsing at the top-level
- Un-nest data using PartiQL - to create a dataset that is optimal for BI reporting
- Flatten data using MVs - to build into an ingestion pipeline for incremental processing
- Query current data using Spectrum - to satisfy the requirement for real-time reporting
Load data using COPY
| Say | Do | Show |
|---|---|---|
| First, Marie will create a simple table to load the JSON data into a field with the SUPER type. Using the SUPER type, Marie does not need to worry about the schema or underlying structure. Notice the noshred option which will cause the data to be loaded into one field. |
Amazon Redshift now supports attaching the default IAM role. If you have enabled the default IAM role in your cluster, you can use the default IAM role as follows. |
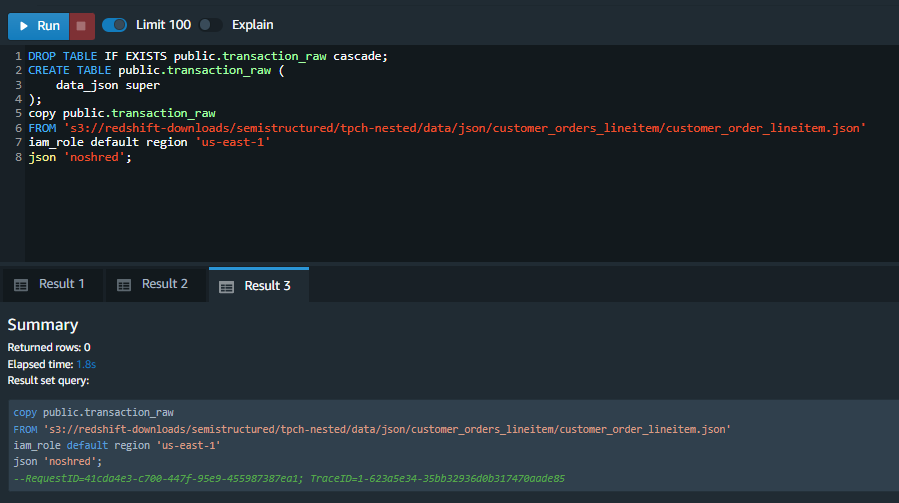
|
Marie can now inspect the data to see what the schema looks like. A simple select will reveal the JSON string. Marie can see that the top-level of the JSON document contains customer attributes c_custkey, c_phone, and c_acctbal. It also contains a nested array with a struct for the c_orders as well as another array with a struct for the o_lineitems of each order.
|
|
|
Now Marie will attempt to use the PartiQL language to parse the top level attributes from the SUPER type field. Marie notices that certain fields have double-quote wrappers. This is because Redshift does not enforce types when querying from a SUPER field. This helps with schema evolution to ensure that if the data type changes over time the load process will not fail. Also note, there are 5 rows returned from this query. While only 5 customers are being represented, there are multiple orders and lineitems as we’ll see when we unnest the data.
|
|
|
| Marie can modify her query to explicitly type-cast the extracted fields so they display correctly. |
|
|
Load data using COPY with shredding
| Say | Do | Show |
|---|---|---|
| Marie decides the first-level of the JOSN document is not likely to change and she would like to have the COPY command parse and load these into separate fields. Marie will replace the no shred option with auto which will cause the data to be loaded in fields which match the column names in the JSON objects. The column mapping will use a case-insensitive match based on the ignorecase keyword. |
Amazon Redshift now supports attaching the default IAM role. If you have enabled the default IAM role in your cluster, you can use the default IAM role as follows. |

|
| Marie can now query this table without having to un-nest the data for the top level attributes. |
|
|
Un-nest data using PartiQL
| Say | Do | Show |
|---|---|---|
Marie now needs to unnest the c_orders which is a complex data structure. Furthermore, the c_orders structure contains another nested field, o_lineitems. Marie will write a query which un-nests the data and determine the count of orders and lineitems. Notice how the main table transaction is aliased by t and to un-nest the data, the t.c_orders is referenced in the FROM clause and aliased by o. Finally, to un-nest the lineitems the o.o_lineitems is also referenced in the FROM clause. Notice how many lineitems are represented in these 5 customer records.
|
|
|
To get a fully un-nested and flattened data set, Marie can reference different fields from the c_orders and o_lineitems structs; taking care to type cast them as appropriate.
|
|
|
Flatten data using MVs
| Say | Do | Show |
|---|---|---|
Marie knows that Miguel and the other analysts will want the best performance when running reports against this data. Rather than expose the transaction table to Miguel and require him to run PartiQL queries to un-nest the data, Marie decides to build a process to un-nest the data for him. She decides to use a Materialized View with incremental refresh. Using this strategy, as new data gets inserted to the table it can be added to the materialized view.
|
|

|
| Let’s get a quick count of the records which are now in the materialized view. |
|
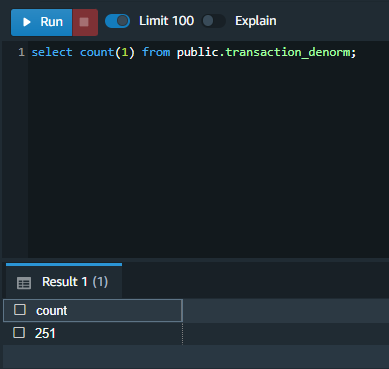
|
Marie wants to test the incremental refresh of the materialized view. To do this, she can run an INSERT statement to load data into the base transaction table. She’ll use the JSON_PARSE function to convert JSON in string form to the SUPER type.
|
|
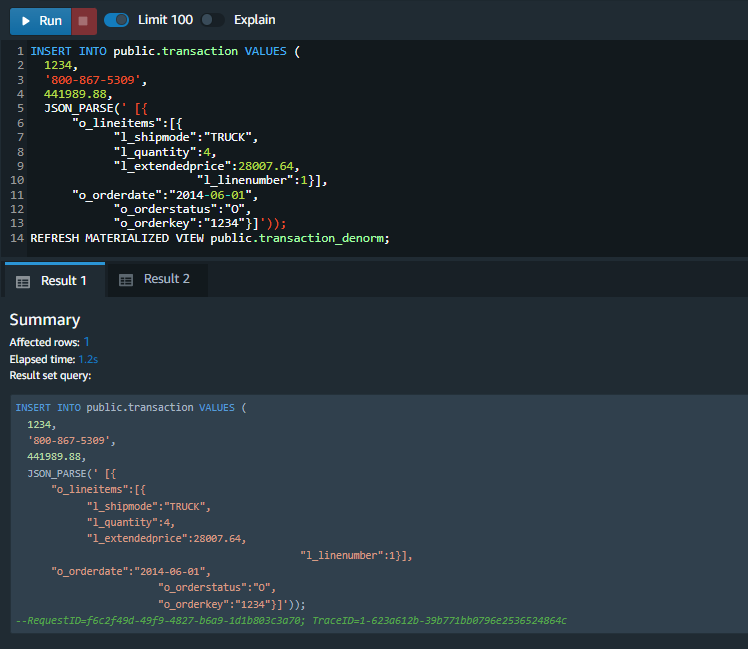
|
Let’s see if the record we just added to our transaction table was inserted into the transaction_denorm through the REFRESH command.
|
|

|
Query data using Spectrum
| Say | Do | Show |
|---|---|---|
| Marie plans to execute the ingestion and the materialized view refresh on a hourly basis to fulfill most reporting requirements. However, some users also want to see the data as it arrives. For this use-case Marie will expose the JSON data using Redshift Spectrum. She will first create the external schema. |
Amazon Redshift now supports attaching the default IAM role.
If you have enabled the default IAM role in your cluster, you can use the default IAM role as follows.
|

|
| Now, Marie can create the external table. Notice that when create an external table the schema for the struct data type must be defined. Compare this to the SUPER data type which does not require a schema to be defined. |
|

|
Marie can create a view which matches the transaction_denorm table, but references the external table which points to the data in S3.
|
|
|
| Finally, let’s inspect the view. |
|
|
Before You Leave
Execute the following to clear out any changes you made during the demo.
DROP VIEW public.transaction_new;
DROP SCHEMA IF EXISTS pos;
DROP MATERIALIZED VIEW IF EXISTS public.transaction_denorm;
DROP TABLE IF EXISTS public.transaction cascade;
DROP TABLE IF EXISTS public.transaction_raw cascade;
If you are done using your cluster, please think about decommissioning it to avoid having to pay for unused resources. For more documentation on ingesting and querying semistructured data in Amazon Redshift refer to the documentation here: https://docs.aws.amazon.com/redshift/latest/dg/super-overview.html