Amazon Redshift Multi-AZ(Preview)
Feature Overview
Amazon Redshift now supports Multi-AZ deployments that enables running data warehouse in multiple AWS Availability Zones (AZ) simultaneously offering fault tolerance. A Multi-AZ deployment is intended for customers with business critical analytics applications that require the highest levels of availability and resiliency to AZ failures. Multi-AZ deployment for Amazon Redshift RA3 clusters is available in Preview.
Prerequisites:
This feature is in preview. So you need to create a provisioned cluster with a preview track “preview_2022” following the instructions below.
https://docs.aws.amazon.com/redshift/latest/mgmt/working-with-clusters.html#working-with-clusters-overview
Blog
Here is the blog with detailed instructions.
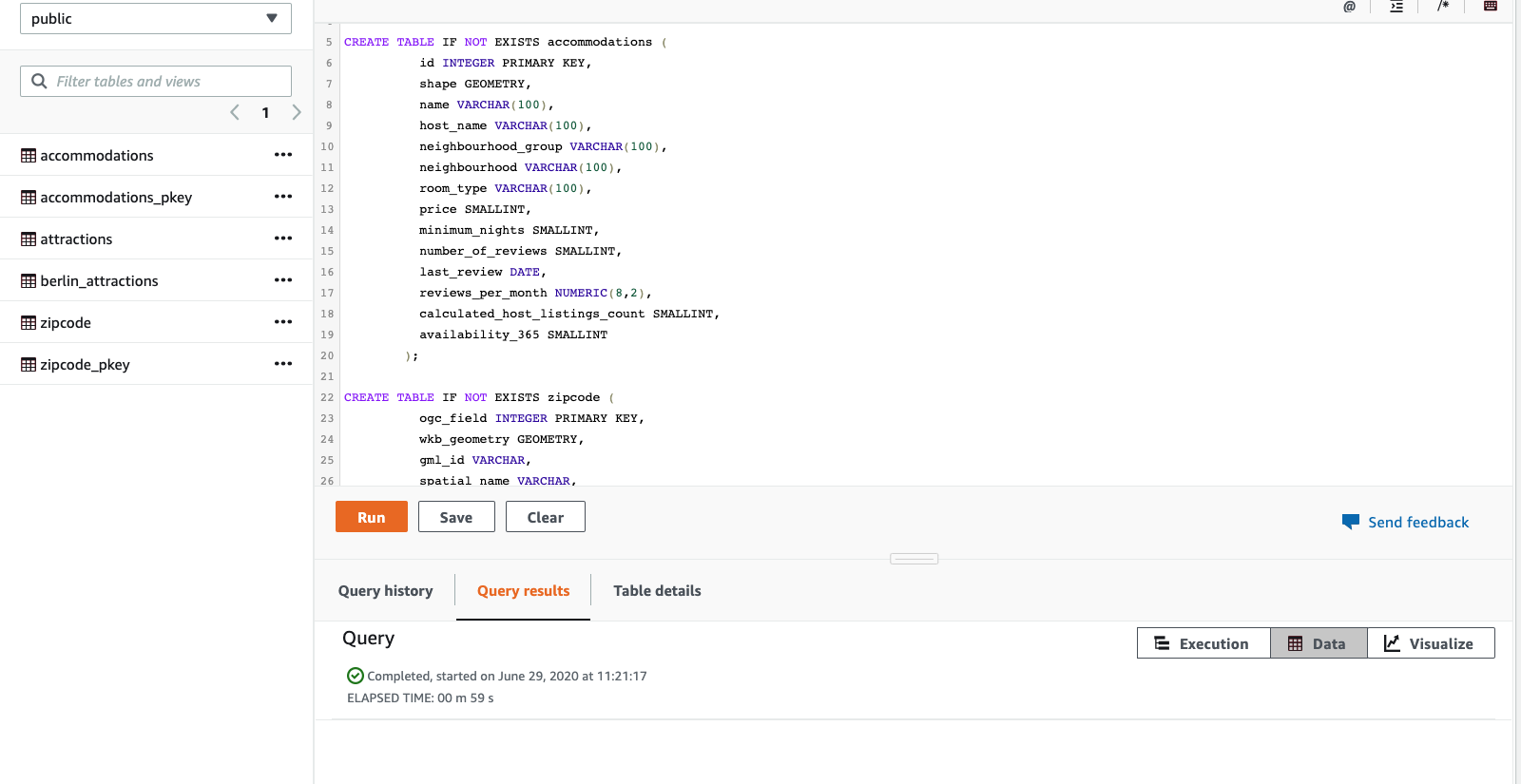
Create tables
| Say | Do | Show | |
We create a preview cluster for multi-AZ deployments through Amazon Redshift console. Amazon Redshift will deploy the same number of nodes in each of the two Availability Zones for a Multi-AZ deployment. All nodes of a multi-AZ deployment can perform read and write workload processing during normal operation.
|
- On the Amazon Redshift console, in the navigation pane, choose Clusters.
- A banner displays on the Clusters list page that introduces preview mode. Choose the button Create preview cluster to open the create cluster page.
- For Preview track, choose preview_2022.
- Provide a name for the cluster labeled as -preview that indicates that it is on a preview track.
- Choose one of the RA3 node types on the Node type drop-down menu.
- For Multi-AZ deployment, select Yes.
- For Number of nodes per AZ, enter the number of nodes that you need for your cluster.
|
|
|
Let us provide the user credentials for the database and additional configuration such as VPC and security groups.
|
- Under the Database configurations, choose Admin user name and Admin user password.
- Turn Use defaults on next to Additional configurations to modify the default settings.
- Under Network and security,choose the VPC you want to deploy the cluster in.
- For VPC security groups, either leave as default or add the security groups of your choice.
- For Cluster subnet group, either leave as default or add a cluster subnet group of your choice.
|
|
|
Let us now provide database encryption settings.
|
- Under Database configuration, for Database port, you either use the default value 5439 or choose a value from the range of 5431–5455 and 8191–8215.
- In the Database encryption section, to use a custom AWS Key Management Service (AWS KMS) key other than the default KMS key, choose Customize encryption settings. This option is deselected by default.
- Under Choose an AWS KMS key, you can either choose an existing KMS key, or choose Create an AWS KMS key to create a new KMS key.
- Choose Create Cluster once all the above settings are complete.
|
|
|
Once the cluster creation is successful, under General Information you can see Multi-AZ as Yes and under Network and security settings you can find the details of the primary and secondary availability zones.
|
|
|
|
It is possible to convert an existing Single-AZ deployment to a Multi-AZ deployment, you can restore from a snapshot to configure it into a Multi-AZ data warehouse. When migrating to a Multi-AZ deployment from an existing Single-AZ deployment, maintaining performance of a single query may require the same number of nodes used in the current Single-AZ deployment to be provisioned in both Availability Zones, resulting in doubling the amount of cluster nodes needed when migrating to Multi-AZ to ensure that single query performance is maintained.
|
- On the Amazon Redshift console, in the navigation pane under Clusters, choose Snapshots.Select the snapshot to use.
- The snapshot needs to be encrypted in order to restore to a Multi-AZ deployment.
- On the Restore snapshot menu, choose Restore to provisioned cluster.
|
|
|
Let us now choose the node type and the Multi-AZ deployment options.
|
- Choose the Preview mode.For Preview track, choose preview_2022
- Enter a name for the cluster labeled as -preview that indicates that it is on a preview track.
- Make sure that you choose one of the RA3 node types on the Node type drop-down menu.
- For Multi-AZ deployment, select Yes.
- For Number of nodes per AZ, enter the number of nodes that you need for your cluster.
|
|
|
Now we will setup the additional configurations for network and security.
|
- Go to Additional configurations, expand Network and security, make sure that you either accept the default for Cluster subnet group or choose another one of your choice. For a Multi-AZ deployment, a cluster subnet group must include one subnet each from at least three or more different Availability Zones.
- Under Additional configurations, expand Database configurations.Under Database encryption, to use a custom KMS key other than the default KMS key, choose Customize encryption settings. This option is deselected by default.
- Under Choose an AWS KMS key, you can either choose a KMS key or enter an ARN. Or, you can choose Create an AWS Key Management Service key to create a key.
|
|
|
Let us check the new cluster once it is restored from snapshot.
|
Choose Restore cluster from snapshot.
|
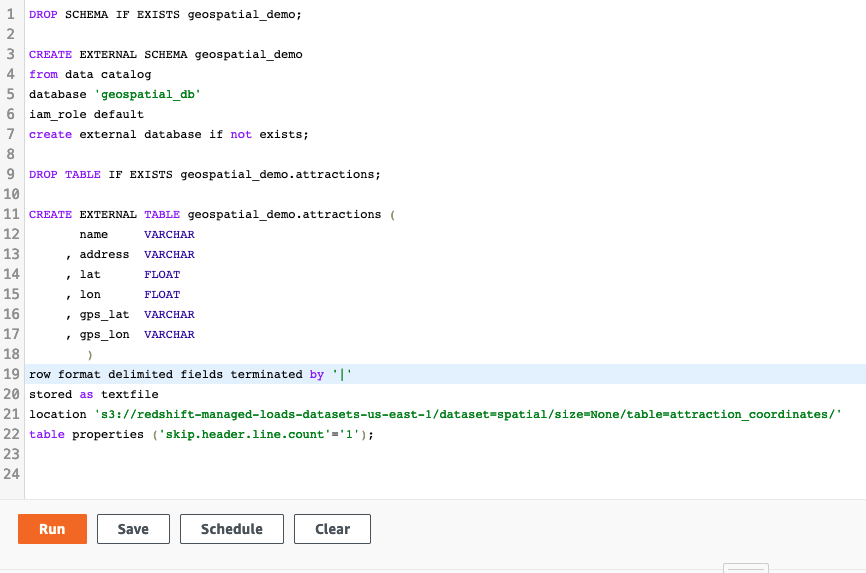
Test Fault Tolerance of Redshift Multi-AZ deployment
| Say | Do | Show | |
Let us test the fault tolerance by injecting failure.
|
- On the Amazon Redshift console, choose Clusters in the navigation pane.
- Navigate to the cluster detail page and on the Actions menu, choose Inject Failure (Public Preview).
- Choose Confirm.
|
|
|
|
After the cluster become Available we can check the primary and secondary Availability Zones.
|
Go to the Network and Security settings to check the Availability Zones.
|
|
|
Now let us monitor the query run on Multi-AZ deployment from the Amazon Redshift Console.
|
- On the Amazon Redshift console, connect to the database in your Multi-AZ deployment and run queries through the query editor.
- Run a sample query as below on the Multi-AZ Redshift deployment.
SELECT compute_type) as compute_type, left(query_text, 50) query_text from sys_query_history order by start_time desc;
- For a Multi-AZ deployment, you can identify a query and the Availability Zone where it is being run (running on the primary cluster or secondary availability zone) by using Query the compute_type column in the SYS_QUERY_HISTORY table to identify the query and the Availability Zone where it is being run.
|
|
|
Let us access the query history from the console to analyze the query diagnostics.
|
On the Query monitoring tab, choose Connect to database.
|
|
|
Let us connect to the database using the credentials.
|
- For Authentication, choose Temporary credentials.
- Enter a database name (for example, dev).
- Enter the database user name (for example, awsuser).
- Choose Connect.
|
|
|
The database is connected now, let us check the query history to see all queries and loads.
|
Under Query Monitoring go to the Query history tab.
|
|
|
We will now use the metric filters to view query history based on Time interval, Users, Databases, or SQL commands.
|
Under Metric filters, use the various filters in the Additional filtering options section to view query history based on Time interval, Users, Databases, or SQL commands.
|
|
Before you Leave
If you are done using your cluster,pause/terminate the Redshift cluster to avoid having to pay for unused resources.